


Database developers who learn Microsoft SQL Server Analysis Services (SSAS) know that they face a number of learning curves. In prior Baker's Dozen articles, I've covered many of the steps for creating both SSAS OLAP and SSAS Tabular databases. In this article, I'm going to cover another topic: How to add or change data in analytic databases.
If you're coming from the relational database world, you're probably thinking that analytic databases have commands similar to T-SQL DML statements for inserting and updating rows. Well, as they often say in TV commercials, “not exactly.” Updates to a analytic databases are comparatively more batch-oriented, using commands known as XMLA commands. This article covers several different scenarios for inserting and updating data into analytic databases.
What is XMLA and Why is it Important?
XMLA stands for “XML for Analysis Services”. XMLA is a protocol/standard for updating data in OLAP or analytic databases. Microsoft (along with Hyperion and SAS) lead an XMLA council (with more than 25 other participating companies) to maintain the XMLA specification.
XMLA contains processing commands for updating analytic databases from source data. Unlike T-SQL DML statements for inserting, updating, and deleting rows, XMLA processing commands are batch oriented. Scenarios involving XMLA include rebuilding an OLAP cube from scratch (from the source data), incrementally adding rows to an OLAP cube, and adding and updating new dimension rows from source data. Note: throughout the article, when I refer to adding rows to an OLAP cube, it could also be for a fact table or even a fact table partition.
Figure 1 shows an overview of an OLAP environment, and how XMLA code fits into the process. In this article, I'll cover several scenarios for processing OLAP cubes, and the necessary XMLA commands for doing so.
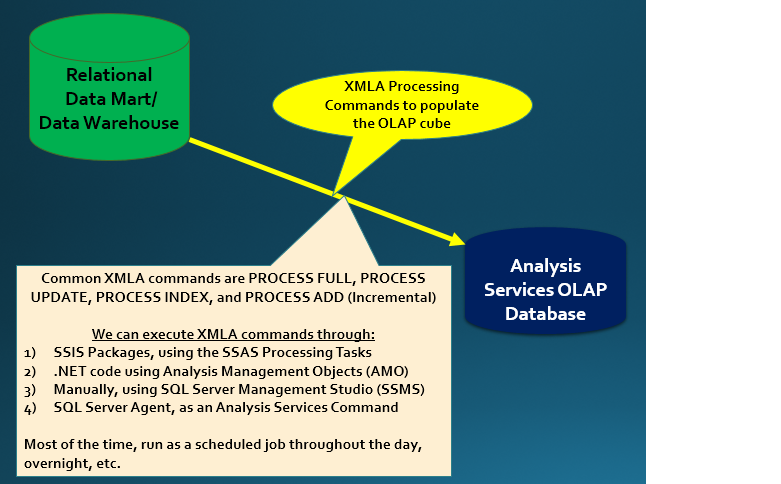
Knowing how to use XMLA in processing scenarios is one of the many items that separates a casual SSAS developer from a strong one. The processing commands have an intellectual intersection point with OLAP cube features.
Knowing how to use XMLA in processing scenarios, and knowing how to use SQL Profiler to keep an eye on processing commands-these are two of the many items that separate a casual SSAS developer from a strong one. The processing commands have an intellectual intersection point with OLAP cube features.
What's on the Menu?
Here are 13 scenarios for using XMLA processing commands:
- An overview of XMLA Processing commands and the different ways to execute XMLA code
- A simple example of a Process Full on the entire OLAP database
- A simple example using a Process Full on a Partition
- A simple example using a Process Update on Dimensions for incremental insertions/updates
- A simple example using a Process Update command with dimensions that have rigid attribute relationships
- A simple example using a Process Index in conjunction with a Process Update
- A Process Default definition and why you need to use it
- A discussion of Process Add vs. Process Update with dimensions
- A simple example using Process Incremental on Fact Tables
- Using SQL Profiler to watch the processing commands
- Using XMLA for backups
- Using XMLA to clear OLAP caches
- Using SSIS Scripts and .NET to process dimensions
Item #1: An Overview of the XMLA Processing Commands and the Different Ways to Execute XMLA Code
Table 1 lists all of the XMLA commands available in Analysis Services. The next several items cover many of these commands. I want to stress several points right away, and then I'll ask you to come back after you finish and read these points again.
