


In the September/October 2017 issue of CODE Magazine, I wrote a Baker's Dozen (13 Productivity Tips) article on ETL Practices in Data Warehousing environments. Soon, I intend to follow that article up and provide examples of the practices discussed in the first article. Meanwhile, I want to answer some follow-up questions I've received. Some people have emailed me or approached me at speaking events where I also discuss this topic, and raised some very good points that I want to cover here.
Has someone ever asked you a question and your first reaction was, “Wow, that's a great question, and I never thought to word it that way!” In the last month, two individuals asked me about identifying the mistakes that people make in building data warehouse and DW/ETL applications. For as much as I wrote about repeatable practices in my first article, I could have covered this specific question as well. I've made mistakes in my career and I've seen mistakes in other applications. In some instances, the mistakes are quite clear. In other cases, the mistake is part of a complicated situation where maybe increased awareness or foresight could have led to a better outcome. So, I'm going to cover some of the mistakes I've seen in this area.
I've been writing for CODE Magazine since 2004. I probably worked harder on the article I wrote in the September/October 2017 issue than any other article in over a decade. The subject matter of ETL in Data Warehousing is very deep, and the topic is one that is immensely personal for me as well. Borrowing from Meg Ryan's character in the movie “You've Got Mail,” I've always thought that making things personal isn't necessarily a bad idea: That's where passion comes from, and some things ought to begin by being personal!
Having said that, after reading the article again, I realize that there were some points I want to amplify, and a few points I neglected to raise. So, I'll take some time and cover these points.
After I wrote this latest article, I asked myself the question that every writer should always ask: Who is your intended audience for this article? That reminded me of a story. (Anyone who knows me knows I'll always jump at the chance to use some random piece of trivia.)
This is a story about the great baseball player, Willie Mays. One night, his long-time manager Leo Durocher asked him a series of questions related to in-game strategies: “It's the bottom of the ninth and the score is tied. We've got a runner on third and one out. The current batter is in an 0-20 hitting slump, and the pitcher is this-and-this-and-that. What should the manager do?” Mays quickly replied, “I'm a ballplayer, that's the manager's job.” Durocher responded that Mays needed to appreciate these situations to gain a better understanding of the game, that it would ultimately make him a complete player. Later Mays credited Durocher with helping him to see that point.
So why am I mentioning this? To this day, there are debates about heads-down programmers versus developer/analysts, waterfall methodologies versus the Agile/Sprint world, etc. Willie Mays' initial response to his manager might seem like a perfectly appropriate response for a heads-down programmer who reads this article. (Before I continue, I don't use the term “heads-down” programmer in any disparaging way. I'll get to that shortly).
A programmer who prefers to work from specs might read this article and respond, “OK, there's some interesting stuff here, but honestly this sounds like it's more for managers and tech leads, and I'm a programmer”.
Fair enough: At different stages of my career, I wanted to just write code and build apps and let others work with the business side. But I came to realize that this kind of insularity just isn't practical when developing data warehouse and business intelligence applications. Perhaps in certain areas of IT that are focused on scientific/engineering/systems software, being a heads-down programmer is perfectly fine, but in the world of business applications, it's not. Every aspect of data warehousing is about context. Programmers will admit that even the best and most complete specification can't include every major circumstance, every factor that goes into some aspect of the data and how users will work with it. A programmer needs to understand all the nuances of source data. A programmer needs to understand that various business people don't necessarily have the same understanding of a piece of data. A programmer needs to understand both the system and user dependencies.
In other words, a programmer needs to at least appreciate what a team lead or manager is responsible for. Remember, the average turnover rate in this industry is less than two years. You might think that you're “just a ballplayer” this year, but next year you might be thrust into the role of a team lead or player-coach. The more versatility you can show, the more valuable you'll be.
Every aspect of data warehousing is about context.
Some technical programmers who work from specifications might not initially feel they have a compelling need to understand this information today. I'd argue that I once felt that way, but came to realize that I was missing a big part of the picture. Everyone on the data warehouse team, from the programmers to tech leads to architects to QA managers, needs to understand the big picture.
What's on the Menu?
Here are the six topics for today:
- Common mistakes in ETL applications
- Operational Data Store (ODS) Databases
- Capacity Planning
- Using Change Data Capture and Temporal tables in Data Warehousing
- Data Lineage documentation
- Discussion topic: Do you need technical skills to identify business requirements?
#1: Common Mistakes in Data Warehousing and ETL Applications
If you search the Web for “Why Data Warehousing Projects fail”, you'll see many online articles and blog posts with stories about failed projects. Projects can fail for many reasons, technical and non-technical, strategic and tactical, etc.
There's enough information available to fill a book on this topic, so I won't get into all the reasons a project can fail. For that matter, a project can succeed in the sense that the team meets core deadlines and delivers base functionality, but the application might still fall well short of an optimal outcome. Here are some of the mistakes that tend to occur in Data Warehousing and DW/ETL projects, in no order of importance:
- Insufficient Logging
- Insufficient time spent vetting and testing the incremental extract process
- Insufficient time spent profiling the source data
- Not having a full understanding of the transactional grain (level of detail) of all source data
- Not taking enough advantage of newer technologies
- Less than optimal SQL code in the ETL layer
- Uneasiness/challenges in getting the business to agree on rules
- Not retaining historical data
- Building a solution that works but doesn't get used
- Not using the Kimball model (or any model) and not using accepted patterns
- Not running ideas by team members
Let's examine each of these points:
Insufficient Logging: In my previous article, I stressed the importance of logging all activity in the ETL application. This includes capturing information on extracts from the data source, loading into the staging area, and populating the eventual data warehouse model. The team needs to think about everything they might want to know about an overnight ETL job that occurred three nights ago. When you design logging processes, you're essentially writing the context for your history. Just like viewers of the TV show “The Brady Bunch” are accustomed to hearing, "Marcia, Marcia, Marcia!", people on my data warehousing team have come to learn my corollary, “Log, Log, Log!”
