


In the last Baker's Dozen article, I demonstrated 13 SSIS packages to show what Integration Services can do. This article picks up where the last one left off. I'll show some capabilities in SSIS, such as handling irregular input files, extracting database changes, implementing package configurations, and leveraging the advanced lookup features in SSIS 2008.
What's on the Menu?
When I began this two-part article, my goal was to show as much SSIS 2008 functionality as possible. Here are the 13 items on the menu for this article:
- The Baker's Dozen Spotlight: Handling irregular/complex input files
- Advanced uses of the SSIS 2008 Lookup task
- Change Data Capture (CDC) in SQL Server 2008
- Change Data Capture and DDL changes
- Handling XML files inside SSIS packages
- SSIS control flow scripts
- SSIS data flow scripts
- Extracting SharePoint lists in SSIS
- Data conversions potpourri
- SSIS parent-child package configurations
- Handling Type 2 slowly changing dimensions (retaining historical attributes)
- SSIS package logging
- Calling SSIS packages from .NET
Tip #1: The Baker's Dozen Spotlight: Handling Irregular/Complex Input Files
*Scenario: I want to process an input file that contains several formats (see below). Record Type A indicates basic order header information, Record Type B indicates order line items (Order, Product, Quantity, and Price), and Record Type C indicates a note for the order.*
A,0001,5-12-2008,50
B,0001,ProductA, 5, 25
B,0001,ProductB, 10, 20
B,0001,ProductC, 15, 10
C,0001,Note for Order 0001, 5-13-2008
A,0002,6-12-2008,65.70
B,0002,ProductC, 6, 10
B,0002,ProductD, 11, 27.50
A,0003,7-12-2008,75.11
B,0003,ProductC, 16, 10
C,0003,Note for Order 0003, 7-13-2008
This is a common question on SSIS technical forums. Fortunately, there are multiple ways to tackle this. In this first tip, I'll show how to handle the file with a conditional split. In Tip #7, I'll show how to accomplish this with a data flow script component.
Figure 1 shows the SSIS package I'll demonstrate, step by step.
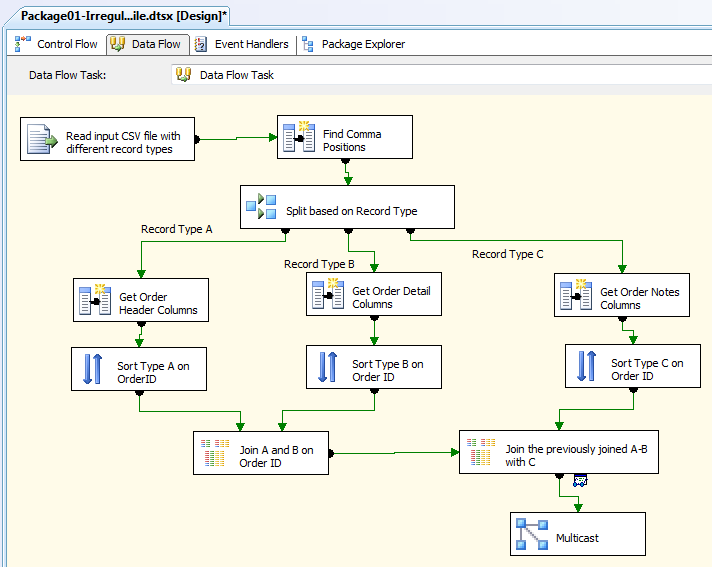
Step 1: In the Data Flow area, I opened the input file (IrregularInput.CSV, in the InputFiles subfolder), using a Flat File Source. I also made one important change to the Flat File default options: on the Columns Page, I set the Column Delimited to nothing (Figure 2). Essentially, I'm going to find the comma positions manually since the input file has a different number of commas per format line. Right now, each input row is just one long column, where the first character represents the input row type (“A” for header, etc.).
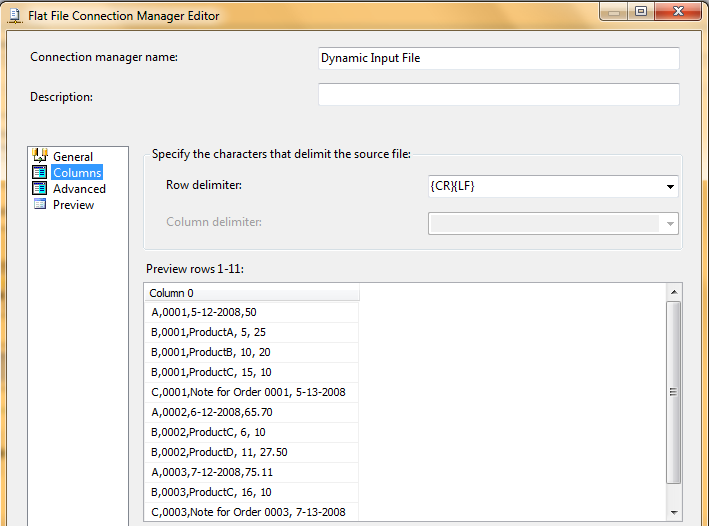
Note: When SSIS reads the input file, it might generate an error message that the “last row in the sampled data is incomplete.” This error occurs because SSIS validates the first few hundred rows. If this error occurs, the workaround is to set the Header Rows to skip setting in the Flat File Connection Manger to a value of 1.
Step 2: Next, I brought in a derived column transformation to create new columns in the pipeline that represent the comma positions for each input row (Figure 3). Each new derived column uses the SSIS FindString function to locate the position of each comma within the input row. Eventually I'll use these comma position values to extract the actual column values. (Remember that the comma positions can and will vary on a row-by-row basis.)
