


In the last issue (January/February 2017), I covered how easy it is to work with F# type providers specifically for data science. This time, I'll back up a little and show you just how easy it is to simply access (and still work with!) most data that you'll come across. You'll see examples for accessing XML, JSON, and APIs that use the new Swagger type provider. In a future issue, I'll write an entire article covering the options for SQL Server, so get ready!
XML Type Provider
Working with XML is super easy when you have the XML type provider on hand. I happen to have a data set that shows the Powerball winning lottery numbers for the State of New York Lottery from February 2010 through January 2017. Let's see how the most common numbers chosen in each month differ. First, because it's a script file, you'll need to include your references and open statements. To use the XML type provider, you'll need FSharp.Data, as well as System.Xml.Linq, because the type provider makes use of XDocument internally. I'm also using Microsoft.VisualBasic, because it has a few nice Date functions that the other languages don't have.
#r "../packages/FSharp.Data/lib/FSharp.Data.dll"
#r "System.Xml.Linq.dll"
#r "Microsoft.VisualBasic.dll"
open FSharp.Data
open Microsoft.VisualBasic
Once these are in place, you connect to the data. It's a quick two lines: you simply tell the type provider where the data can be found and then call GetSample(). You could also have used a document that's an example of the data and then used the Parse method on the full data.
type Names = XmlProvider<"../numbers.xml">
let names = Names.GetSample()
That's it! You're ready to use the data, which has the following form:
<row _id="931"
_uuid="ABE7162C-2AB8-4CF1-B7DD-00D473BC7960"
_position="931"
_address="http://data.ny.gov/resource/931">
<draw_date>2017-01-04T00:00:00</draw_date>
<winning_numbers>
16 17 29 41 42 04
</winning_numbers>
<multiplier>3</multiplier>
</row>
Now, check out Figure 1, and note how the type provider gives you that data.
It's not clear from Figure 1 or from the data, but the winning numbers are returned all together as a string. Before you can do much with them, you'll need to parse them into an array of numbers. This is easily done by splitting the string and converting each result to an integer, like so:
let parseNumbers (nums:string) =
nums.Split(' ')
|> Array.map (fun n -> n |> int)
Now that you've created the parseNumbers function, it's time to start forming your results. Let's call this results. You can request all the rows of the data using names.Rows, and then use an Array.map to select only the data you're looking for from the XML file: the month that the numbers were drawn and the numbers themselves parsed into an array. Once that's in place, you can group by the month and then sort so they're in the correct order.
let results =
names.Rows
|> Array.map
(fun r ->
(r.DrawDate.Month,
parseNumbers r.WinningNumbers))
|> Array.groupBy (fun (m, n) -> m)
|> Array.sort
This gives you a result like Listing 1.
Listing 1: Results of lottery data after parsing numbers, grouping by month, and sorting.
val results : (int * (int * int []) []) [] =
[|
(1,
[|(1, [|18; 22; 37; 47; 54; 36|]);
(1, [|22; 26; 32; 38; 40; 7|]);
...
|]);
(2,
[|(2, [|17; 22; 36; 37; 52; 24|]);
(2, [|14; 22; 52; 54; 59; 4|]);
...
|]);
(3,
[|(3, [|7; 9; 14; 45; 49; 23|]);
(3, [|10; 29; 33; 41; 59; 15|]);
...
|]);
...
...
|]
However, now you need to clean up and combine all the sub-arrays so that you can more meaningfully interact with your data. Let's create a combineNumbers function to handle them. I'll walk through it line-by-line for some clarity.
let combineNumbers data = data
|> Array.collect
(fun (month, nums) -> nums)
|> Array.countBy id
|> Array.sortByDescending
(fun (num, count) -> count)
|> Array.map (fun (n,c) -> n)
I started by sending the data to an Array.collect. This runs the function on each item in the array and then collects and concatenates the resulting sub-arrays. This removes the extra month information and gathers all the lottery numbers into one large array.
data
|> Array.collect
(fun (month, nums) -> nums)
Next, I count the numbers. Because there's only one term per item in the area, there's no need to use an explicit countBy function; id will suffice. The result here is an array of tuples: the count and the lottery number.
|> Array.countBy id
Next, I sort by the count to return the highest chosen numbers in that month.
|> Array.sortByDescending
(fun (num, count) -> count)
Finally, I remove the count and return only the numbers.
