


Type providers are one of the most exciting reasons to use F#. They're a completely unique feature to F#, were first available in F#, and aren't available in any other common language. (As of this writing, Idris is the only other language known to have type providers). They make data access simple and development time blazingly fast, returning fully typed data to you, while eliminating huge amounts of boilerplate code, and freeing you from managing code generation and its associated artifacts. In fact, when the F# team first started thinking about ways to reference a database so that it was directly available in the code and already fully-typed, rather like a common library, they referred to this as “awesome typing.” This concept grew into type providers.
For my next couple of articles, I'll cover some of the most commonly used F# type providers in depth so that you can try them out yourself.
What are Type Providers?
Type providers make it possible to bring fully typed data directly into your code. They're efficient and eliminate a large amount of boilerplate code to set up a connection and type all the information that you want to consume. In a common scenario, using a type provider, it might take two-to-four total lines of code to set up, access, and return a set of data from a specific data source.
Let's look at a very simple example using FsLab to access a CSV file that contains a list of all the proposed US Constitutional Amendments, extract out the total number per year, and then plot a chart with this info.
First, some simple set up is required. You must reference and load the relevant packages, and define a path. In F#, a #load loads a file for use, and #r adds a reference. You then need to open some libraries that you've just included. Finally, you define the path to the CSV file.
#load "..\packages\FsLab\FsLab.fsx"
#r "XPlot.GoogleCharts.dll"
open FSharp.Data
open XPlot.GoogleCharts
[<Literal>]
let file =
__SOURCE_DIRECTORY__ +
"""\..\ConstitutionalData.csv"""
Once setup is completed, you're ready to access the data. Now, you'll get to experience the type provider in action. You first set up a new type, CsvFile, which contains the path, and a Boolean that keeps track of whether this file contains headers. In this case, there are headers. The next line of code accesses and processes the file. After this point, you're finished setting up the connection. You don't have to maintain any generated files; you didn't need to create a mountain of boilerplate code. You simply write these two lines, and you're now free to query, interact with, and explore the data.
type Csv = CsvProvider<file, HasHeaders=true>
let constitutionalData = Csv.GetSample()
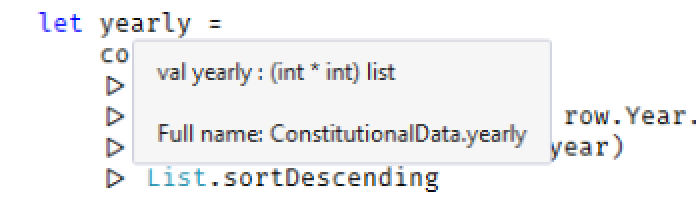
Now, let's extract the total number of amendments per year. This is easy to manage using a simple pipeline in F#. If you haven't seen this before, it's very similar to the concept of piping in both PowerShell and shell scripting. You simply take all the rows in the file and transform that information to a list. Then you use a List.choose to filter the rows that don't list a year for a proposed amendment. This operation takes a function that returns an Option type. The list that's returned contains the requested information (in this case, row.Year.Value) only in cases where that information exists. This is a very convenient way to filter for potentially nullable information and transform at the same time. After the List.choose operation, the CSV file has been reduced to a simple list of years. You then pipe to a List.countBy, which groups and counts each year, and finally, you sort the list. This sorts by earliest year. If you check out Figure 1, you'll see that yearly is a list of tuples, each containing two integers. You didn't need to define this information; the compiler was able to sort it out automatically.