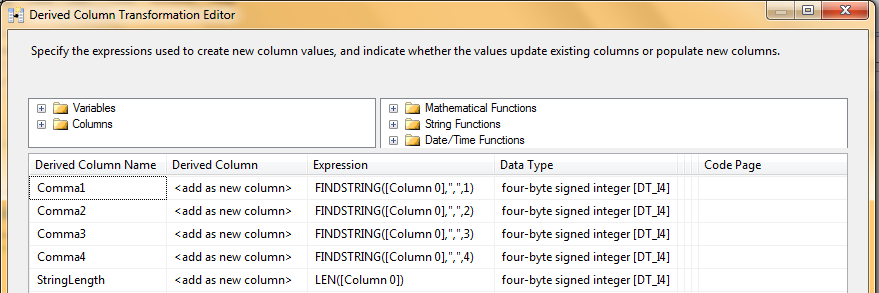
There is only one stipulation with this approach: I must create four comma position columns because the maximum number of commas in any one input row is four. I must also create a column value (StringLength) to store the length of each row.
Step 3: The next step will split the single input pipeline into three output pipelines (one for each of the three record types) using a conditional split. Note that I've used the SUBSTRING function in SSIS to read the first character of the input row.
Output Name Condition
Record Type A SUBSTRING([Column 0],1,1) == "A"
Record Type B SUBSTRING([Column 0],1,1) == "B"
Record Type C SUBSTRING([Column 0],1,1) == "C"
Step 4: Note in Figure 1 that I created three derived column transformations from the three split outputs from the previous step. In these three derived column transformations (which I named “Get Order Header Columns”, etc.) I'll extract the appropriate columns from each of the three input pipelines (in Figures 4, 5, and 6).



Note that in the three derived column transformations I'm using SUBSTRING with the comma position columns to extract the important columns (OrderID, OrderDate, Product, Qty, etc.). Additionally, I'm casting the extracted value (using the built-in SSIS Type Cast expressions) to the correct data type. For instance, I'm using DT_CY to cast an extracted string as currency, DT_DATE to cast an extracted string as a date, DT_I4 to cast as a four-byte signed integer, etc.
At this point, now that I have three separate pipelines, I could go one of several directions. I could write out the three pipelines to three separate tables. Additionally, I could join the three pipelines back together, based on a common column (OrderID). Note at the bottom of Figure 1, I've used the Merge Join transformation to join the pipelines for Type A and Type B rows (Order Header and Order Details), and then a second Merge Join transformation to join the “joined” pipeline with Type C rows (Order Notes). I needed to use two Merge Join transformations because each single Merge Join will only work with two tables.
(Also, before I used the Merge Join, I needed to sort all three pipelines on the OrderID column: the Merge Join requires sorted input.)
Tip 2: Performing Lookup Tasks on Large Tables
The lookup task is arguably one of the most common data flow transformations in SSIS. I hesitate to say “popular” because many developers have experienced love-hate relationships with the lookup task and its performance. Some developers have reported that lookup jobs involving hundreds of millions of rows wind up taking hours to run.
Microsoft made significant enhancements to the Lookup Transformation in SSIS 2008. One of the enhancements is that SSIS loads the lookup cache must faster. To test this, I created a table with 27 million rows: certainly not the largest database in the world, but not a tiny one either. Then I took 25% of the rows (by using the SSIS Percent Sampling transformation) to create a text file of roughly 6.8 million rows.
Finally, I wanted to take the text file of 6.8 million rows and perform a lookup BACK INTO the database table of 27 million rows; additionally, I wanted to run this test in both SSIS 2005 and SSIS 2008 to see the difference in performance. The SSIS 2008 package took 35 seconds (and that's the total elapsed time for SSIS to cache the 6.8 million rows and perform the lookup on 6.8 million rows. The SSIS 2005 package took 60 seconds. (This was an informal benchmark: actual mileage may vary. The point is that much of the performance boost comes from faster cache loading.)
Faster cache loading is only one of the Lookup enhancements in SSIS 2008. There are many websites that talk about these enhancements: one of the best I've seen is at Altius Consulting (<a href="http://www.altiusconsulting.com">http://www.altiusconsulting.com). On their site, in the community blog section, there is a very good entry on these enhancements (the September 16th, 2008 entry). In a nutshell, here are the new enhancements:
Unlike SSIS 2005, which required an OLE DB data source, you can now perform lookups into a flat file source.
SSIS 2005 restricted a lookup cache to 3 GB. SSIS 2008 breaks that limit.
In SSIS 2008, a developer can take retrieved lookup data and cache the data for subsequent lookups. The developer can even write the cached lookup data to desk (with a CAW extension) and even deploy this CAW file to different targets.
Finally, always remember this: the lookup source column(s) and lookup target column(s) must always be the same data type! A common beginner mistake is to lookup into a Unicode column based on a non-Unicode value. The lookup will only work on identical column types!
Tip 3: Using Change Data Capture in SQL Server 2008
Scenario: You are implementing a new database system and you are required to implement audit trail processing. The system must log all changes to data. You've heard of Change Data Capture in SQL 2008, and would like to know more about it.
A new feature in the SQL Server 2008 database engine is Change Data Capture. (Many sites use the acronym CDC, not to be confused with the Centers for Disease Control!) CDC captures insert/update/delete activity, thus the name “Change Capture” into database logs. For many years, SQL Server developers had to write database triggers to implement audit trail logging. That raises the question - does CDC replace database triggers for logging database changes? I'll address that question at the end.
I'd like to go through the basics of CDC by creating a small database, inserting and updating and deleting data, and then retrieving data from the CDC log tables.
First, I need to create a new sample database and then configure the database for CDC, using the system stored procedure sys.sp_cdc_enable_db.