|> Array.map (fun (n,c) -> n)
Now I can take the combineNumbers function and add another step to the results computation. In this last step, I'll map the month and numbers to a proper month name string, and I'll use the combineNumbers function to clean up the sub arrays and take just the top three lottery numbers that were returned.
let results = names.Rows
|> Array.map
(fun r ->
(r.DrawDate.Month,
parseNumbers r.WinningNumbers))
|> Array.groupBy (fun (m, n) -> m)
|> Array.sort
|> Array.map
(fun (m, data) ->
(DateAndTime.MonthName(m),
(combineNumbers data).[0..2]))
The final result looks like this!
val results : (string * int []) [] =
[|
("January", [|47; 19; 28|]);
("February", [|17; 11; 36|]);
("March", [|14; 8; 12|]);
("April", [|33; 29; 39|]);
("May", [|23; 31; 9|]);
("June", [|22; 33; 18|]);
("July", [|3; 11; 38|]);
("August", [|12; 28; 4|]);
("September", [|17; 22; 39|]);
("October", [|20; 10; 1|]);
("November", [|17; 37; 5|]);
("December", [|10; 14; 19|])
|]
JSON Type Provider
The JSON type provider is similar to the XML type provider. Here, too, you can point the type provider to a full data set, an example data set, or a URL that returns the results in JSON. This time, I'll show an example of making a call to an API that returns JSON. I'll use the Broadband Speed Test API to get some state averages for download speeds for a few different places (libraries, home, mobile, etc.) and then compare those to the national averages. Finally, I'll chart the numbers.
You've always got to start with your references and open statements. In this case, you need to load the FsLab scripts, and reference the GoogleCharts dll. You also need to open the GoogleCharts library.
#load "../packages/FsLab/FsLab.fsx"
#r "XPlot.GoogleCharts.dll"
open XPlot.GoogleCharts
Next, you can set up the two type providers. You'll need two separate instances because you're making two separate calls. I've chosen to call mine BroadbandStates and BroadbandNation. Then you call GetSample(), just like the XML type provider, and you're ready to go.
let statesUrl =
"https://www.broadbandmap.gov/broadbandmap/" +
"speedtest/state/names/arizona,maine," +
"wyoming,california,tennessee?format=json"
let nationUrl =
"https://www.broadbandmap.gov/broadbandmap/" +
"speedtest/nation?format=json"
type BroadbandStates = JsonProvider<statesUrl>
type BroadbandNation = JsonProvider<nationUrl>
let bbStates = BroadbandStates.GetSample()
let bbNation = BroadbandNation.GetSample()
Working with the national data is a little easier, so let's start there. You'll need to access the results, and then use Array.map to find the two points of data that you need: AccessingFrom, and MedianDownload. Check out Figure 2 to see all the options available.
let nationResults = bbNation.Results
|> Array.map
(fun a -> (a.AccessingFrom, a.MedianDownload))
Next, you'll set up the state results in a similar manner, as in the next snippet. This time, you'll need to return the GeographyName as well as the AccessingFrom and MedianDownload, and then, because the goal is to find the percent difference in the average download speed as compared to the national average download speed, you'll want to group by state.
bbStates.Results
|> Array.map
(fun a ->
(a.GeographyName,
a.AccessingFrom,
a.MedianDownload))
|> Array.groupBy (fun (state, from, down) -> state)
After this code runs, the stateResults and nationResults values look like Listing 2.
Listing 2: NationResults and StateResults data. Note that each set of state information needs to line up with the national information in order for the Array.map2 function to work properly.