- Use XMLA processing commands and not SQL DML statements.
- These commands are generally more “batch” oriented, as they read data from the OLAP source (usually a relational database) to post to the OLAP cube.
- These commands have rules associated with them. You will see these rules as you go along, but a few bear mentioning immediately.
- The processing commands for dimensions will allow you to insert or update dimension rows.
- The processing commands for fact tables are INSERT ONLY. I repeat: you CANNOT-absolutely CANNOT-update fact rows with XMLA commands. I'll elaborate on this later.
- DELETE is a dirty word in many data warehousing and OLAP systems. In most instances, if a row makes it as far as the data warehouse or an OLAP database, it got there for a reason. It's more likely that the row will be marked as inactive instead of deleted.
- Most OLAP developers do not use all of the XMLA commands. Table 1 lists the ones that tend to be used most often (though even within this list, some are more popular than others).
- Some XMLA commands are used in conjunction with others. For instance, a Process Update on dimensions might be followed with a Process Index on both the dimensions and fact tables.
- You ALWAYS process new or modified dimension entries BEFORE processing new fact table rows. No exceptions!
As displayed in Figure 1, you have several options for incorporating XMLA into a processing scenario to update an OLAP cube. A popular technique (one I use often) is to use SQL Server Integration Services (SSIS). SSIS contains two different tasks to incorporate XMLA commands: an Analysis Services Processing Task and an Analysis Services Execute DDL Task. The former provides a builder-like interface to build XMLA statements, and the latter is for advanced developers to use to execute custom pre-built XMLA code.
Item #2: A Simple Example of a Process Full on the Entire OLAP Database
Scenario: You want to completely rebuild an existing OLAP cube from the source data. The complete contents of the OLAP cube should be cleared out and replaced with the information from the source data. You want to place the XMLA command for a full process into an SSIS package, and run the package on schedule.
For these examples, I've rebuilt a subset of the AdventureWorks OLAP database, calling it ADW_OLAP_XMLA. I've created two fact tables: FactCustomerSales is a stripped down version of the full blown FactInternetSales, and FactVendorSales is a stripped down version of the full blown FactResellerSales. Also, I've brought forward four dimensions: Date, Customer, Product, and Vendor.
In Figure 2, I've used Excel to build a basic PivotTable that shows sales dollars and row counts for both fact tables, broken out by year. This represents the state of the data after first building the OLAP cube from a Visual Studio SSAS project.

Now, suppose I add a single row of data to both fact tables, and some additional data to any of the dimension tables. I want to rebuild the OLAP cube from scratch. Perhaps the rebuild is an overnight process and I don't care if it seems like overkill to reprocess the entire OLAP cube just for a few rows. Obviously, I could reload Visual Studio and reprocess the OLAP cube, but I'd really like to use XMLA processing commands.
In Figure 3, I've created an SSIS package and I've brought in an Analysis Services Processing task. The SSAS processing task allows me to point to an OLAP database (as a connection), and then indicate which aspects of the database I want to update. In this case, I want to build the OLAP cube from scratch. So in the Task Editor in Figure 3, I select a Process Update on the entire database. This generates XMLA code (available as a property in the Task Property sheet) that I could run manually in SQL Management Studio if I wanted to (Figure 4).