CREATE DATABASE CDCTest2
GO
USE CDCTest
GO
-- enable Change Data Capture on Current database
exec sys.sp_cdc_enable_db
Second, I'll create a sample table and I'll tell CDC to log all the columns in the table by using the system stored procedure sys.sp_cdc_enable_table. Note that CDC uses SQL Server Agent, so I must have Agent running to execute the following lines of code:
CREATE TABLE TestEmployees
(EmployeeID int identity,
EmployeeName varchar(30),
PayRate decimal(14,2))
-- SQL Agent must be running
exec sys.sp_cdc_enable_table
@source_schema = 'dbo',
@source_name = 'TestEmployees',
@role_name = 'cdc_TestEmployees'
-- This creates 2 Agent Jobs,
-- Capture and Cleanup job
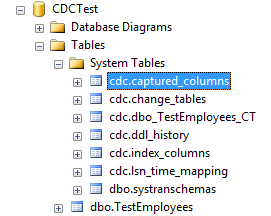
The system stored procedure sys.sp_cdc_enable_table creates several system tables in the CDCTest database. Figure 7 lists these tables, and Table 1 provides a brief description of some of the more critical tables.
Third, I'll insert some data into the sample TestEmployees table, then change a row, then delete a row.
insert into TestEmployees
values ('Kevin Goff', 20.00)
insert into TestEmployees
values ('Katy Goff',21.00)
declare @LastID int = (select SCOPE_IDENTITY())
update TestEmployees
set PayRate = 22.00
where EmployeeID = @LastID
delete from TestEmployees
where EmployeeID = @LastID
OK, so I've issued some DML statements that CDC will log: how do I see the changes? Well, my first-ever inclination was to query the change tracking log table cdc.dbo_TestEmployees_CT that I listed in Table 1. This generates the result set in Figure 8. The results, while perhaps different than what most are accustomed to seeing in a change tracking log, lists the following:

- Every inserted row after the insert takes place (with an _$Operation value of 2).
- Every updated row, with a log entry for the state of the row before the update (with an _$Operation value of 3), and also a log entry for the state of the row after the update (with an _$Operation value of 4).
- Every deleted row, with a log entry for the state of the row at the time of the deletion (with an _$Operation value of 1).
Yes, those values are correct: a 2 for an insertion, 3 and 4 for the before/after values on an update (respectively), and 1 for a deletion. So after the initial culture shock, the change log tracking table seems to have most of what people would want for audit trail history. However, two things are missing: the date/time of the change, and the person who made the change.
I'll take the date/time issue first. The date and time of changes are stored in the system table cdc.lsn_time_mapping (Figure 9). I can join this time mapping table to the change tracking table, via the LSN (log sequence number):

select ctlog.*, mapping.tran_begin_time,
mapping.tran_end_time, mapping.tran_id
from cdc.dbo_TestEmployees_CT as ctlog
join cdc.lsn_time_mapping mapping
on ctlog.__$start_lsn = mapping.start_lsn
Note that the time mapping table lists a transaction ID as well as the time of the insert/update/delete. That leads to the second question - what about the person who made the change?
Unfortunately, there's some “not-so-good” news. CDC in SQL Server 2008 does not provide native support for logging the user who made the change. Upon hearing this, some developers initially think they can use the T-SQL function SUSER_NAME() as a default value. This only works for inserts and won't handle situations where one user inserts a row, and then a second user updates the row. About the only failsafe method is to use database triggers to maintain a LastUser column in the base table; however, some (including myself) view this as at least partly defeating the purpose of a trigger.
Well, suppose I need to add a column to the database table. Can I assume that CDC will make the necessary internal adjustments, and start logging any changes to the new column? Well, just like the Hertz TV commercial from a few years ago, the answer is, “Not exactly.” And that's a segue to my next tip…
Tip 4: Change Data Capture and DDL Changes
Scenario: I implemented CDC in ** Tip #3 ** . I now want to add a column for each employee's Department. In addition to adding the column to the TestEmployees table, must I do anything else?
Obviously, if the answer were, “no, I don't need to do anything else” this would be a very short tip. Unfortunately, CDC is not dynamic enough to capture DDL changes (such as adding a new column) and automatically adjust the log tables. This limitation, along with the issue of “LastUser” in Tip 3, represents significant shortcomings that I hope Microsoft addresses in an otherwise strong piece of functionality.
OK, so if CDC doesn't automatically handle this, what must I do? Essentially, I have to execute four steps:
Step 1: I can make my DDL change to add a new column to the TestEmployees table.
Step 2: I must back up the change tracking log (or at least retrieve the entries into a temporary table).
Step 3: I actually must disable CDC for the TestEmployees table, and then re-enable CDC for the same table. This will re-create the change tracking log table (as an empty table).
Step 4: I need to load the entries from the temporary table (in Step 1) into the change tracking table that I just re-created in Step 3.
Listing 1 provides the SQL script for all of these steps.
Listing 1: How to adjust CDC change tracking log when DDL changes
-- Make the DDL change to add the new column
alter table TestEmployees add Department varchar(30)
-- Back up the current change tracking log to a temp table
select * into #TempLog
from cdc.dbo_TestEmployees_CT
-- Must manually add department to the backup log
alter table #TempLog add Department varchar(30)
-- Need to disable CDC for the table
EXEC sys.sp_cdc_disable_table -- this actually removes the table!
@source_schema = 'dbo','
@source_name = 'TestEmployees',
@capture_instance = 'dbo_TestEmployees'
-- Re-enable CDC for the table, which will pick up the DDL change
exec sys.sp_cdc_enable_table
@source_schema = 'dbo',
@source_name = 'TestEmployees',
@role_name = 'cdc_TestEmployees'
-- Now restore the backup of the change log
-- into the newly created log
insert into cdc.dbo_TestEmployees_CT
select * from #TempLog
drop table #TempLog
Anyone who has attended my presentations on SQL audit trail processing might be curious about my views on using Change Data Capture versus Update Triggers. Here are my views and observations on CDC (with the standard "the views expressed are those of the author and not necessarily….").
- In general, I like Change Data Capture and suggest that database developers (who have not already constructed audit trail solutions with update triggers) review CDC.
- Having said that, a shop that has invested time in reusable approaches with database triggers might view CDC as a small step backwards.