let yearly = constitutionalData.Rows
|> Seq.toList
|> List.choose (fun row ->
if row.Year.HasValue then
Some(row.Year.Value)
else None)
|> List.countBy (fun year -> year)
|> List.sort
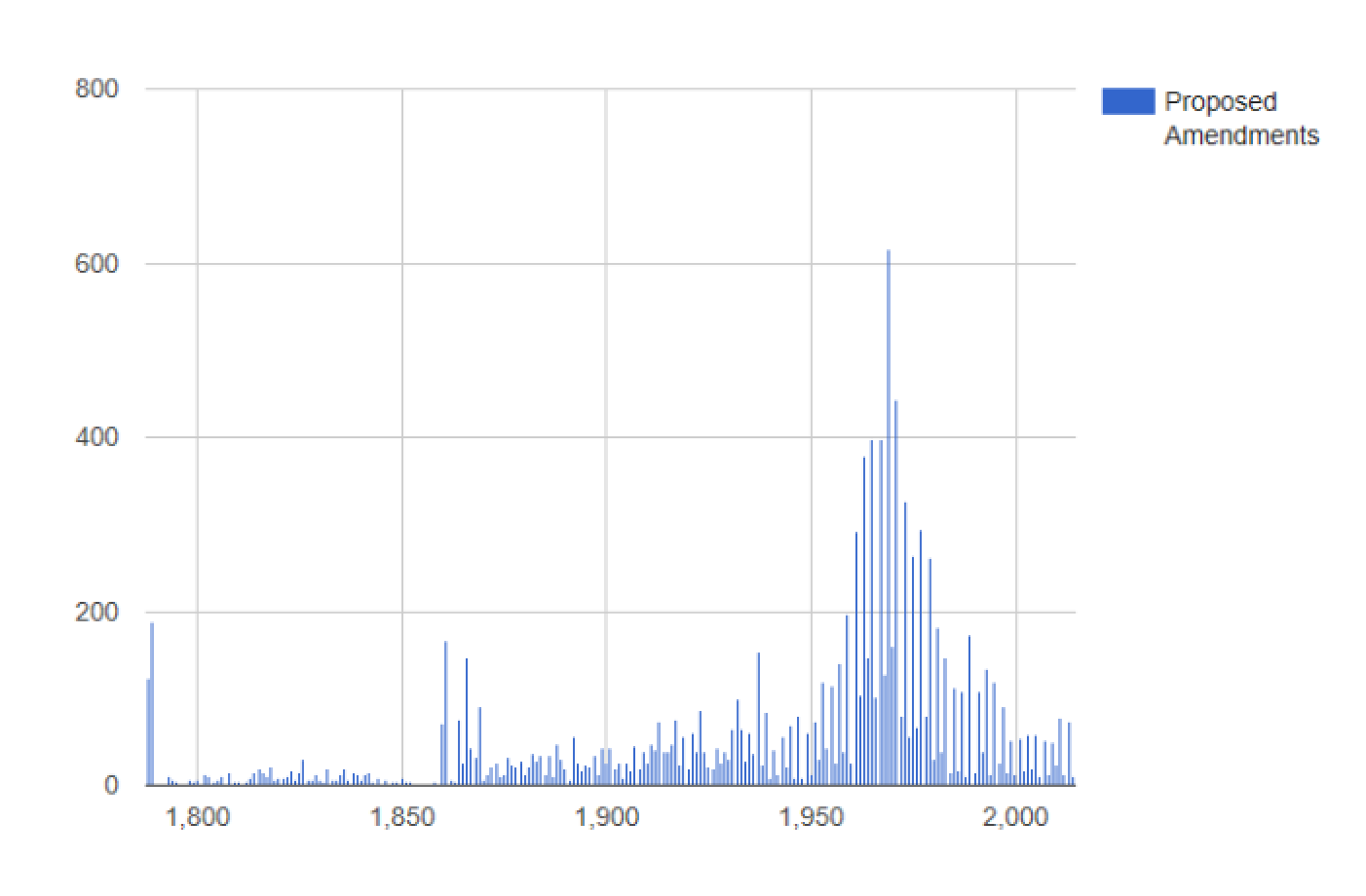
Now that you've manipulated the information, you can create a quick column chart to display the data, if you like. You simply take the list that you just defined and pipe that into a Chart.Column. There are additional options, such as WithLabel that you can add easily. This little bit of code generates the chart in Figure 2.
yearly
|> Chart.Column
|> Chart.WithLabel "Proposed Amendments"
You can see that type providers are a quick and easy way to manipulate, examine, and play around with your fully-typed data from within your program.
Commonly Used Type Providers
Let's look at a few of the most common type providers in use today. For this article, I'm going to focus on type providers for data science and machine learning applications - the World Bank, R, and CSV type providers - as well as an easy way to chart your data. In later articles, I will cover accessing SQL Server (there are enough options that it warrants a whole article in and of itself), as well as connecting to APIs using the Swagger, JSON, and XML type providers.
World Bank Type Provider
The World Bank type provider is possibly the easiest to use. It provides you with all the information that the World Bank tracks for every country in the world, such as infant mortality rates, GDP, percentage of the population with access to the Internet, and many, many more.
There are a couple of ways to start working with the World Bank type provider. If you're interested in focusing on this type provider, getting the FSharp.Data package from NuGet or Paket is the best choice. On the other hand, if you're interested in a much more comprehensible, data science and machine learning package, check out FsLab. For this article, I'll use FsLab.