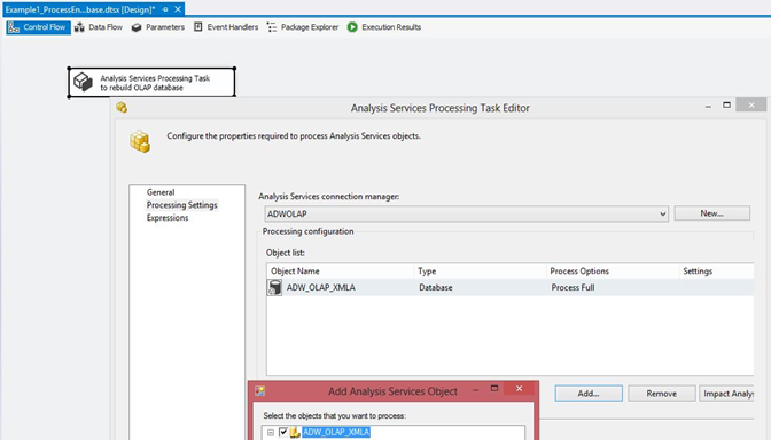
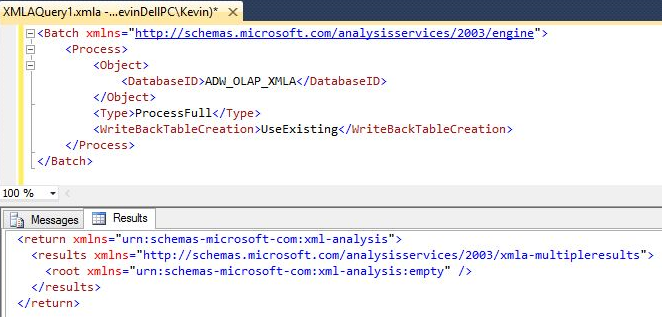
At this point, I can execute the SSIS package (or set it up as a SQL Server Agent job). Afterwards, if I were to refresh the Excel spreadsheet back in Figure 2, I would see the impact of the new rows.
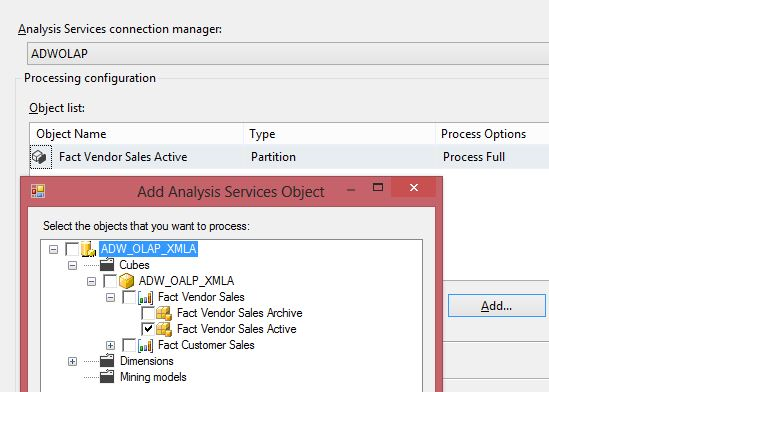
Item #3: Using a Process Full on a Partition
Scenario: I have a partition in one of the fact tables that separates archived rows (anything before 2011) from active rows (2011 and later). When I have new rows from the source data, I want to completely rebuild just the active partition and leave the archived partition intact.
However, in this scenario, not only will I add a new fact row into a partition (back in the relational source), but I'll also add a new dimension row as well. I will intentionally try to process the fact row without also processing the dimension row, and see what happens.
Many data teams take OLAP Fact tables and create partitions (usually based on a date range). This might be done to improve query performance on partitions that users access frequently (i.e., data in the last two years), and also might be done to focus any rebuilds or restatements on a single partition (as opposed to the entire fact table). If data for the last month is fluid and can change, and if the OLAP update process occurs overnight, it's better to rebuild a smaller partition for the last month, as opposed to rebuilding the whole OLAP cube because a small percentage changed.
In the example, in Figure 5, I've created a partition in the SSAS project, to break out the FactVendor table for all rows before and after 2011. Now let's assume that I've added a new row into one of the dimension tables (maybe the date dimension, for a new day in 2011) and that I've also added a new row to the FactVendor table back in the data mart.