- CDC does have some issues that I hope Microsoft addresses in the future. First, as I wrote above, CDC does not capture “who” made the change: developers must handle that on their own (perhaps with a trigger, which partly defeats the purpose of a trigger). Second, in a heavy insert/update/delete workload situation, anyone querying the CDC Change Tracking logs might not see changes right away (due to the Agent job lagging a bit behind the SQL Server transaction log). Third, handling DDL changes (as I displayed above) are not seamless. (Of course, a workaround is better than no workaround).
- Database developers and DBAs in a heavy transaction workload environment will benefit from reading a very good MSDN article on CDC performance tuning. You can find the article by searching on “Tuning the Performance of Change Data Capture in SQL Server 2008.” The article describes the behavior of the CDC scan jobs, how to tweak settings for the CDC polling interval, and shows some performance benchmarks and settings recommendations.
Tip 5: Reading XML Files Into the Data Flow
Scenario: In the previous issue of CODE Magazine, I showed how to use the Data Profiling Task to take results from a survey/questionnaire and view the distribution of values using the built-in SQL Server DataProfileViewer. Knowing that the Data Profiling task can generate XML files, can I use other built-in SSIS tasks to “shred” this XML data into meaningful information?
Taking the results from the SSIS 2008 Data Profiling task and performing further “surgery” on the data requires a few steps.
Just to review, in the previous issue, I took an input file of survey questions and responses (like the following example) and used the Column Value Distribution option in the Data Profiling Task to generate an XML file
SurveyID, Q01, Q02, Q03, Q04 (up to Q10)
1, 5, 1, 5, 4
2, 4, 2, 4, 4
Suppose I wanted to periodically take the results of the XML file and insert those results into a SQL Server table that stored summarizations of responses by survey question? (The more general question is, how can I use SSIS to read XML data, and place the results somewhere else?)
Here are the steps I need to go through:
Step 1: I'm using the file SurveyXMLProfileResults.XML (from the InputFiles subfolder), that I created from Tip #6 in my last Baker's Dozen article. Important note: In my previous article, when I created a Column Value distribution Profile Request, I selected all columns (by selecting the asterisk ‘*' option). This actually makes it rather difficult (but not impossible) to read the XML data later. So I created the profile XML output by building ten separate column value distribution requests against the 10 columns (Figure 10), with a Profile ID name that maps to each of the 10 columns (“Q01”, “Q02”, etc.).
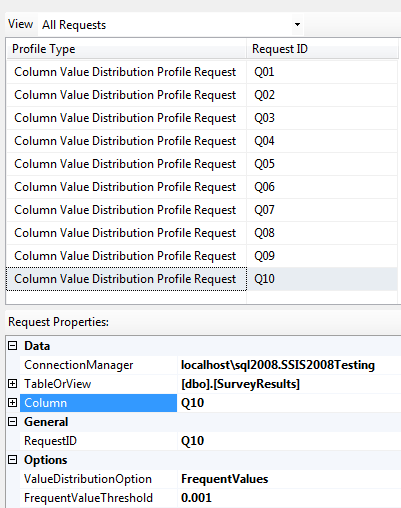
Step 2: In the data flow (Figure 11), I dropped an instance of the XML source, and pointed to the file SurveyXMLProfileResults.XML. The XML source will prompt me to generate an XSD (XML Schema Definition).
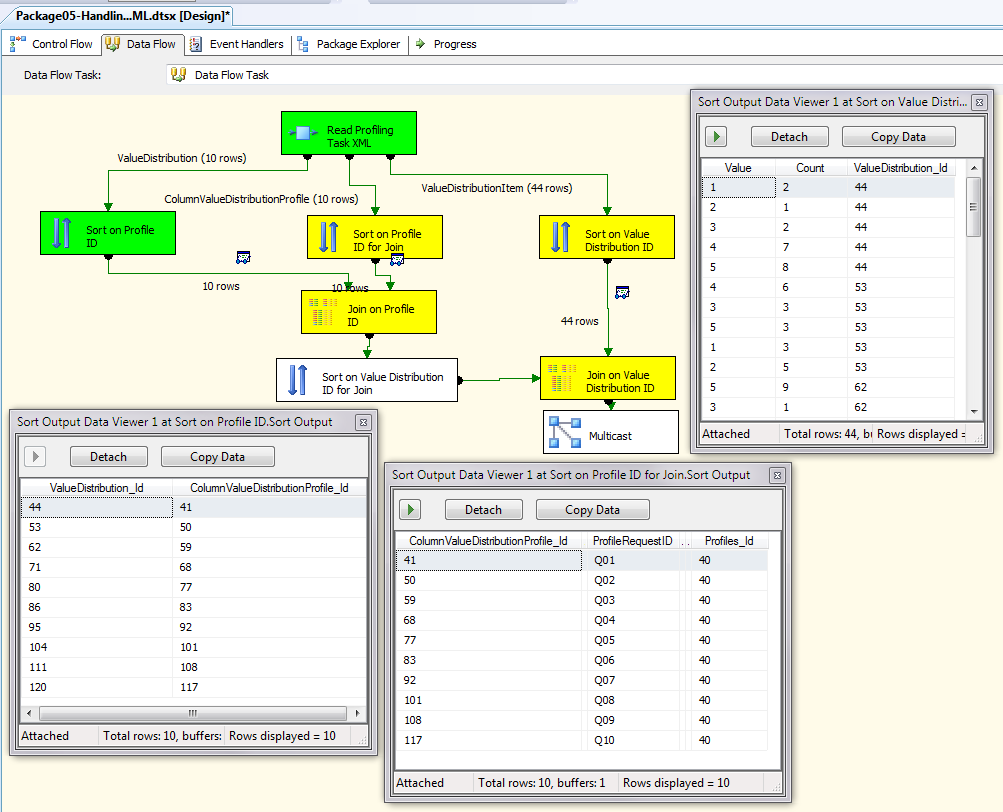
Step 3: This is perhaps the most important part of reading the XML file. Because the data profiling task creates XML files with many tables inside, I need to pull out just the tables and data I need. As it turns out, the data I need to summarize response values by question is stored across three tables:
-
`ColumnValueDistributionProfile:` Contains each ProfileRequestID (e.g. Q01, Q02, etc.), and a `ColumnValueDistributionProfileID` (an identity-like key, such as 14). -
ValueDistributionItem: Contains each response value, the count of number of responses, and a ValueDistributionID (an identity-like key, such as 17) -
ValueDistribution: Contains the links between the `ColumnValueDistributionProfileID` and the `ValueDistributionID.`
I'll drag three sort transformations into the pipeline and select the three tables from the source (when the sort transformations prompt me to the table I want from the XML source).