Again, you create a quick F# script file. At the top, you need to load the FsLab script file, and open the FSharp.Data reference. Once you have that, you can skip the type declarations that you needed for the CSV type provider, and call WorldBankData.GetDataContext(). You're done now! You're all set up and ready to analyze the data from the World Bank.
#load "..\packages\FsLab\FsLab.fsx"
open FSharp.Data
let wb = WorldBankData.GetDataContext()
Let's start by returning a sequence with all the countries. It's super easy: just a single line.
let countries = wb.Countries
You can also get information for a specific country. Capital city, country code, name, and region are all readily available for each country.
let Uganda = wb.Countries.Uganda
It's also possible to browse the full list of topics that are available by choosing Indicators. See Figure 3.

The World Bank type provider is exciting enough on its own, but it becomes especially powerful when combined with other type providers. For example, the R type provider.
R Type Provider
The R type provider enables you to use all of the functionality of the R statistical computing and graphics language right from F#. Using the R type provider to analyze your data in F# is even easier than you might think, as it's also included in FsLab. Let's look at a quick example.
Using the R type provider to analyze your data in F# is even easier than you might think, as it's also included in FsLab.
First, you need to load the FsLab script file, and open several libraries related to R. In this case, you're going to use some data from the World Bank type provider, so you need to set that up as well. You'll again retrieve all of the countries (see Listing 1 for full code).
Listing 1: Combining the World Bank and R type providers
#load "..\packages\FsLab\FsLab.fsx"
open RDotNet
open RProvider
open RProvider.graphics
open FSharp.Data
let wb = WorldBankData.GetDataContext()
let countries = wb.Countries
let credit =
countries
|> Seq.map
(fun c -> c.Indicators.``Credit card (% age 15+)``.[2014])
let boone =
countries
|> Seq.map
(fun c -> c.Indicators.``Boone indicator``.[2014])
let coal =
countries
|> Seq.map
(fun c -> c.Indicators.``Coal rents (% of GDP)``.[2014])
let bankZScore =
countries
|> Seq.map
(fun c -> c.Indicators.``Bank Z-score``.[2014])
let data = ["Credit", R.c(credit);
"BooneIndicator", R.c(boone);
"CoalRents", R.c(coal);
"BankZScore", R.c(bankZScore)]
let df = R.data_frame(namedParams data)
R.plot(df)
Once you have all the countries, you'll want to retrieve a couple of indicators for each one. Start with getting the credit card usage for people over age 15. Do this by piping the countries into a Seq.map function, which returns the 2014 credit card usage numbers for each country.
let card (c:WorldBankData.ServiceTypes.Country) =
c.Indicators.``Credit card (% age 15+)``.[2014]
let credit = countries
|> Seq.map card
Next, return the Boone indicator for each country using the same method.
let boone = countries
|> Seq.map
(fun c -> c.Indicators.``Boone indicator``.[2014])
The cost of Coal rents, as a percentage of the GDP of each country.
let coal = countries
|> Seq.map
(fun c -> c.Indicators.``Coal rents (% of GDP)``.[2014])
And finally, the Bank Z-score for each country.
let bankZScore = countries
|> Seq.map
(fun c -> c.Indicators.``Bank Z-score``.[2014])
Once you have these four sequences, you're able to create a list that contains the sequences, processed with R into vectors, along with a name for the sequence itself. In R, the command to create a vector is c(), which stands for “combine”. So, you're combining each sequence, that is, “credit”, into a vector that R can use.
let data = ["Credit", R.c(credit);
"BooneIndicator", R.c(boone);
"CoalRents", R.c(coal);
"BankZScore", R.c(bankZScore)]
Next, you use the namedParams function that's available in RProvider.Helpers, to turn data into a data frame that R will easily work with.