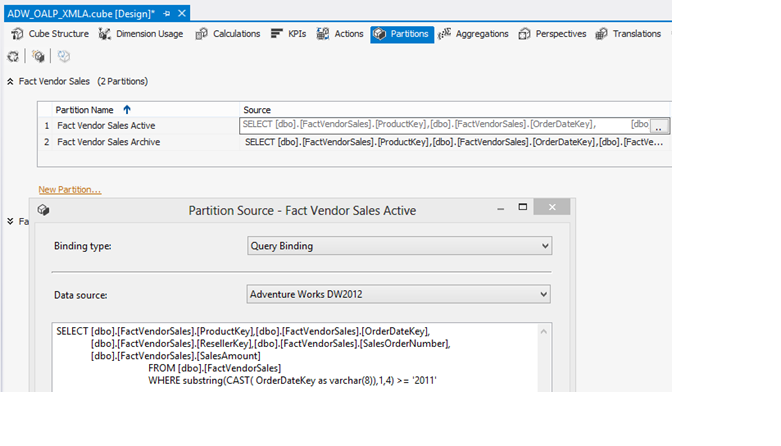
So instead of performing a Process Full on the entire OLAP cube, let's try to do a Process Full on just an active partition. I'm intentionally NOT going to do any kind of process on the date dimension. In other words, I'm going to try to do a Process Full on a partition of the fact table that contains a foreign key that does not exist in the OLAP dimension. Obviously, in a relational database with primary and foreign key constraints, the database engine will not permit this. What will the Analysis Services Engine do?
In Figure 6, I've created another SSIS package and I've brought in the SSAS Processing task. In the Object List, I've selected the active partition. However, when I attempt to run the package, I receive the error in Figure 7 that an attribute key in the fact table was not found in the dimension.

So the moral of the story here is, very clearly, that the SSAS engine will not permit any new fact rows with foreign keys that are not found in the related OLAP dimension. So I need to post the missing date row from the OLAP source database into the OLAP dimension. What task should I use for that? That's a segue to the next item and the next processing command: Process Update.
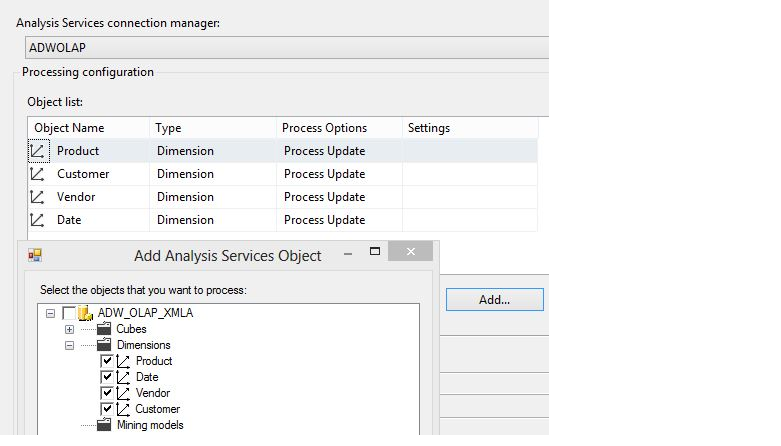
Item #4: Using a Process Update on Dimensions for Incremental Insertions and Updates
Scenario: In a continuation of the last item, I discovered that I cannot process a fact row if any foreign key values are not found as primary keys in the dimension tables. I must process the dimensions as well. I will introduce a Process Update command for the dimension and THEN use a Process Full on the active partition.
The XMLA Processing command Process Update is a rather unique command. First, from Table 1, it only applies to dimensions. Second, it will read the contents of the source dimension (the data mart, data warehouse, or OLAP staging area), and also read the contents of the OLAP dimension, and look for new or changed rows (based on the designated primary key of the dimension).