Step 4: I'll sort the ValueDistribution and ColumnValueDistributionProfile definitions on the ProfileID, and then join them together using the Merge Join transformation. Then I'll take the results of the Merge Join and sort it on the ValueDistributionID. (In the next step, I'll join this output to ValueDistributionItem).
**Step 5: ** I'll sort the ValueDistributionItem definition on the ValueDistributionID, and then join the sorted output against the sorted output from Step 4. At this point, I have the original question ID along with all of the responses and counts in a single pipeline.
Tip 6: A Control Flow Script Task
*Scenario: I need to create a filename dynamically that consists of a salesman name, the salesman ID number, and the current month/day/year. Can I use any of the built-in SSIS tasks, or do I need to use an SSIS script? *
In this instance, I'll need to use an SSIS script task in the control flow. In this example, I have five SSIS variables: FirstName, MI, LastName, BusinessEntityID, and SalesManFilename. I want the script task to read the first four variables (along with the current date) and concatenate them to create a filename to store in the fifth variable (SalesManFilename). For instance, if my BusinessEntityID were 1000 and I created the file on October 23, the filename would be Goff_Kevin_S_1000_10_23_2010.CSV
Listing 2 shows the code from an SSIS script task. The script populates the user variable SalesManFilename from the four other variables. In my last article, I showed a script task that accumulated variables, where I specified the read and read/write variables in the script task editor. In this example, I'll take a different approach. Instead of specifying the variables in the task editor (the equivalent of “early-binding”), I'll lock the variables in the script code (the equivalent of “late-binding”). This involves the following:
Listing 2: Example of Script task to create a dynamic file name
public void Main()
{
VariableDispenser vd =
this.Dts.VariableDispenser;
Variables vars = null;
// Lock variables from the package manually
// (instead of specifying in the script editor)
vd.LockForRead("User::FirstName");
vd.LockForRead("User::MI");
vd.LockForRead("User::LastName");
vd.LockForRead("User::BusinessEntityID");
vd.LockForWrite("User::SalesmanFilename");
vd.GetVariables(ref vars);
DateTime dt = DateTime.Now;
// Create File Name from Salesman name and datetime
string FirstName =
vars["User::FirstName"].Value.ToString();
string LastName =
vars["User::LastName"].Value.ToString();
string MI =
vars["User::MI"].Value.ToString();
string BusinessEntityID =
vars["User::BusinessEntityID"].Value.ToString();
string FileName = LastName + "_" + FirstName + "_" +
MI + "_" +
BusinessEntityID + "_" +
dt.Month.ToString() + '_' +
dt.Day.ToString() + '_' +
dt.Year.ToString()+ '.CSV';
vars["User::SalesmanFilename"].Value = FileName;
MessageBox.Show(FileName);
this.Dts.Variables.Unlock();
Dts.TaskResult = (int)ScriptResults.Success;
}
- Accessing the SSIS package VariableDispenser (which provides the means to access package variables programmatically, just like any dispenser).
- Using the
VariableDispenserto lock the variables (either for reading for writing). - Retrieve the variables into a variable collection (using the Dispenser method GetVariables).
- Access each variable to create the
filenamestring value. - Unlock the
variables.
Tip 7: A Data Flow Script Component
Scenario: I'd like to perform the same process as ** Tip #1 ** *(shredding an irregular input file into multiple output pipelines) using an SSIS script component. How can I use the SSIS scripting capability to read the complex input file and create three different sets of rows on the output?*
In the last tip, I showed how developers can use SSIS scripts in the control flow. Now I'll demonstrate how to use SSIS scripts to read input pipeline rows in the data flow task.
The package starts with the same flat file source that I created in step 1 in Tip 1. But then the steps are as follows:
Step 1: Drag in a script component into the data flow, and select Transformation as the component type.
Step 2: In the Script Input columns, select Column0 as the Input column (read only).
Step 3: The script component needs to know about the three output rows (Order Header, Order Details, Order Notes). So in Figure 12, in the Input/Output section of the script component editor, I've defined three separate outputs: TypeAOrderHeader, TypeBOrderDetails, and TypeCOrderNotes. Inside of each of the three separate outputs, I've defined the column names and column types. Finally, take note that I've set the SynchronousInputID for TypeAOrderHeader to None.