val nationResults : (string * decimal) [] =
[|("Business", 8.85742M);
("CC_library_school", 9.98828M);
("Home", 6.70215M); ("Mobile", 2.12891M);
("Other", 3.97627M); ("Small_Business", 4.39063M)|]
val stateResults : (string*(string*string*decimal)[])[] =
[|("Arizona",
[|("Arizona", "Business", 8.73516M);
("Arizona", "CC_library_school", 9.66016M);
("Arizona", "Home", 7.45703M);
("Arizona", "Mobile", 2.18652M);
("Arizona", "Other", 6.51075M);
("Arizona", "Small_Business", 4.30176M)|]);
("California",
[|("California", "Business", 8.85303M);
("California", "CC_library_school", 18.33496M);
("California", "Home", 6.13222M);
("California", "Mobile", 2.58984M);
("California", "Other", 2.51492M);
("California", "Small_Business", 3.19922M)|]);
("Maine",
[|("Maine", "Business", 10.89160M);
("Maine", "CC_library_school", 8.88086M);
("Maine", "Home", 5.34131M);
("Maine", "Mobile", 1.89844M);
("Maine", "Other", 4.80187M);
("Maine", "Small_Business", 4.35449M)|]);
("Tennessee",
[|("Tennessee", "Business", 7.91162M);
("Tennessee", "CC_library_school", 8.63184M);
("Tennessee", "Home", 7.31219M);
("Tennessee", "Mobile", 2.42871M);
("Tennessee", "Other", 1.72534M);
("Tennessee", "Small_Business", 4.95801M)|]);
("Wyoming",
[|("Wyoming", "Business", 4.32042M);
("Wyoming", "CC_library_school", 6.40321M);
("Wyoming", "Home", 3.86426M);
("Wyoming", "Mobile", 1.20020M);
("Wyoming", "Other", 2.28906M);
("Wyoming", "Small_Business", 2.59903M)|])|]
Next, you need a helper function to handle calculating the averages for each state. I've called it findAverages. Let's look a little closer at that one. I take the data and use an Array.map2, which takes two arrays as inputs and performs a map on them, using their respective elements. For example, generically, Array.map2 might look like this:
Array.map2
(fun array1value array2value ->
array1value + array2value)
array1 array2
Or, of course, like this:
array2
|> Array.map2
(fun array1value array2value ->
array1value + array2value)
array1
The arrays must be the same length and conveniently, now each state sub-array is the same length as the array of national data. It's also useful here to pre-emptively destructure the tuple and triple in each array. Your findAverages function will look like this:
let findAverages data =
data
|> Array.map2
(fun (nfrom, ndown) (geo, sfrom, sdown) ->
(geo, sfrom, sdown/ndown*100M |> int))
nationResults
Once you have the averages, you want to re-group by the location (home, office, etc.) so that you can chart the data, and then remove the duplicated location information. Now, let's put this together.
bbStates.Results
|> Array.map
(fun a ->
(a.GeographyName,
a.AccessingFrom,
a.MedianDownload))
|> Array.groupBy
(fun (geo, from, down) -> geo)
|> Array.collect
(fun (geo, data) -> findAverages data)
|> Array.groupBy
(fun (geo, from, down) -> from)
|> Array.map
(fun (from, data) -> (from, sortData data))
In that snippet, sortData is the function that removes the duplicated location information.
let sortData (data:(string*string*int)[]) =
data
|> Array.map
(fun (geo, from, down) -> geo, down)
There's one last step to process the state data. You'll have an array of tuples here: a string value (the location information), and an array of tuples that are a string (the state) and an integer (percent difference to national value). Let's unzip this array, using the location information for the labels on the chart, and use compound assignment to set both values at once. You have, finally:
let labels, stateResults = bbStates.Results
|> Array.map
(fun a ->
(a.GeographyName,
a.AccessingFrom,
a.MedianDownload))
|> Array.groupBy
(fun (geo, from, down) -> geo)
|> Array.collect
(fun (geo, data) -> findAverages data)
|> Array.groupBy
(fun (geo, from, down) -> from)
|> Array.map
(fun (from, data) -> (from, sortData data))
|> Array.unzip
Now, to create a chart of all the data at once, you need to specify which type of chart each group of data should be. In this case, you'll want all bar charts.