As an aside, this is one of the many millions of reasons why tables should always have a primary key, preferably a surrogate integer value.
Figures 8 and 9 show an enhancement to the package from the prior step, including the use of the Process Update command in the SSIS Processing Task Editor. Note that I've used Process Update for all four dimensions for this simple example. In a production environment, this might be more elaborate, with separate tasks for each dimension, and a prior check to see if any dimension rows have been added or changed in the relational source area, as a condition to run the XMLA processing command.

So after issuing the Process Update command on all four dimensions, and then a Process Full on the partition, the rows now appear in the OLAP cube.
At this point, many are impressed with the Process Update commond on a dimension. It certainly is a valuable tool for scenarios where dimension rows are inserted or modified in the source and need to be incrementally transferred. I don't need to write any code; I can just let the Process Update perform the insert or update logic.
However, there are two issues with Process Update that I'll cover in the next two items. First, it cannot be used to incrementally process dimensions that contain rigid attribute relationships, when the values for those relationships change (e.g., Vendor A is reclassified from “Group A” to “Group B” as an overwrite). In that situation, I need to do a Process Full on that dimension. Second, repeated use of Process Update degrades the performance of the OLAP dimension (and any aggregations on which the dimension is based). In that situation, you should use Process Index on both the dimension and fact tables. Those are the “talking points” for the next two items.
Item #5: Rules on Process Update with Dimensions that have Rigid Attribute Relationships
Scenario: Back in the OLAP cube, I will define a rigid hierarchical relationship in the Vendor dimension, for the parent-child hierarchy of Business Type down to Vendor. A rigid hierarchy allows me to store aggregations at the Business Type level, which will speed up OLAP queries. However, the downside is that even if one vendor row is re-organized into a different business type parent, I cannot use the Process Update command on that dimension. I must use the Process Full on that dimension.
Some OLAP developers build what are called “rigid attribute relationships.” These are often tied to hierarchy levels that seldom change. The benefit of rigid attribute relationships is that any aggregations (stored subtotals) for the parent levels are further materialized in the OLAP cube, leading to better performance. Rigid attribute relationships and fact table aggregations are means of performance optimizing OLAP cubes. Figures 10 and 11 show the SSAS dimension editor features for defining a simple attribute relationship between vendor and business type. (Most attribute relationships will be deeper, with four or five levels, or even more).
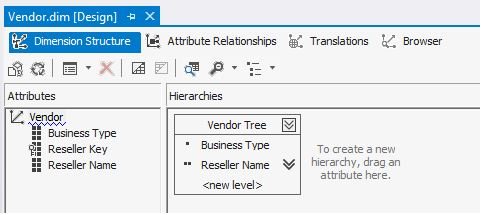
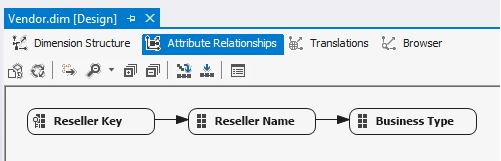
However, the downside is that if any value relationships DO change, I cannot use Process Update. This will actually generate a fatal error during any OLAP dimension processing. In this case, I have two options. One is to make the attribute relationship flexible (as opposed to rigid), which will allow me to continue using Process Update. The other option is to use Process Full on the dimension (Figure 12).
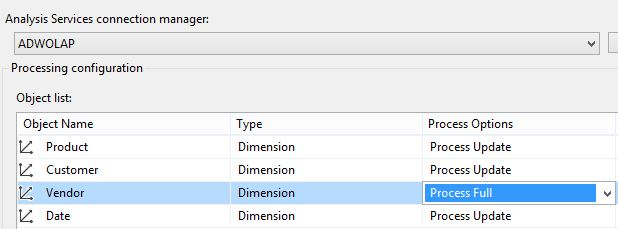
If you use rigid dimension attribute relationships, you must perform a Process Full command on the dimension if even one row in the dimension is re-classified to store a different parent. If you try to use a Process Update in this situation, the SSAS Engine raises a fatal error.