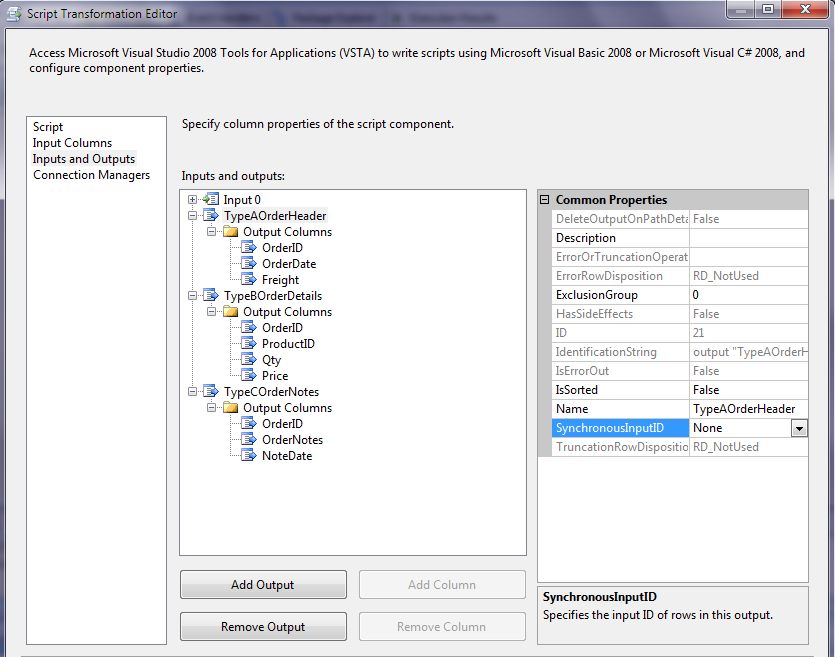
Step 4: In the script tab, I clicked Edit Script, and entered the code for the override method for Input0_ProcessInputRow (Listing 3). The method is a hook that SSIS provides, so that I can insert my own method code. The code itself does the following:
Listing 3: Data Flow Script to process/split a row into multiple rows
public override void Input0_ProcessInputRow (Input0Buffer Row)
{
char[] delimiter = new char[] { ',' };
string RowLine = Convert.ToString(Row.Column0);
string[] IrregularValues = RowLine.Split(delimiter);
string RecordType = IrregularValues[0];
switch (RecordType)
{
case "A":
TypeAOrderHeaderBuffer.AddRow();
TypeAOrderHeaderBuffer.OrderID =
Convert.ToString(IrregularValues[1]);
TypeAOrderHeaderBuffer.OrderDate =
Convert.ToDateTime(IrregularValues[2]);
TypeAOrderHeaderBuffer.Freight =
Convert.ToDecimal(IrregularValues[3]);
break;
case "B":
TypeBOrderDetailsBuffer.AddRow();
TypeBOrderDetailsBuffer.OrderID =
Convert.ToString(IrregularValues[1]);
TypeBOrderDetailsBuffer.ProductID =
Convert.ToString(IrregularValues[2]);
TypeBOrderDetailsBuffer.Qty =
Convert.ToInt32(IrregularValues[3]);
TypeBOrderDetailsBuffer.Price =
Convert.ToDecimal(IrregularValues[4]);
break;
case "C":
TypeCOrderNotesBuffer.AddRow();
TypeCOrderNotesBuffer.OrderID =
Convert.ToString(IrregularValues[1]);
TypeCOrderNotesBuffer.OrderNotes =
Convert.ToString(IrregularValues[2]);
TypeCOrderNotesBuffer.NoteDate =
Convert.ToDateTime(IrregularValues[3]);
break;
}
}
- Converts each input row buffer to a string.
- Uses the string Split function to shred each set of column values into a string array.
- Reads the first column in the string array to check for the Record Type (“A” for Order Header, etc.).
- Based on the value of “A”, “B”, or “C”, the code adds a row to the appropriate output buffer and assigns the properties (output columns) based on the corresponding column values from the string array.
Tip 8: Reading/Writing SharePoint Lists from SSIS 2008
As SharePoint becomes more and more prevalent, so follows the requirement to integrate SharePoint content with database applications. Many developers post questions on different forums on how to either read from SharePoint lists or save data to SharePoint lists using SSIS. Fortunately, CodePlex has several community samples and utilities for SSIS. The link is <a href="http://sqlsrvintegrationsrv.codeplex.com">http://sqlsrvintegrationsrv.codeplex.com. One of the samples on this site contains SSIS custom data source and data destination adapters for SharePoint lists.
The link provides an entire tutorial with screenshots and examples so there's no need to repeat the details here.
Additionally, some people ask on technical forums about monitoring CPU and memory utilization on servers (even SharePoint servers). SSIS 2008 provides a WMI (Windows Management Instrumentation) Event Watcher task to monitor CPU and memory statistics.
Tip 9: Data Conversion Potpourri
Scenario: Someone sends me an input file with product weight values, such as “65 lbs”, “57 lbs”, etc. I need to strip out the “lbs”, convert the number to a decimal, and then return a range to which the value belongs (such as “60 lbs and above”, “40-60 lbs”, etc.)
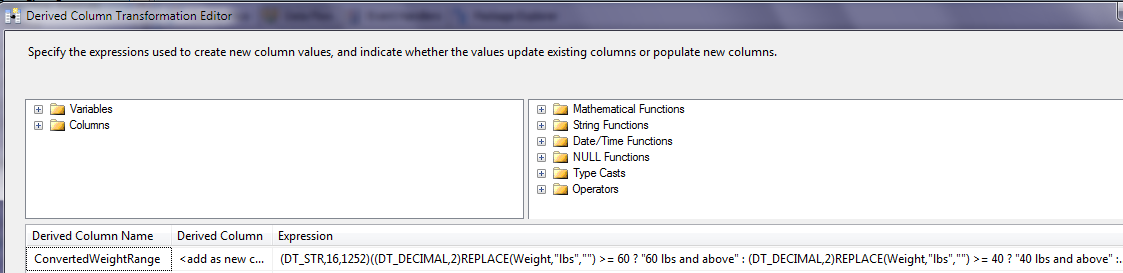
Every once in a great while, developers write a piece of code that should contain a warning, “Keep small children out of the way.” Recently I had to write a “quick and dirty” (and am proud of it!) code expression in a derived column transformation, to take input values like “65 lbs” and place them into a small, hard-wired set of ranges. Here is the expression I used in the derived column transformation:
(DT_STR,16,1252)
(
(DT_DECIMAL,2)REPLACE(Weight,"lbs","") >= 60 ?
"60 lbs and above" :
(DT_DECIMAL,2)REPLACE(Weight,"lbs","") >= 40 ?
"40 lbs and above" :
(DT_DECIMAL,2)REPLACE(Weight,"lbs","") >= 20 ?
"20 lbs and above" :
"0 to 20 lbs"
)
- On the inside, I used the SSIS function REPLACE to strip out any instances of “lbs” and replace with an empty string.