let series = ["bars"; "bars"; "bars"; "bars"; "bars"; "bars"]
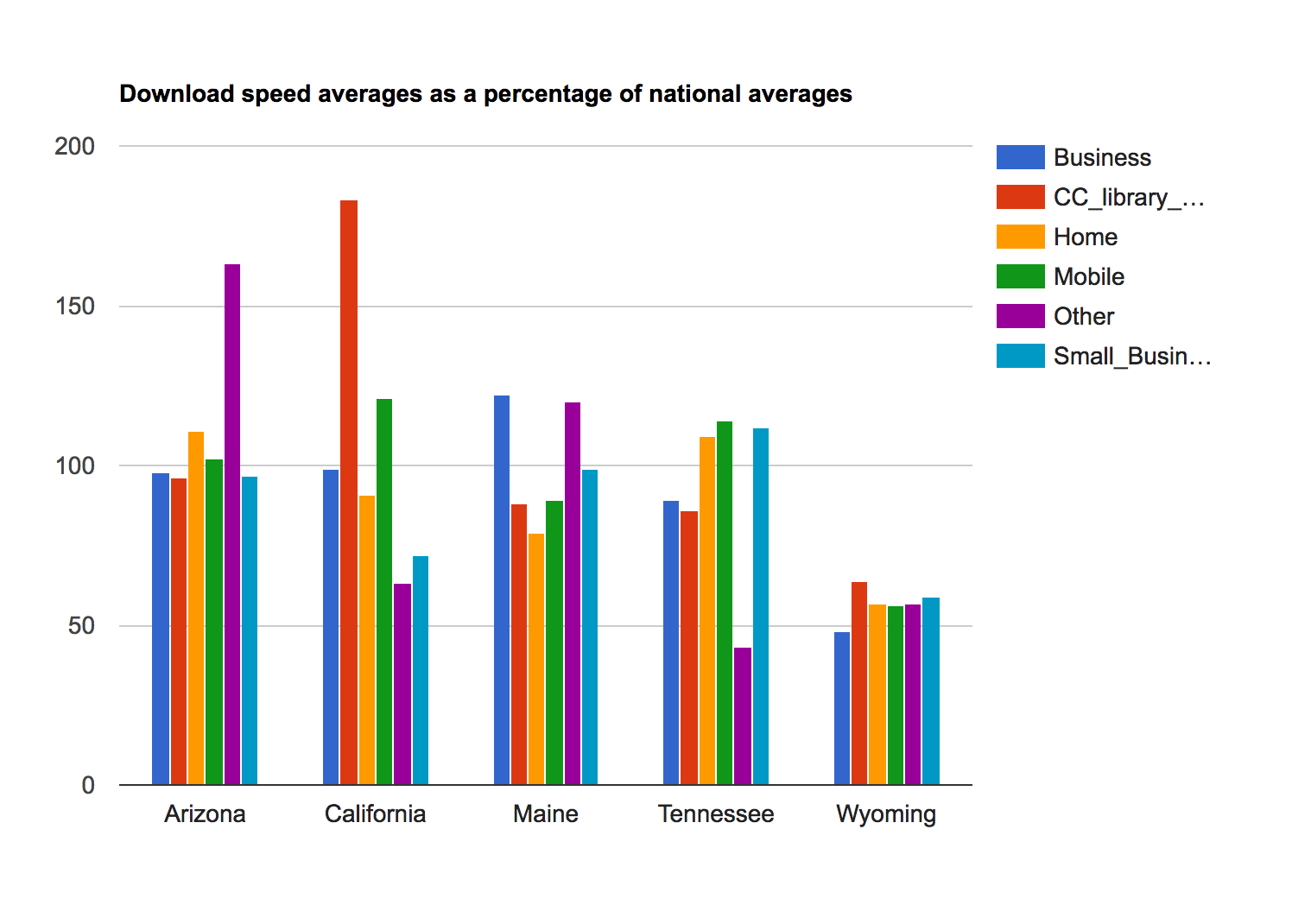
Finally, let's chart those results. I used a combo chart, added a title, and used the series information to set each chart up as a bar chart. I added the labels information and a legend. Voila! See Figure 3 for the final chart.
stateResults
|> Chart.Combo
|> Chart.WithOptions
(Options(
title = "Download speed averages as a
percentage of national averages",
series = [| for typ in series -> Series(typ) |]))
|> Chart.WithLabels labels
|> Chart.WithLegend true
The JSON type provider is fantastic, but it does mean that you need to set up each individual call separately. To solve this problem, let's take a look at the Swagger type provider.
Swagger Type Provider
First, what is Swagger? It's a formal specification that ensuring that your API is documented in a human-readable and a machine-readable way, with minimal fuss. Using Swagger for your APIs is the new hotness right now, and this means you can take advantage of the several APIs that use Swagger, via the Swagger type provider. You'll have quick, full access to the entire API!
Using Swagger for your APIs is the new hotness right now.
I've written up a short script that uses the New York Times API to read their top headlines for the Travel section, and then does a bit of processing on the words in the article abstracts, using the Oxford dictionary API, in order to determine how many words are used. Let's take a look!
