


As XML becomes more and more prolific in the world of data exchange it's increasingly important that data can be quickly and easily extracted from XML documents and moved into more permanent data stores.
Although .NET offers several different ways for performing this task, the XmlTextReader represents the most efficient and scalable solution.
Moving XML into Northwind's Customers Table with the XmlTextReader
Let's examine a situation where an XML document with complex hierarchical relationships needs to be parsed so that the data it contains can be moved into the Northwind database's Customers table. If you're not familiar with the Northwind database, it is a sample database that ships with several Microsoft products including SQL Server and Access. The custom class that will be shown uses the XmlTextReader to parse data from an XML document named customers.xml and create insert statements that can be executed against the database.
Using the
XmlTextReader,large XML documents can be parsed without imposing large memory requirements on servers.
If you're not familiar with the Customer's table structure, Figure 1 shows the fields and data types that it contains.
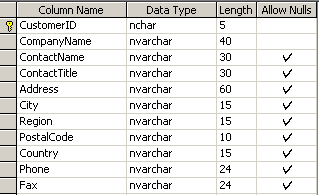
Looking at the design of this table you can see that the only essential fields are CustomerID and CompanyName. All other fields can accept Null values. This is important to understand as the XML document is parsed and the SQL statement is dynamically created.
The XML Document
The source XML document that will be parsed by the custom class contains a mix of elements and attributes all nested at different levels in the document. A few levels of nesting were added to show that the structure of the XML document doesn't really matter when using the XmlTextReader. Flat or deeply nested documents can parsed just as easily.
One customer record from the customers.xml XML document is shown in Listing 1.
Listing 1: The Source XML Document - Customers.xml
<?xml version="1.0" ?>
<customerData>
<customer id="WID10">
<companyInfo>
<nameInfo>
<companyName>Widgets Inc.</companyName>
<contactName name="John Doe" title="President" />
</nameInfo>
<companyDetails>
<address street="1234 Anywhere" city="Pinetop"
state="AZ" zip="85244" country="USA" />
<phone>
<busPhone busLine="520 123-1234"
mobile="520 123-1238" />
<busFax busLine="520 123-1235" />
</phone>
</companyDetails>
</companyInfo>
</customer>
</customerData>
You'll notice that while some of the data is contained in text nodes, the majority of it is located in attributes. As long as the structure of the document is known either from seeing the document or by reading a schema, the location of the data within the document doesn't necessarily matter as the XmlTextReader can access any node.
The SQLGenerator Class
The class that takes care of parsing the XML document shown in Listing 1 and generating the proper SQL statements is named SQLGenerator. Listing 2 shows the shell structure of the class, which is written in C# and contained within a namespace named *XmlTextReaderDB.Component*.
Listing 2: The SQLGenerator Class
using System;
using System.Xml;
using System.Text;
using System.Collections;
namespace XmlTextReaderDB.Component {
public class SQLGenerator {
public SQLInfo CreateSQLStatement(string xmlPath){
}
private string AddSeparator(Hashtable fv,
char sep) {
}
}
}
Looking at the code, you can see that several namespaces are referenced, including:
System;
System.Xml;
System.Text;
System.Collections;
The System.Xml class contains the *XmlTextReader* class used to parse the XML. The System.Text and System.Collections namespaces contain classes such as *StringBuilder* and Hashtable that are used to store the dynamically created SQL statements. You'll see how these different classes are used a little later.
Looking at the return type of the *GenerateSQLStatement()* method shown in Listing 2, you'll see that it returns a custom object named SQLInfo. SQLInfo is a simple struct that has three different property Get and Set accessors as shown in Listing 3. It is used to store the status of the parsing process, any error messages and the generated SQL statements.
Listing 3: The SQLInfo Struct
public struct SQLInfo {
int _status;
string _statusMessage;
string _sql;
public int Status {
get {
return _status;
}
set {
_status = value;
}
}
public string StatusMessage {
get {
return _statusMessage;
}
set {
_statusMessage = value;
}
}
public string SQL {
get {
return _sql;
}
set {
_sql = value;
}
}
}
Now that you've seen the structure of the SQLGenerator class, let's fill in the blanks with some code!