let df = R.data_frame(namedParams data)
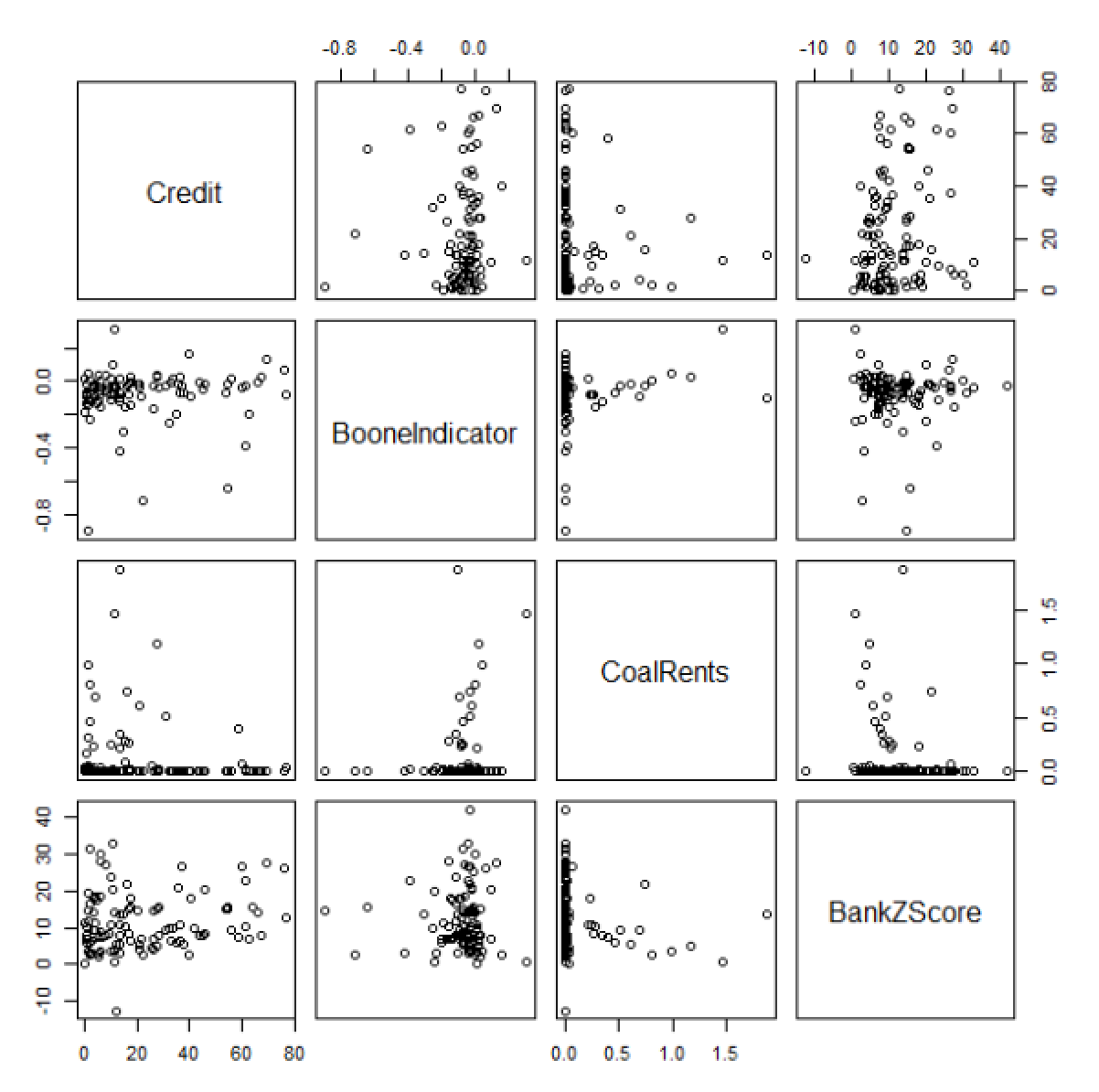
Finally, call R.plot, passing the data frame. In a mere 43 lines of code, you've accessed, processed, and charted the data using two separate type providers. Check out Figure 4 to see what this chart looks like.
R.plot(df)
CSV Type Provider
You looked at a quick example of the CSV type provider above, but let's look a little deeper this time. You'll look at data from two separate CSV files and analyze and combine them to learn more about airline landings at SFO (San Francisco), using data from http://www.flysfo.com/media/facts-statistics/air-traffic-statistics. This data is grouped by month, and contains information for every airline that's landed a plane at SFO since August 2005. The data captures aircraft type, numbers of passengers, international versus domestic, and terminal information, among other things. I'll skip over the setup details this time, but for the full code, see Listing 2.