Much the same as in the previous examples, you need to specifically call out your references and open statements. You need to reference the SwaggerProvider, which can be loaded with either Paket or Nuget. I also make a habit of keeping my API keys in a separate file so that I don't accidentally make them public. For this bit of code, you need to reference System.Text.RegularExpressions and System.Threading.
#load "../packages/Swagger/SwaggerProvider.fsx"
#load "keys.fs"
open SwaggerProvider
open keys
open System.Text.RegularExpressions
open System.Threading
Next, let's connect to the Oxford dictionary API. Using the SwaggerProvider, it's a matter of pointing the type provider at the Swagger definitions for the API and creating an instance for use.
[<Literal>]let oxfordApi =
"https://api.apis.guru/v2/specs/" +
"oxforddictionaries.com/1.4.0/swagger.json"
type Oxford = SwaggerProvider<oxfordApi>
let oxford = Oxford()
Connecting to the New York Times API is slightly more complicated. You need to create the same three lines of set up, but the New York Times requires the API key to be passed as part of the headers, so you have to use CustomizeHttpRequest to add it. After this, the two type providers act in the same way.
[<Literal>]
let topStoriesApi=
"https://api.apis.guru/v2/specs/" +
"nytimes.com/top_stories/2.0.0/swagger.json"
type TimesNYC = SwaggerProvider<topStoriesApi>
let timesNYC = TimesNYC()
timesNYC.CustomizeHttpRequest <-
fun req -> req.Headers.Add("api-key", keys.nytimes); req
Now that you've set up your connection to the APIs, it's time to get some data. Let's start by finding the top stories for the “Travel” section of the paper, in JSON format.
let topStories = timesNYC.Get("travel", "json", "")
That's it! You'll receive a response in JSON format similar to Listing 3, contained in a TimesNYC.GetResponse object. Now, check out Figure 4, and compare. The topStories value contains an array of Result objects. For each of the results, you have IntelliSense access to all of their properties: Abstract, Byline, CreatedDate, etc. Using type providers, if you weren't sure in advance what the result type looked like, you could call the API and just explore. There's no need to guess.
Listing 3: Resulting JSON from calling the New York Times API
{
"status": "OK",
"copyright": "Copyright (c) 2017 The New York Times Company.
All Rights Reserved.",
"section": "travel",
"last_updated": "2017-01-05T13:15:06-05:00",
"num_results": 23,
"results": [
{
"section": "Travel",
"subsection": "",
"title": "Hotels and Resorts to Travel to in 2017",
"abstract": "Sometimes a hotel is just a place to sleep.
Other times, it's a destination.",
"url": "http://www.nytimes.com/2017/01/05/travel/
hotels-and-resorts-to-travel-to-in-2017.html",
"byline": "By ELAINE GLUSAC",
"item_type": "Article",
"updated_date": "2017-01-05T01:22:18-05:00",
"created_date": "2017-01-05T01:22:19-05:00",
"published_date": "2017-01-05T01:22:19-05:00",
"material_type_facet": "",
"kicker": "",
"des_facet": [
"Hotels and Travel Lodgings",
"Eco-Tourism",
"Spas",
"Travel and Vacations",
"Swimming Pools"
],
"org_facet": [],
"per_facet": [],
"geo_facet": [],
"multimedia": [
{
"url":"https://static01.nyt.com/images/2017/
01/08/travel/08LODGING1/08LODGING1-thumbStandard.jpg",
"format":"Standard Thumbnail",
"height": 75,
"width": 75,
"type": "image",
"subtype": "photo",
"caption": "New hotel on Kokomo Island, Fiji.",
"copyright": "Small Luxury Hotels of the World"
},
],
"short_url": "http://nyti.ms/2j6NFrS"
}
...
Using type providers, if you aren't sure in advance what the result type looks like, you can call the API and just explore.
The goal, again, is to count the number of unique non-proper noun words used in the abstracts. You need to access the abstracts and then to split them up by words. This original array has 309 items in it, so make sure that the words are distinct. Let's also sort the list, for good measure.
topStories.Results
|> Array.collect (fun r -> r.Abstract.Split(' '))
|> Array.distinct
|> Array.sort
This returns a rather messy set of data, with punctuation, dates, and proper nouns that aren't going to be in the dictionary, as you can see in Listing 4.