Starting the Parsing Process
Once the SQLGenerator class is instantiated, its *GenerateSQLStatement()* method is called and the path to the source XML document is passed as an argument. When the method is invoked, several local variables are instantiated as shown below:
XmlTextReader reader = null;
Hashtable fieldNamesValues = new Hashtable();
StringBuilder sqlStatements =
new StringBuilder();
bool error = false;
//Create Return Object
SQLInfo sqlInfo = new SQLInfo();
Aside from the XmlTextReader object, a *HashTable* object named *fieldNamesValues* is used to hold the different database field names and values found during the parsing process. This name/value combination will be used to construct one or more SQL statements to be executed against the database. In situations where more than one SQL statement is created due to the XML document containing multiple records (a likely scenario in the “real” world), the statements will be placed into a *StringBuilder* object named sqlStatements. The *StringBuilder* offers a superior mechanism, in terms of performance, over manually concatenating strings together.
Because the XML document may contain more than one customer record, a check needs to be made to see when each customer element ends so that a new SQL INSERT statement can be started for the next customer.
After the variables are created, a try/catch block is started that will encapsulate the entire parsing process. This is important because, if the XML document is not well-formed or the path passed into GenerateSQLStatement() is invalid, the resulting error can be caught and the SQLInfo struct shown earlier can be updated appropriately with the error information and sent back to the caller of the SQLGenerator class.
Within the try/catch block, the *XmlTextReader* class is instantiated by passing the XML document path into its constructor. If the XML document path is valid, the parsing process starts by calling the *Read()* method within a while block. The *Read()* method returns a Boolean value based on whether or not the stream contains more XML “tokens” to be read:
reader = new XmlTextReader(xmlPath);
//Read through the XML stream and find tokens
while (reader.Read()) {
}
Each XML “token” found in the stream can be examined one at a time. Since the only desirable node types (those containing data) are elements, unwanted nodes such as processing instructions and white space can easily be filtered out and ignored by checking the current token's node type. This is accomplished by using the *XmlTextReader's NodeType* property and comparing the value against the XmlNodeType enumeration (see the “XmlNodeType Enumeration Members” sidebar for a list of members):
if (reader.NodeType == XmlNodeType.Element) {
//Only elements are desirable
}
Now that only elements will be pulled from the stream, the names of the elements can be checked and any associated text or attribute values can be accessed. The *XmlTextReader's Name* property is used to access the current token's name. The element names that the *GenerateSQLStatements()* method is interested in are added as case statements:
switch (reader.Name.ToLower()) {
case "customer":
break;
case "companyname":
break;
case "contactname":
break;
case "address":
break;
case "busphone":
break;
case "busfax":
break;
}
These elements contain the data (either in attribute or text nodes) that should be used to construct the SQL INSERT statements.
Within each case statement, code is added to extract the desired value from text and/or attribute nodes and add it into the *fieldNamesValues Hashtable*. Listing 4 shows how to get the value of the customer element's *id* attribute (
Listing 4: Using the XmlTextReader to Access Attributes
case "customer":
if (reader.HasAttributes) {
string customerID = reader.GetAttribute("id");
if (customerID != String.Empty) {
fieldNamesValues.Add("CustomerID","'" +
customerID + "'");
} else {
sqlInfo.Status = 1;
sqlInfo.StatusMessage = "ID attribute " +
"empty on customer element";
sqlInfo.SQL = null;
error = true;
}
} else {
sqlInfo.Status = 1;
sqlInfo.StatusMessage = "No attributes on " +
"customer element";
sqlInfo.SQL = null;
error = true;
}
break;
The code in Listing 4 first checks to see if the customer element has any attributes. If it does not, the SQLInfo object's properties are updated accordingly and a flag variable named error is set to true so that parsing does not continue. Why stop the parsing? Earlier you saw that the CustomerID field in the Customers table did not accept NULL values. Although an empty string could be inserted, this field is the primary key so it's important that a valid value be added. With minimal effort, the code could be changed to simply ignore this customer record, log it to an error file, and continue processing any other records.
Once the SQLGenerator class is instantiated, its
GenerateSQLStatement()method can be called and the path to the source XML document is passed as an argument.
If the customer element does have attributes, the *id* attribute value is accessed by using the *GetAttribute()* method. The returned value is checked and, if it is not empty, the *fieldNamesValues Hashtable* is updated with the proper database field name and value to be inserted. The process of checking node names continues as the XmlTextReader parses the XML document and each XML token containing a value that should be inserted into the Customers table is added into the Hashtable.