- I cast the results of the REPLACE as a DECIMAL type with 2 decimal positions (using DT_DECIMAL,2).
- I used the question mark and colon conditional operators (? and 😃 to perform the equivalent of an in-line if statement (i.e., to test the decimal value to see if it is greater than 60, or greater than 40, etc.
- Finally, I cast the result as a string with a length of 16.
Figure 13 shows the actual derived column transformation. Because of the complexity of this expression, some developers might elect to create a simple script component in the data flow pipeline to accomplish the same task.
Tip 10: SSIS Parent-Child Package Configurations
Scenario: I have a Master SSIS package that runs a series of child SSIS packages, using the Execute Package task. All the child SSIS packages make a connection to a SQL Server database. I want to configure an SSIS variable in the Master package to store the name of the database server (e.g. "localhost\MSSQLSERVER2008", "CompanyServer\SQL2008R2", etc.). I then want to configure all the child packages to use the configured variable when connecting to the database server. As a result, if I need to run the master package (which will execute all the child packages) today on Server A and then tomorrow on Server B, all I need to do is change the package configuration XML file.
Parent-Child Package configurations in SSIS are actually quite easy to implement, though some environments don't always take advantage of them. In this example, I'll define three packages: Master Package A and Child Packages B and C. All three packages will contain a variable called DBServer. Master Package A will map the DBServer variable to an XML package configuration file called ParentChildPackageConfig.dtsConfig. Child Packages B and C will each contain a basic Execute SQL task with a connection manager that reads the DBServer variable to get the server name. So here are the actual steps:
Step 1: Create a package called Master Package A. Inside the package, create a variable called DBServer with a data type of String. Create an XML configuration file (from the SSIS main menu pulldown) that maps to the DBServer variable, and save the configuration file as ParentChildPackageConfig.dtsConfig.
Step 2: Create two child Packages, B and C. In each of the two packages, create the same DBServer variable. Then create an Execute SQL task that performs a simple query against any database table in AdventureWorks 2008 (e.g. SELECT * from Production.ProductCategory). In the connection manager for the Execute SQL Task, go to the properties sheet, set the DelayValidation Property to TRUE and configure the Server expression property to use the DBServer variable.
Step 3: In the two child Packages (B and C), go into the SSIS configuration screen and create a configuration with a type of Parent Package variable. SSIS will prompt for the parent variable (DBServer), and then the property from the child package that will map to the parent variable (also DBServer).
Tip 11: Handling Type 2 Slowly Changing Dimensions - Design Is Never More Important
Scenario: I have a situation where certain customer demographics (customer zip code, customer income range, etc.) might change over time. I need to track historical data associated with these changes. For instance, suppose I'm working in an insurance application. Someone might move three times in five years (i.e., different zip codes), and I need to track insurance policy and claim information associated with each zip code, at the time of policy endorsements, claim processing, etc.
In the database and data warehousing world, this is known as a Type 2 Slowly Changing Dimension (SCD**).** In a nutshell, a Type 2 SCD is a data modeling concept that features database support for reporting on data based on business attribute values at the same. Another example might be a product price change - a company might want to know the sales return rate when a price was X dollars per unit in 2008, versus Y dollars per unit in 2009.
While support for Type 2 SCD scenarios is sometimes believed to be restricted to data warehousing and OLAP environments, it's always possible that a transaction-oriented system that also doubles as a hybrid information system might need to provide similar functionality. The point is that one can find the requirement to report on sales or other metrics over time, under “Attribute A condition” versus “Attribute B conditions”.
So what does this have to do with SSIS? Well, where there is a requirement, there are likely countless scenarios for data workflow and capturing changes to business attributes. Here are some scenarios and important considerations, and where we might use SSIS and/or T-SQL code:
- There could be SSIS packages that periodically read customer feeds, and must detect if any demographics have changed.
- The import process for these customer feeds may need to capture/collect an “effective date” for any
attributechanges. For instance, an incoming customer record might have a changed zip code, but the change might not go into effect for another month. - Any posting of historical transactions needs to establish the related business attribute. For instance, if a customer files an insurance claim on July 1, 2010, the data import process must determine the customer's zip code at the time of the
claim. - As an added attraction, perhaps the zip code change is “late-arriving”; that is, the new zip code isn't posted to the system until after processing the claim record.
As it turns out, SSIS has a slowly changing dimension task. A developer simply needs to provide information on the destination table and the source table, the list of attributes (columns) that represent Type 2 SCD situations, and some additional information on business keys and effective dates. Some developers use this transformation, while others prefer to write custom T-SQL code.
In many environments, Type 2 SCD scenarios can represent crucial business requirements. Certainly, getting the data model correct and writing efficient code are key ingredients; however, no DBA/developer can even get to those points without a clear set of requirements and a clear understanding of the scenarios, use cases, etc. Failing to account for key scenarios can damage the credibility of a system.
Tip 12: SSIS Package Logging
Scenario: I want to know how long specific tasks and processing are taking in my packages. I'd like to generate a log output file that shows each step in my package and the elapsed time.
SSIS provides the ability to create multiple output logs per SSIS package, with information on the start/end time of the events that fire in the package. Once I configure an SSIS package to create one or more logs, the package will create the log file(s) on every execution.
The steps to create an SSIS package log are as follows:
Step 1: From the SSIS menu pull-down, select "Logging…". Visual Studio will display a dialog box where I can begin to configure the output log(s) (Figure 14).