Listing 4: First pass of words contained in the abstracts of the top travel articles. The length of this array is 213 and, clearly, it needs some cleanup.
val results : string [] =
[|"$12"; "100,000"; "125th"; "12th"; "150th"; "200th";
"2017"; "2017,"; "2017."; "20th"; "350th"; "A"; "Abu";
"Alliance"; "America"; "America's"; "Amsterdam";
"Auditorium."; "Austen,"; "Australia."; "Bahamas";
"Beijing"; "Big"; "Canada,"; "Canadian"; "Cape";
"Chicago"; "Club"; "Cup"; "Dhabi,"; "Dozens"; "Every";
"Five"; "For"; "From"; "Glimmers"; "Go"; "Harry";
"Here"; "Highlands,"; "Holland"; "Hoxton"; "In";
"Jane"; "Jonathan"; "Like"; "Line"; "London"; "Med,";
"More"; "Musical"; "New"; "Other"; "Places"; "Potter";
"Researchers"; "Ryman"; "Saskatoon,"; "Scottish";
"Sometimes"; "Swift"; "Tapawingo"; "The"; "This";
"Town"; "Travel"; "With"; "a"; "abound"; "activities";
"aid"; "airline"; "airlines"; "airplane"; "airport";
"airways"; "all"; "allowing"; "along"; "alternatives";
"among"; "an"; "and"; "anniversary"; "annual"; "answers";
"anticipating"; "apps"; "apps."; "are"; "areas"; "art";
"as"; "aspects"; "attempt"; "attended"; "authors";
"author's"; "avalanches"; "balancing"; ...|]
You need to clean this up a bit before you can make use of the Oxford API. Let's define a simple cleanup method, using a regular expression to filter out any “words” that have numbers or a few special characters. If the word doesn't have any of the offending characters, there might still be some associated punctuation, so it's a good idea to remove that as well. The return type here is an Option type, which I've used in previous articles. This forces you to check whether the data is valid before being able to use it.
let cleanup (text:string) =
if Regex.IsMatch(text,@"[0-9''$/ - ]") then
None
else
Some(text.Replace(",","")
.Replace(".","")
.Replace("?","")
.Replace(""","")
.Replace(""",""))
You'll need to insert a call to your cleanup function, like so:
topStories.Results
|> Array.collect (fun r -> r.Abstract.Split(' '))
|> Array.choose (fun a -> cleanup a)
|> Array.distinct
|> Array.sort
This helps to clean up your list of words quite a bit. You're down to 197 total items. But there are still some repetitions. For example, the list contains both “airline” and “airlines,” which are really the same word. This is how the Oxford API can help you out. They provide a “Lemmatron” call, which will lemmatize your words for you. If you've not heard the term before, lemmatization replaces each word with its most basic form, without any extra prefixes or suffixes. So, both “airline” and “airlines” return the more basic form, “airline.” You can still count them as one word!
Let's go through the code in Listing 5 line by line to create the findLemmas function.
Listing 5: The findLemmas function
let findLemmas word =
try
oxford.GetInflections(
"en",
word,
keys.oxfordId,
keys.oxfordKey)
.Results
|> Array.collect (fun r -> r.LexicalEntries)
|> Array.filter
(fun l -> l.GrammaticalFeatures.[0].Text <> "Proper")
|> Array.collect (fun l -> l.InflectionOf)
|> Array.map (fun l -> Some(l.Id))
|> Array.head
with
| ex -> None
Because you've already set up your connection to the Oxford API, you just need to make the call to the GetInflections method. This requires you to send along the language (“en” for English), the specific word you want to look up, and your credentials for calling the service. Rather than setting a value for the call and requesting the results in the next step as you did for the New York Times, it's easy enough to define the value as including the step into Results from the start. You're also starting a try-with block (similar to a try-catch block in C#) that you'll complete later.
let findLemmas word =
try
oxford.GetInflections(
"en",
word,
keys.oxfordId,
keys.oxfordKey)
.Results
The Oxford API returns an array that's perfect to send through a pipeline. First, you want to map each result to the interior array of lexical entries. This returns an array because one spelling might mean several different things, even different types of speech. The API returns information for each one. By using Array.collect, the result type is an array, rather than an array of arrays, because it concatenates the resulting arrays.
|> Array.collect (fun r -> r.LexicalEntries)
Next, let's filter the proper nouns.