Listing 2: Using the CSV type provider to access airline data
#load "..\packages\FsLab\FsLab.fsx"
#r "XPlot.GoogleCharts.dll"
open FSharp.Data
open XPlot.GoogleCharts
open System
[<Literal>]
let passengerPath =
__SOURCE_DIRECTORY__ +
"""\..\MonthlyPassengerData.csv"""
type PassengerFile = CsvProvider<passengerPath, HasHeaders=true>
let Passengers = PassengerFile.GetSample()
// parse airlineMonth from yyyymm
let processDate (month:int) =
let year =
Convert.ToInt32(month.ToString().[0..3])
let newMonth =
Convert.ToInt32(month.ToString().[4..5])
new System.DateTime(year, newMonth, 01)
let deplaned, enplaned =
Passengers.Rows
|> Seq.toList
|> List.partition
(fun row -> row.``Activity Type Code`` = "Deplaned")
let organizeData _
(datalist:CsvProvider<passengerPath, HasHeaders=true>.Row list)=datalist
|> List.groupBy (fun row -> row.``Activity Period``)
|> List.map
(fun (month,rows) ->
(processDate month,
rows |> List.sumBy (fun r -> r.``Passenger Count``)))
let monthlyDeplaned = organizeData deplaned
let monthlyEnplaned = organizeData enplaned
[monthlyDeplaned; monthlyEnplaned]
|> Chart.Column
|> Chart.WithLabels ["Deplaned"; "Enplaned"]
To initialize the type provider, you need to define the path to the CSV file, create a type that you'll use for data access, and call GetSample(). Once these steps are complete, you're ready to use the data.
[<Literal>]
let passengerPath =
__SOURCE_DIRECTORY__ +
"""\..\MonthlyPassengerData.csv"""
type PassengerFile = CsvProvider<passengerPath, HasHeaders=true>
let Passengers = PassengerFile.GetSample()
For the first case, you want to chart the total passengers who've arrived and departed per month. First split the data set into two groups: deplaned and enplaned. Do this by taking all rows in the CSV file, creating a list of them, and partitioning that list in two, based on whether or not the Activity Type Code column is “Deplaned”. Note how F# allows you to define both lists at once. This is the concept of destructuring assignment.
let deplaned, enplaned = Passengers.Rows
|> Seq.toList
|> List.partition
(fun row -> row.``Activity Type Code`` = "Deplaned")
Now you want to take these two sets and organize the data a little better. Create a function that returns a list of months with a total passenger count for each month. To achieve this, first group the rows by month. This returns a tuple that contains a month and a list of rows. Finally, tally all the passengers in that list of rows for the specific month, and call our organizeData function for both lists of passengers.
let organizeData dataList = dataList
|> List.groupBy (fun row -> row.``Activity Period``)
|> List.map
(fun (month,rows) -> (processDate month, rows
|> List.sumBy (fun r -> r.``Passenger Count``)))
let monthlyDeplaned = organizeData deplaned
let monthlyEnplaned = organizeData enplaned
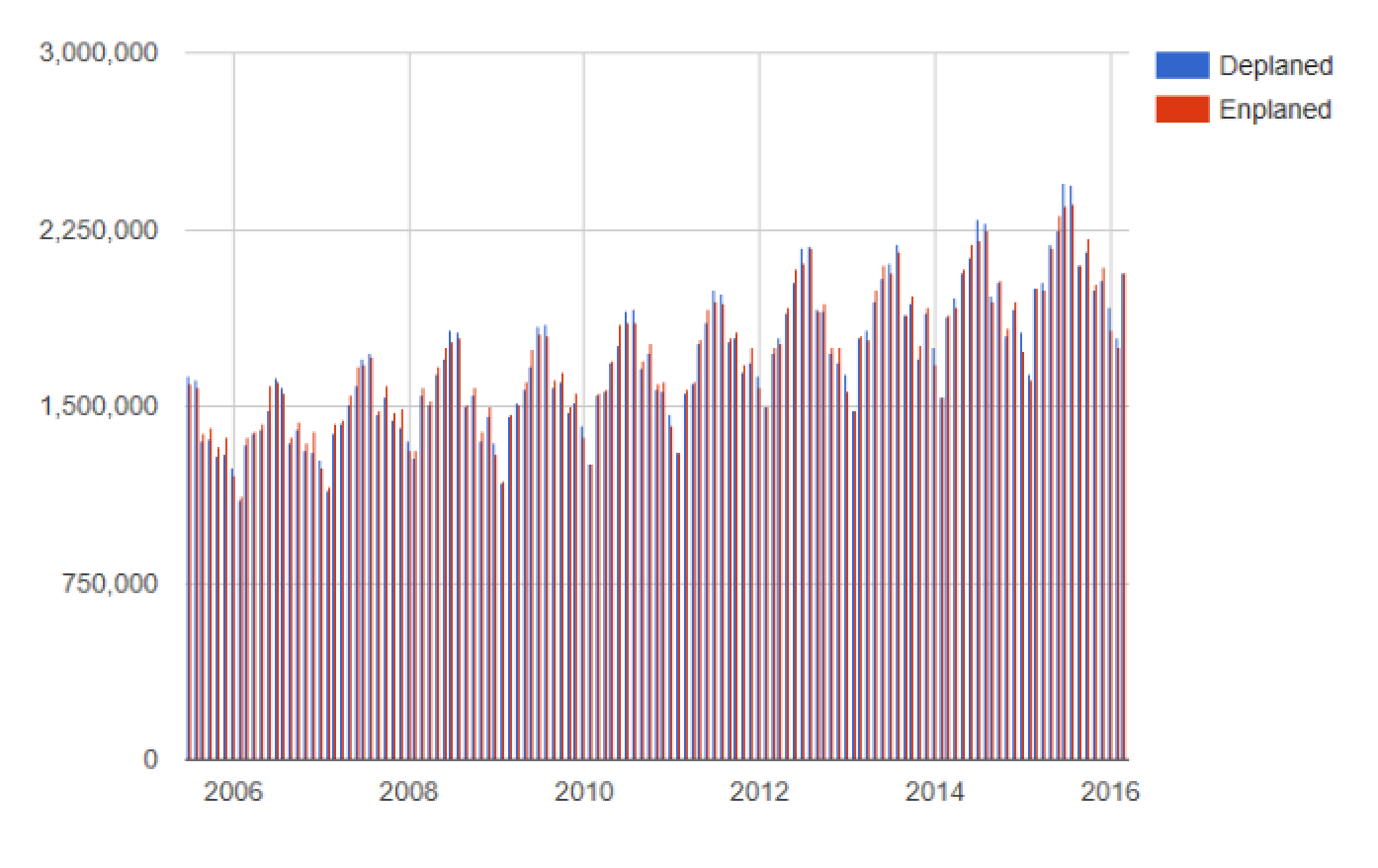