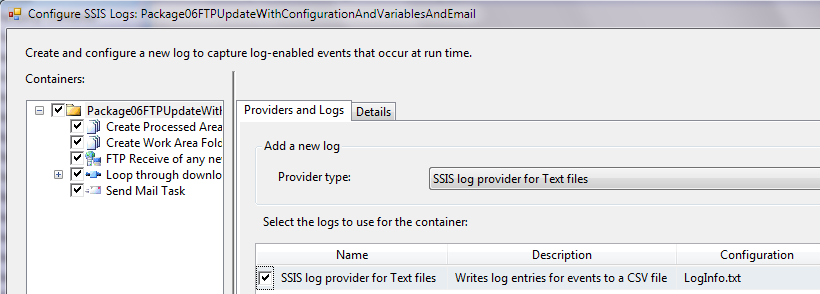
Step 2: In the SSIS Log Configuration screen (Figure 15), I can check (on the right-hand side) the package containers I want to log. Remember that the control flow as a whole is a package container, the data flow is a package container, and control flow tasks like the Foreach Loop container and the sequence container are also package containers.
At the top level (the package overall), I can select the type of log output(s) I want. Note that SSIS only enables this selection for the package as a whole. The log provider types are Text Files, XML files, SQL Server (and SQL Server Profiler), and the Windows Event Log.
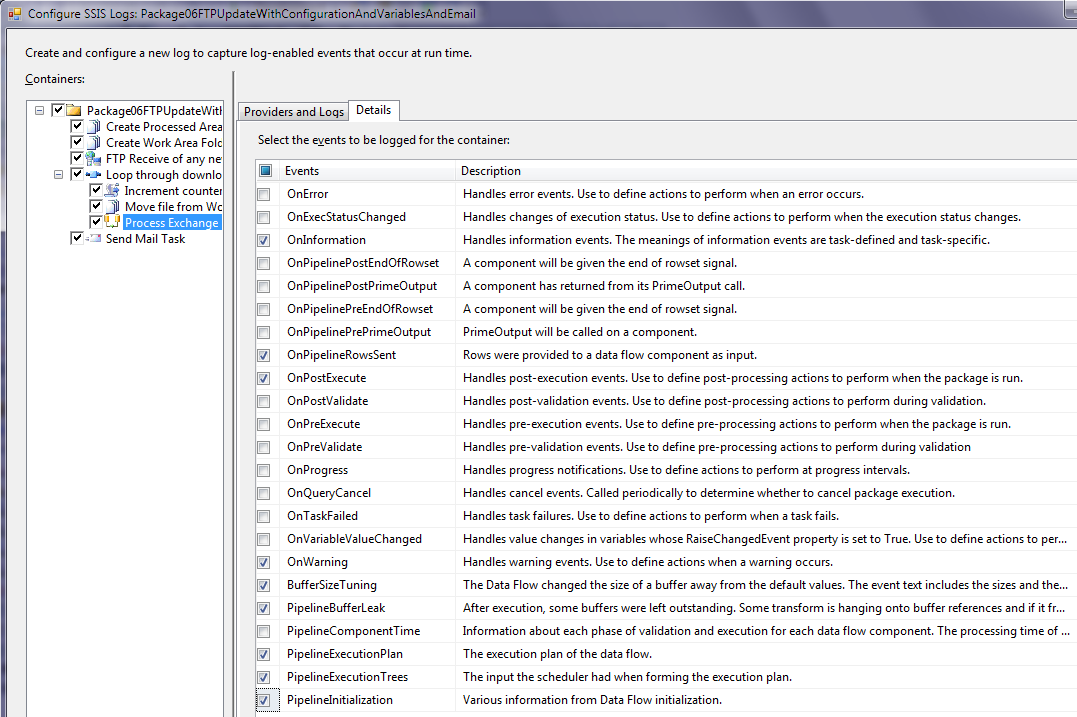
Step 3: For each of the package containers that I select on the left, I can define the specific events I want to log on the right (Figure 14). Note that each package container has a different set of events. For instance, the package container itself only has 13 events for logging; by contrast, the data flow has 23 events for logging.
Tip 13: Calling SSIS Packages from .NET
Scenario: While some of my SSIS packages run from SQL Server Agent on a schedule, I'd like to execute some of my SSIS packages from within a .NET application.
In Listing 4, I've created a method in C# (in VS 2010) to execute a deployed SSIS package.
Listing 4: Executing a package from C#
static void ExecutePackageFromSQLServer()
{
string MyPackage = "MyTestPackage";
string MyServer = "localhost\MSSQLSERVER2008";
Microsoft.SqlServer.Dts.Runtime.Application oApp = new Microsoft.SqlServer.Dts.Runtime.Application();
Package oPackage = oApp.LoadFromSqlServer(MyPackage, MyServer, "", "", null);
// Configuration file might come from the SSIS package store
oPackage.ImportConfigurationFile(@"c:\" + MyPackage + ".dtsConfig");
Variables oVars = oPackage.Variables;
oVars["FileVariable"].Value = @"c:\SomeFile.CSV";
DTSExecResult oResult = oPackage.Execute();
}
Step 1: In the .NET application, I needed to create a .NET reference to the SSIS .NET Assembly Microsoft.SQLServer.ManagedDTS.DLL (which resides in the ``\Program Files (x86)\Microsoft SQL Server\100\SDK\Assemblies folder.
Step 2: I added a using statement to Microsoft.SQLServer.DTL.Runtime, at the top of the C# source file.
Step 3: After setting the references, I can create an instance of an SSIS runtime application, load the package from SQL Server, import any configuration file, and programmatically set any SSIS variables before executing the package.
Conclusion
I hope you enjoyed reading my last two articles on SSIS 2008 as much as I enjoy talking about the product. SSIS 2008 reminds me of a special Swiss Army Knife for database jobs: if I have a requirement to retrieve data from one system, do something with the data, and then load the data somewhere else, SSIS 2008 usually does the trick. If you write code to work with data across systems and file formats, you might want to give SSIS 2008 a try. I'm very glad that I did!
| CDC System Table | Description |
|---|---|
| cdc.captured_columns | Contains all columns that CDC is monitoring. |
| cdc.change_tables | Contains all tables that CDC is monitoring. |
| cdc.dbo_TestEmployees_CT | The log table for all changes to the table TestEmployees. |
| cdc.lsn_time_mapping | Contains all log sequence numbers for changes that CDC captures, along with the `datetime` and the transaction ID. |