|> Array.filter
(fun l -> l.GrammaticalFeatures.[0].Text <> "Proper")
Now it's time for the Oxford API to reveal whether the word is in its most basic form or not by calling InflectionOf. An inflection is a word that contains, for example, a different tense, person, or case, than the most basic form. This tells you what your word is an inflection of.
|> Array.collect (fun l -> l.InflectionOf)
Next, InflectionOf returns both an ID and text, so you should take the ID (which is the lemmatized word) for each of the lexical entries that were returned. Again, you want to use an Option type to force a check for null data.
|> Array.map (fun l -> Some(l.Id))
Finally, you return the first item in the array.
|> Array.head
Now, it's time to complete your try-with block. In this case, it's easiest to drop every word where there's a problem, so you blanket catch all exceptions and return None.
with
| ex -> None
Now, you just need to add a call to your findLemmas function, like so:
topStories.Results
|> Array.collect (fun r -> r.Abstract.Split(' '))
|> Array.choose (fun a -> cleanup a)
|> Array.distinct
|> Array.sort
|> Array.map (fun w -> findLemmas w)
There's one problem in calling the Oxford API. They limit calls to 60 requests per minute. Because this code will request way over 60 items in a few milliseconds, the API responds by truncating the request to 60, and throwing errors for the rest. No good! You'll need to create one more function, one that splits your array into chunks of 60 words, waiting a minute between sending each group. Let's call it splitToFindLemmas.
Because this code requests way more than 60 items in a few milliseconds, the API responds by truncating the request to 60, and throwing errors for the rest. No good!
let splitToFindLemmas (wordArray:string[]) =
let size = 60
[|for start in 0..size..wordArray.Length-1 do
if start <> 0 then Thread.Sleep 60000
let finish =
if start+size-1 > wordArray.Length-1 then
wordArray.Length-1
else
start+size-1
yield
wordArray.[start..finish]
|> Array.choose (fun w -> findLemmas w)|]
|> Array.concat
Let's look at this line by line again, starting with the declaration. You might have noticed that I needed to declare the type of the incoming parameter. F# has type inference, but every now and then it needs a little push. I found that in this set of code, I needed to specifically declare this type. There also tend to be two camps of F# programmers: Those who declare all types for clarity and those who omit as many types as possible for conciseness. Both are good options, I just happen to side with #TeamConcise. If you side with #TeamClarity, this is how you set up your declarations.
let splitToFindLemmas (wordArray:string[]) =
Next, I declare a size value. It's not necessary, but it helps keep the code a little cleaner, because you refer back to it a few times.
let size = 60
Most of the rest of the code is an array comprehension that is started with this next line. I'm declaring a value, start, which runs from 0 to the last item in the array, with steps determined by size, which is, in this case, 60.
[| for start in 0..size..wordArray.Length-1 do
Next, a quick check. You need to sleep for a minute between each call, but there's no need to sleep for the first one. In F#, everything is an expression, and all paths of an if statement need to return the same type. In this case, you don't need an else statement because Thread.Sleep returns unit().
if start <> 0 then Thread.Sleep 60000
Next up, I set up a finish value, which is the lesser of the array's upper bound or the next step.
let finish =
if start+size-1 > wordArray.Length-1 then
wordArray.Length-1
else
start+size-1
Finishing off the array comprehension, I yield a slice of the array from the start value to the finish value and then call the findLemmas function for each of the words in that slice.
yield
wordArray.[start..finish]
|> Array.choose (fun w -> findLemmas w)|]
Finally, I concatenate each of the slices, so that I only return one array.
|> Array.concat
Now that that's all sorted, you return to your topStories pipeline and can add a quick call to sortToFindLemmas and another call to Array.distinct to remove the duplicates that lemmatization has created, and you're all finished! You have a final count of 104 unique words used in travel abstracts in the New York Times' top stories.
topStories.Results
|> Array.collect (fun r -> r.Abstract.Split(' '))
|> Array.choose (fun a -> cleanup a)
|> Array.distinct
|> Array.sort
|> sortToFindLemmas
|> Array.distinct
Where to Learn More
Many of the type providers that I shared with you today are available as part of the FSharp.Data project: XML, HTML, and JSON. You can find more information and documentation about them here: https://github.com/fsharp/FSharp.Data. The Swagger type provider has also been open sourced, and more information is available here: http://fsprojects.github.io/SwaggerProvider/.