To achieve this, you needed to define the countPassengers helper function (see the full code in Listing 2). Now, you're done processing the data, and you're ready to chart it. Let's use a column chart, and include labels for each series set of data. This creates a chart such as Figure 5.
[monthlyDeplaned; monthlyEnplaned]
|> Chart.Column
|> Chart.WithLabels ["Deplaned"; "Enplaned"]
Now, for fun, let's try one more thing. Let's add a second file, MonthlyLandingsData. From this file, extract the number of landings per airline, and then calculate the ratio of passengers per landing, by airline. Then, chart that result on a multi-line chart to show who has the highest each month. So first, you again need to reference the file using the CSV type provider. You define the path, use it to create the new type, and finally call GetSample() for the type.
[<Literal>]
let landingsPath =
__SOURCE_DIRECTORY__ +
"""\..\MonthlyLandingsData.csv"""
type LandingsFile = CsvProvider<landingsPath, HasHeaders=true>
let Landings = LandingsFile.GetSample()
Next, let's get the data into a format that you can use. First, get the count of passengers per month, per airline. Do this by using the Passengers CSV file, and grouping by the Activity Period and Operating Airline columns. Then, take this grouped data, and return a triple, containing the month (again processed with the processDate function), the airline name, and the sum of the passenger count for that month and airline.
let monthlyPassengers = Passengers.Rows
|> Seq.toList
|> List.groupBy
(fun row ->
row.``Activity Period``,
row.``Operating Airline``)
|> List.map
(fun ((month,airline),rows) ->
(processDate month,
airline,
rows
|> List.sumBy
(fun r -> r.``Passenger Count``)))
You similarly process the Landings CSV file with a few additional steps. Filter for freight aircraft because you're looking for passenger flights. Then group by the Activity Period and Operating Airline columns again, so that you have a similar set of information. This time, however, you construct a tuple that contains a tuple of the month, airline information, and the count of all the landings in that month for that airline. You then create a dictionary type from that outer tuple by simply piping to dict.
let monthlyLandings = Landings.Rows
|> Seq.toList
|> List.filter
(fun row -> row.``Landing Aircraft Type``<>"Freighter")
|> List.groupBy
(fun row -> row.``Activity Period``,
row.``Operating Airline``)
|> List.map
(fun ((month,airline),rows) ->
((processDate month, airline),
rows |> List.sumBy
(fun r -> r.``Landing Count``)))
|> dict
Now, you need to combine the two sets of data. Let's examine the following code one line at a time.
let airlineList, monthlyPassLandRatioList = monthlyPassengers
|> List.choose (fun row -> combinePassenger row)
|> List.map
(fun (m,a,p,l) -> (m,a,float p/float l))
|> List.groupBy (fun (m,a,r) -> a)
|> List.map
(fun (a,groupedByAirline) -> (a, processGroups groupedByAirline))
|> List.unzip
First, you're again using destructuring assignment to individually label two separate items in a returned tuple.