Item #6: Using a Process Index in Conjunction with a Process Update
Scenario: Frequent use of the Process Update command on dimensions gradually slows down the performance of the dimension. I should occasionally use the Process Index on the dimension to rebuild dimension indexes. Also, if the dimension is used in any fact table or partition aggregations, I should use the Process Index on fact tables to rebuild aggregations.
Many OLAP developers, after using a Process Update on dimensions, use a subsequent Process Index on the dimension (Figure 13 and Figure 14). This rebuilds the bitmap indexes for dimension attributes and is recommended to maintain optimum size and performance of the dimension.
Additionally, as Process Index is necessary on fact tables or partitions to rebuild aggregations that are dropped when a Process Update occurs on dimensions that affect the aggregation definition. So a good example of a production package is a pre-check, whether any new values introduced into the dimension warrant the execution of Process Index on the fact table or not. It's critical to consider these strategies as you consider update scenarios.
You'll need to (selectively) manage certain XMLA processing commands in pairs. For instance, you might need to follow a Process Update on a dimension with a Process Index on the dimension, and even related fact tables (if dimension changes would affect aggregations). So it's important to design update strategies and consider update scenarios.
You'll need to (selectively) manage certain XMLA processing commands in pairs. For instance, you might need to follow a Process Update on a dimension with a Process Index on the dimension, and even related fact tables (if dimension changes would affect aggregations). So it's important to design update strategies and consider update scenarios.
Item #7: A Process Default Definition, and Why I Need to Use It
Process Default is one of the least-understood processing commands. A number of OLAP developers do not use it in production, and others (usually those less familiar with its purpose) “throw it in” on the belief that it will do a safety refresh. (An analogy is inexperienced T-SQL developers who use SELECT DISTINCT in instances where it's not necessary).
The MSDN documentation tells me that Process Default does the bare minimum to bring OLAP objects to a fully processed state. This means that it builds storage contents only for those that are not currently built. If processing has not been done on a cube, Process Default performs the equivalent of a Process Full.
Again, most developers do not use this command very much, and most choose to implement their own functionality.
Item #8: Process Add vs. Process Update with Dimensions
Process Update for dimensions is like a T-SQL MERGE: it will insert any new dimension rows from the source (based on the primary key) that do not exist in the dimension table. It will also update any dimension rows that have changed.
Process Add for dimensions only performs inserts. It will not perform updates.
Item #9: Using Process Incremental and Process Add on Fact Tables
Scenario: Every day, I might insert 10,000 new rows into the source system. I want to extract everything from the source system that has been added since the time of the last OLAP build, and incrementally insert those rows into the fact table. I do not want to “blow away” the contents of the partition; instead, I want to incrementally insert the new rows using the Process Add (previously called Process Incremental prior to SQL Server 2012).
A common question, when learning XMLA is similar to what I've proposed here in the scenario: I have a small number of new rows to post to a fact table (or partition). It seems like overkill to perform a Process Full on the cube, fact table, or partition, just to get a small number of rows in. Is there any way to insert the new rows, without needing to reprocess a large number of rows that haven't changed?
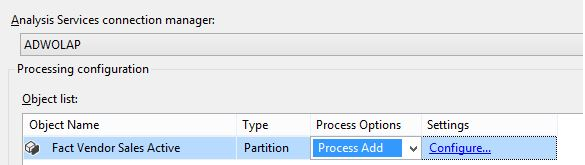
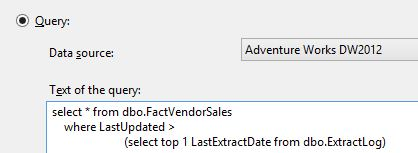
Prior to SQL Server 2012, developers used a Process Incremental, which did just that. (Microsoft has since renamed it to Process Add). This is a great command, however, it is one that needs to be tested thoroughly. The developer needs to identify (usually through some extract log) what rows have been inserted since the last extract, and must pull them from the source table (usually a query based on a LastUpdate field value being greater than the date of the last Extract).