Handling Multiple Records
Because the XML document may contain more than one customer record, a check needs to be made to see when each customer element ends so that a new SQL INSERT statement can be started for the next customer. This check is done by comparing all tokens found in the stream with the XmlNodeType enumeration mentioned earlier. Specifically, the code checks to see when an EndElement node type is found as shown in Listing 5.
Listing 5: Checking for the end of a customer record and generating the SQL statement
if (reader.NodeType == XmlNodeType.EndElement) {
if (reader.Name.ToLower() == "customer") {
string[] FVArray =
AddSeparator(fieldNamesValues,',');
string fields = FVArray[0];
string fieldVals = FVArray[1];
sqlStatements.Append("INSERT INTO Customers (" +
fields + ") VALUES (" + fieldVals + ");");
//Clear out Hashtable to handle multiple records
fieldNamesValues.Clear();
}
}
//...Further down in the GenerateSQL class
private string[] AddSeparator(Hashtable fv,char sep) {
int len = fv.Count;
int i = 0;
StringBuilder sbFields = new StringBuilder();
StringBuilder sbValues = new StringBuilder();
IDictionaryEnumerator fvEnum = fv.GetEnumerator();
while (fvEnum.MoveNext()) {
sbFields.Append(fvEnum.Key);
if (i < len -1) sbFields.Append(sep);
sbValues.Append(fvEnum.Value);
if (i < len -1) sbValues.Append(sep);
i++;
}
string[] output =
(sbFields.ToString(),sbValues.ToString()};
return output;
}
In situations where more than one SQL statement is created due to the XML document containing multiple records (a likely scenario in the “real” world), the statements will be placed into a
StringBuilderobject namedsqlStatements.
If the end element's name is customer, the current customer's record has ended and the SQL statement can be created for that record. This is accomplished by passing the *fieldNamesValues* variable into the AddSeparator() method, which enumerates through the Hashtable's name/value pairs and adds a comma between all of the names and values. The field names and values (with the commas added) are then returned in an array and used to dynamically create the SQL INSERT statement. The SQL statement is then added into the sqlStatements StringBuilder object. Since multiple statements can be added into this object, each statement ends with a semi-colon character so that SQL Server can execute all the statements as a batch.
If no errors were encountered during the parsing process, the SQLInfo object's properties are updated and returned to the calling application where the SQL INSERT statement(s) can then be executed against the database:
if (!error) {
sqlInfo.Status = 0;
sqlInfo.StatusMessage = String.Empty;
sqlInfo.SQL = sqlStatements.ToString();
}
Using the GenerateSQL Class
The code to instantiate and use the GenerateSQL class to parse the customers XML document and update the Northwind database is shown in Listing 6. To use the class, you must reference the *XmlTextReaderDB.Component* namespace. Although this shows how an ASP.NET page can call the class, it could be called from an NT service, client-server app, or even a Web Service, if needed.
Listing 6: Instantiating the GenerateSQL Class
private void Page_Load(object sender,System.EventArgs e){
string xmlPath = Server.MapPath("customers.xml");
SQLGenerator sqlGenerator = new SQLGenerator();
SQLInfo sqlInfo =
sqlGenerator.CreateSQLStatement(xmlPath);
if (sqlInfo.Status == 0) {
Response.Write("<b>SQL Output:</b><p />" +
sqlInfo.SQL + "<p />");
//Execute the SQL statement
SqlConnection dataConn = null;
try {
string connStr =
ConfigurationSettings.AppSettings["dsn"];
dataConn = new SqlConnection(connStr);
SqlCommand cmd =
new SqlCommand(sqlInfo.SQL,dataConn);
dataConn.Open();
cmd.ExecuteNonQuery();
Response.Write("<b>Database updated!</b>");
}
catch (Exception exp) {
Response.Write("<b>Error: </b>" +
exp.Message);
}
finally {
dataConn.Close();
}
} else {
Response.Write("<b>Error Occurred:</b><p />" +
sqlInfo.StatusMessage);
}
}
Different custom classes can be created to handle different XML documents. This allows the bulk of the work to be encapsulated with the class, which can be instantiated and used with only a minimal amount of code by a variety of applications.
Conclusion
There are many different ways that XML can be moved into a database using the .NET platform. This solution shows how any XML document can be parsed quickly and efficiently using the XmlTextReader class. Because the XmlTextReader is non-memory intensive, it presents an excellent mechanism for parsing large XML documents without imposing huge memory requirements on servers.