let airlineList, monthlyPassLandRatioList =
Next, you're taking the list of passengers per month, and calling List.choose. This takes a function that returns an option type. In cases where the function results in a result, that result is returned. If the result is None (which is similar to a null in C#), the result is filtered out of the returned list. This operation both maps and filters all in one. It's a super useful function to know!
monthlyPassengers
|> List.choose (fun row -> combinePassenger row)
The combinePassenger function handles the combining of the two data sets. You're destructing a single row, which is a triple, from the monthlyPassengers list into the month, the airline, and the passenger count. Then you use the month and airline information to perform a dictionary lookup (using the findLandings function, below, that performs a dictionary lookup on the landings count information). It's returning an Option type here. If there's a result for the landings information, it returns a quadruple containing the month, the airline, the passenger count, and the landings count. Otherwise, it returns None. The result of the call to List.choose is a list containing the above quadruples, where all of the None values have been filtered out.
let combinePassenger row =
let m,a,p = row
let success = findLandings m a
if success.IsSome then
Some(m, a, p, success.Value)
else
None
let findLandings month airline =
let (success, result) =
monthlyLandings.TryGetValue((month,airline))
if success then
Some(result)
else
None
Now, take that list of quadruples and transform it into a list of triples, containing the month, airline, and a ratio of passenger count to landing count.
|> List.map
(fun (m,a,p,l) -> (m,a,float p/float l))
Next, group that list of triples by airline. The list, at this point, is a list of tuples, each one containing the airline, and a list of all the triples that contain that airline.
|> List.groupBy (fun (m,a,r) -> a)
After this, it's necessary to perform another map. You deconstruct the tuples and transform only the second term (the triple containing the month, airline, and ratio) in the tuple, using the groupedByAirline function. This removes the airline information from the triple. This makes sense since you're now grouping by that piece.
|> List.map
(fun (a,groupedByAirline) ->
(a, processGroups groupedByAirline))
let processGroups airlineList = airlineList
|> List.map (fun (m,_,r) -> (m,r))
Finally, perform a List.unzip, which separates the list of tuples into two lists: one containing the first field and one containing the second. You finally have the two lists: monthlyPassLandRatioList and airlineList.