Figures 13 and 14 show an example of the Process Add (again, formerly Process Incremental). When using this processing command against a fact table or partition, you must select the CONFIGURE option and supply a query, one that retrieves the new rows from the source that you wish to post (non-destructively) to the OLAP destination.
It's also very important, after running the Process Add, to update the extract log control table with the current date/time-that way, if someone runs this package immediately afterwards, there should be no rows to retrieve and therefore no rows to post.
Finally, if you're wondering if you can UPDATE rows in a Fact Table, the short answer is that you can't. This will be hard for many to accept, but you absolutely cannot update previously posted fact table rows. Your options are either to rebuild the cube or send in a reversing entry before sending in the “good” row. In the case of the latter, think of your cube as a general ledger.
This will be hard for many to accept, but you absolutely cannot update previously posted fact table rows. Your options are either to rebuild the cube or send in a reversing entry before sending in the “good” row. In the case of the latter, think of your cube as a general ledger.
Item #10: Using SQL Profiler to Watch the Processing Commands
I've already talked about this in this article, but I'll emphasize the value of SQL Profiler in OLAP applications. Here are three instances under the OLAP context where you'll want to run a trace in profiler:
- Against a relational database source for an OLAP cube, when processing the cube (either with XMLA commands or with Visual Studio when rebuilding a project). This will allow you to see the T-SQL queries firing against the relational database source.
- Against a relational database source for an OLAP cube, when ROLAP is being used and users query the OLAP database. Again, this will allow you to see the T-SQL queries firing against the relational database source.
- Against the OLAP cube, when users query the OLAP database. This will allow you to see the MDX queries firing against the OLAP cube.
Item #11: Using XMLA for Backups
Although OLAP database backups are not always performed as frequently as relational database backups (because a database team can usually regenerate the SSAS OLAP cube from the project), XMLA provides a backup command to back up an SSAS database to a file. Listing 1 shows a basic example. Note that the default extension for Analysis Services backup files is ABF.
Listing 1: Performing a backup of an OLAP database using XMLA
<Backup xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object>
<DatabaseID>ADW_OLAP_XMLA</DatabaseID>
</Object>
<File>c:\OLAPBackups\ADW_OLAP_XMLA.ABF</File>
<AllowOverwrite>true</AllowOverwrite>
</Backup>
You can run this code manually in SQL Management Studio (while connected to the OLAP database), you could run it as a scheduled XMLA command in SQL Agent, or you could run it as an SSIS package (using the SSIS control flow task, the SSAS processing task).
Item #12: Using XMLA to Clear OLAP Caches
Analysis Services maintains an OLAP cache on the SSAS server.-It could be a regular OLAP cache for the default MOLAP (Multi-Dimensional OLAP) storage methodology, or even a ROLAP cache for relational pass-through. Periodically, it might be necessary to clear the cache, and Listing 2 provides an example. Just like with Listing 1, you can run this code in SSMS, as a Job, or as an SSIS package.
Listing 2: Clearing the cache for an OLAP database
<ClearCache xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object>
<DatabaseID>ADW_OLAP_XMLA</DatabaseID>
</Object>
</ClearCache>
Item #13: Using SSIS Scripts and .NET to Process Dimensions
So far, I've emphasized SSIS as a means of executing XMLA code. If you're in a situation where you need to execute XMLA code through .NET, you can use AMO (Analysis Services Management Objects). Listing 3 shows an example of C# code that creates an instance of an SSAS Server Object, and then passes XMLA code through the Execute method. Note that you'll need to add a reference to the namespace Microsoft.AnalysisServices.
Listing 3: .NET code to execute XMLA code
using Microsoft.AnalysisServices;
Server OlapServer = new Server();
OlapServer.Connect("Data Source = localhost\\sql2012");
string XMLACommand = "";
XMLACommand = "<Backup ";
XMLACommand += "xmlns=\"http://schemas.microsoft.com/";
XMLACommand += "analysisservices/2003/engine\">";
XMLACommand += "<Object>";
XMLACommand += " <DatabaseID>ADW_OLAP_XMLA</DatabaseID>";
XMLACommand += " </Object>";
XMLACommand += " <File>c:\\OLAPBackups\\ADW_OLAP_XMLA.ABF</File>";
XMLACommand += " <AllowOverwrite>true</AllowOverwrite>";
XMLACommand += "</Backup>";
OlapServer.Execute( XMLACommand);
OlapServer.Disconnect();
Website Recommendations:
There are several excellent website links with additional information on XMLA. I've read all the content in these links and I highly recommend them.
First, Karan Gulati (SSAS Maestro) has a very good link: http://blogs.msdn.com/b/karang/archive/2011/01/25/kind-of-ssas-processing-in-simple-words.aspx.
Second, Steve Hughes has an outstanding blog entry on XMLA: http://dataonwheels.wordpress.com/tag/xmla/.
Third, Daniel Calbimonte has a very interesting blog entry on generating XMLA dynamically using T-SQL. Those who need to generate XMLA dynamically but don't want to do it through .NET/C# code might find this particularly valuable: http://www.mssqltips.com/sqlservertip/2790/dynamic-xmla-using-tsql-for-sql-server-analysis-services/.
Finally, I've known companies over the years that wanted to build daily partitions. This was either because of a huge volume of data in the OLAP cube (over 15 million rows per day), or to isolate any subsequent processing to a single day. Analysis Services provides no native support for generating partitions dynamically, so developers must write script code. The steps are quite complicated, but three different developers have provided slightly different solutions. I've included the links for all three. I would highly recommend reading through them, and thoroughly designing any solution for dynamic partitioning, as this is a very complicated topic.
- http://sql-developers.blogspot.com/2010/12/dynamic-cube-partitioning-in-ssas-2008.html
- http://consultingblogs.emc.com/jamiethomson/archive/2008/09/15/ssis-create-analysis-services-partitions-from-a-ssis-package.aspx
- http://secretsql.wordpress.com/2011/02/06/ssas-dynamic-partition-processing/
Additionally, the great SSAS book written by Chris Webb, Alberto Ferrari, and Marco Russo (http://www.amazon.com/Expert-Development-Microsoft-Analysis-Services/dp/1847197221) has a section that covers dynamic partitioning.
| Command | Cube/Fact/Partition Tables | Dimension Tables |
|---|---|---|
| Process Full | Blows the cube/fact tables away and rebuilds from scratch (and re-generates structures) | Blows the dimension(s) away and rebuilds from scratch (and re-generates structures) |
| Process Update | N/A | Used to incrementally add/update dimension rows. Cannot be used for relationship changes to rigid attribute relationshipsSource does not need to represent all dataIt drops aggregations and indexes if updates lead to relationship changes, so they must be rebuilt using Process Index. |
| Process Default (some do not use this in production) | Brings tables to a "fully processed state" (often used in conjunction with other commands) | Brings tables to a fully processed state (often used in conjunction with other commands) |
| Process Index | Rebuilds aggregations (often after a process update) | Rebuilds indexes (often after process update) |
| Process Add (formerly Process Incremental) | Adds new fact rows, processes affected partitionsInserts new fact rows to the fact table/partition, and preserves existing fact rowsInternally translates to a Process AddDoes NOT check for duplicate fact rowsSource does not need to represent all data Fact rows CANNOT be updated | N/A |
| Process Data | Similar to Process Full - blows away all dataBut does not rebuild the structure | Similar to Process Full - blows away all dataBut does not rebuild the structureAdds new dimension rows (no updates)Does not update, does not drop aggregations/indexes |
| Process Clear (basically zaps the contents) | Clears all data in the `selected` object | Clears all Dimension Data |