|> List.unzip
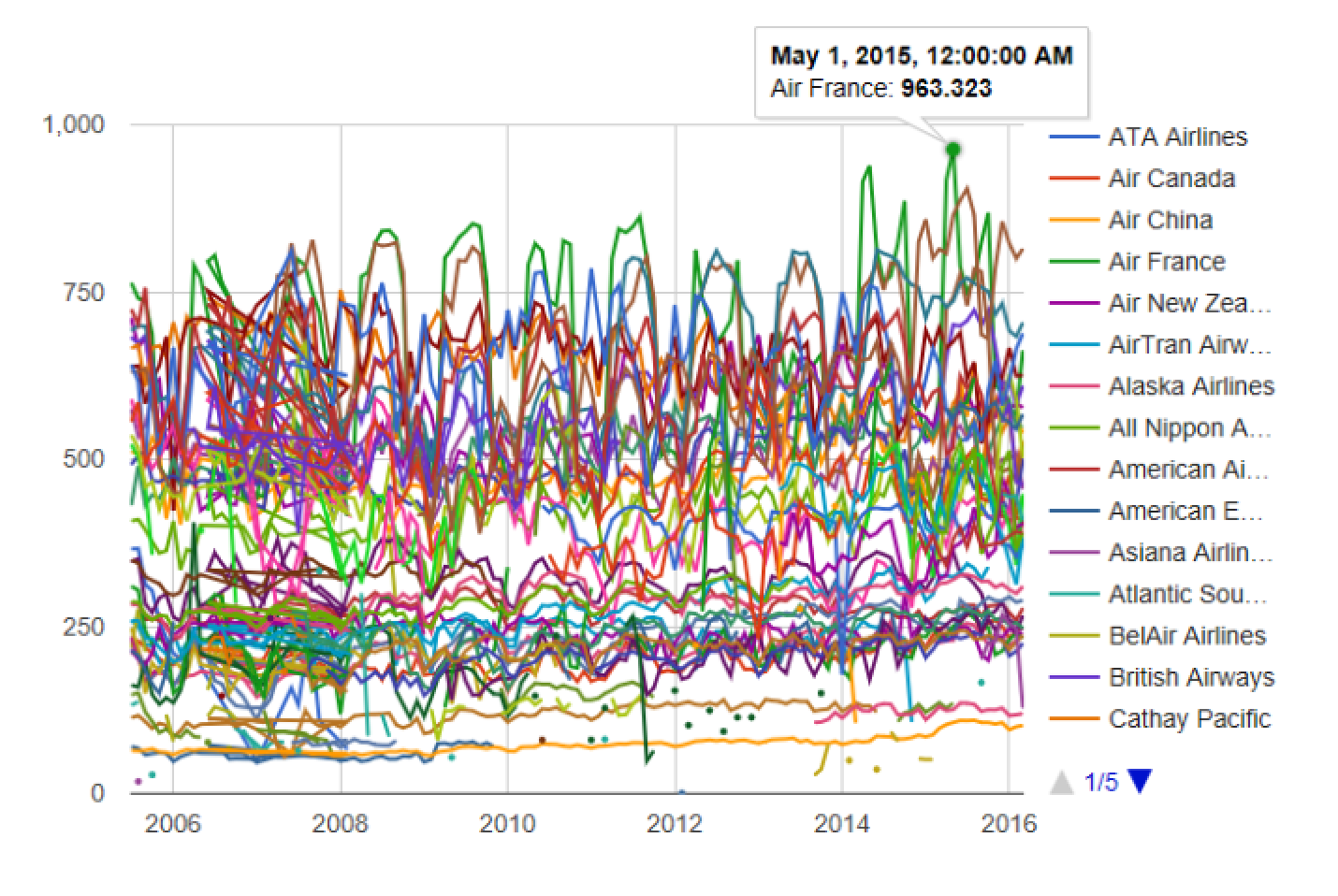
Now that you've finished setting up the data, creating a quick chart is a trivial pursuit: You simply take the monthlyPassLandRationList, and convert it into a line chart using the list of airlines as the labels. See the full code sample in Listing 3 and the chart in Figure 6.
monthlyPassLandRatioList
|> Chart.Line
|> Chart.WithLabels airlineList
Listing 3: Combining the data from two CSV files, using the CSV type provider
#load "..\packages\FsLab\FsLab.fsx"
#r "XPlot.GoogleCharts.dll"
open FSharp.Data
open XPlot.GoogleCharts
open System
[<Literal>]
let landingsPath =
__SOURCE_DIRECTORY__ +
"""\..\MonthlyLandingsData.csv"""
type LandingsFile = CsvProvider<landingsPath, HasHeaders=true>
let Landings = LandingsFile.GetSample()
let monthlyPassengers = Passengers.Rows
|> Seq.toList
|> List.groupBy
(fun r -> r.``Activity Period``,r.``Operating Airline``)
|> List.map
(fun ((month,airline),rows) ->
(processDate month, airline, rows
|> List.sumBy (fun r -> r.``Passenger Count``)))
let monthlyLandings = Landings.Rows
|> Seq.toList
|> List.filter
(fun row -> row.``Landing Aircraft Type`` <> "Freighter")
|> List.groupBy
(fun r -> r.``Activity Period``,r.``Operating Airline``)
|> List.map
(fun ((month,airline),rows) ->
((processDate month, airline), rows
|> List.sumBy (fun r -> r.``Landing Count``)))
|> dict
let findLandings month airline =
let (success, result) = monthlyLandings.TryGetValue((month,airline))
if success then
Some(result)
else
None
let combinePassenger row =
let m,a,p = row
let success = findLandings m a
if success.IsSome then
Some(m, a, p, success.Value)
else
None
let processGroups airlineList =
airlineList |> List.map (fun (m,_,r) -> (m,r))
let airlineList, monthlyPassLandRatioList = monthlyPassengers
|> List.choose (fun row -> combinePassenger row)
|> List.map (fun (m,a,p,l) -> (m,a,float p/float l))
|> List.groupBy (fun (m,a,r) -> a)
|> List.map
(fun (a,groupedByAirline) -> (a, processGroups groupedByAirline))
|> List.unzip
monthlyPassLandRatioList
|> Chart.Line
|> Chart.WithLabels airlineList
Where to Learn More
There's a wealth of information surrounding type providers available online. Many type providers have been open sourced (including all three that I covered in this article), which means that you can review their documentation and code on GitHub. The CSV and World Bank type providers are available as part of FSharp.Data, which you can find here: https://github.com/fsharp/FSharp.Data. The R type provider is available here: https://github.com/fslaborg/RProvider.