Insufficient time spent vetting and testing the incremental extract process: If extracts from the source systems aren't accurate or reliable, the contents of the data warehouse are going to be incorrect in some way. Even a few missed invoices or cost records because of some data anomaly or unexpected issue can impact user/business trust of the data warehouse.
There's a corollary here as well: Insufficient time was spent profiling the source data. The degree to which you know the source data, including source system behavior, how it handles timestamps, etc., will likely be the degree to which you can design an effective and reliable extract strategy. There's the old line about police officers needing to be right every time, and criminals only needing to be right one time. The same thing holds true for data warehouse incremental extracts from source systems: You need to be right every time.
Not having a full understanding of the transactional grain (level of detail) of all source data: I can't stress enough that if you don't have a firm understanding of the grain and cardinality of the source data, you'll never be able to confidently design extract logic.
Not taking enough advantage of newer technologies: I've known very solid developers who write bug-free code, and yet their applications don't take advantage of newer features in SQL Server for performance. This is more of an issue for architecture leads who need to evaluate newer database enhancements to determine whether the team can leverage them. As one example, the optimized In-Memory OLTP Table capability (first introduced in SQL 2014 and greatly enhanced in 2016) can potentially increase staging table processing by a factor of two to three times, or greater.
True, a slow but reliable application is far better than a fast one with flaws. Additionally, we all know that implementing newer functionality for performance carries risks that need to be tested. Still, it helps to pay close attention to what Microsoft adds to the database engine.
Less than optimal SQL code in the ETL layer: I see this one often, and admittedly I fall victim to this, too, if I'm not careful. Because many DW/ETL operations occur overnight and can take hours, there's a tendency to adopt a “well, so long as the whole thing runs between midnight and 4 AM, we're good” mindset. To this day, I see people using SQL CURSOR logic to scan over a large number of rows, when some refactoring to use subqueries instead and maybe some ranking functions would simplify the code and enhance performance. Never hesitate to do code/design reviews of SQL queries in your ETL!
Uneasiness/challenges in getting the business to agree on rules: I've seen good developers and even team leads who are uneasy about approaching either the business side or even the technical leaders of a legacy source system when they see inconsistencies in business requirements. Here's the bottom line: This is not the time to be shy. If necessary, vet your questions among the team members to make sure you're asking a solid question with good foundation.
There's the story about a team who discovered that two different segments of business users had been using two different definitions for what constituted capital finished goods, based on different process and disposition rules. The DW team was apprehensive about approaching either team to discuss differences/discrepancies. Should the organization follow one uniform rule for finished material, or could the organization carry forward two rules with distinct names and contexts? You'll never know until you raise the issue. Believe me, if you fail to raise the issue, you shouldn't expect someone else to raise it. Once again, this is not the time to be shy. As someone once observed about Hugh Laurie's character in the TV show House, “House thinks you're being timid - that's the worst thing to be, in his book.”
Not retaining historical data: Here's a cautionary tale that every data warehouse person should remember. Years ago, a company wanted to do a complete refresh of data from the source systems. Unfortunately, the source system had archived their data, and as it turned out, some of the backup archives weren't available. (Yes, the situation was a mess). Had the ETL processes retained copies of what they'd extracted along the way before transforming any of the data in the staging area, the data warehouse team might not have needed to do a complete refresh from the source systems. If you're a DBA, you're probably feeling your blood pressure rising over the thought of storage requirements. Yes, good data warehouses sometimes need high storage capacity.
Building a solution that works but doesn't get used: OK, we've all built an application that wound up sitting on the shelf. It happens. But when it happens in the same company or with the same team multiple times, you need to look for reasons. My teams prototype and work directly with users every step of the way. I make sure that no more than two weeks pass without some meaningful demo of where we are with respect to getting new data into the data warehouse. The demos reflect, as much as possible, how we believe users will ultimately access the application. We seek sanity checks constantly. At times, I probably drive the business people crazy with communications. There's never a guarantee that the business will use the system in the intended fashion: but managing the development of a project is about taking the right incremental steps along the way. Having said that, Agile methodologies, Sprint processes, and frequent and meaningful prototypes are only tools and approaches. By themselves, they don't guarantee success.
In short, when users don't use the final product, quite likely there were serious communication gaps along the way.
Agile methodologies, Sprint processes, and frequent meaningful prototypes are tools and approaches. By themselves, they don't guarantee success.
Not using the Kimball model (or any model) and not using accepted patterns: I've seen failed or flawed implementations of fact/dimensional models and ETL modules written by some (otherwise) very skilled database developers who would have fared much better had they been carrying some fundamentals in their muscle memory. Always remember the fundamentals!
Not running ideas by team members: Even with demanding project schedules, I set aside a few hours on Friday afternoons for my team to share ideas, talk through issues, etc. It's an open forum. During our morning scrum meetings, if someone has a technical or design issue they want to talk about, we table it for Friday afternoon. I'm fortunate that I have very good team members with whom I look forward to collaborating. Team chemistry is a complicated topic and I certainly don't claim to have all the answers, but I've learned over time that you have to bring your “best self” into these meetings. When a data warehouse is only understood by a subset of the team members because other members weren't involved in talking through specifics, ultimately some aspect suffers.
#2: Operational Data Store (ODS) Databases
In my prior DW/ETL article (September/October 2017 CODE Magazine), I showed a figure similar to Figure 1: a very high-level topology/roadmap for a Data Warehouse architecture. I've updated Figure 1 from that article to include an optional but sometimes key component: an operational data store.
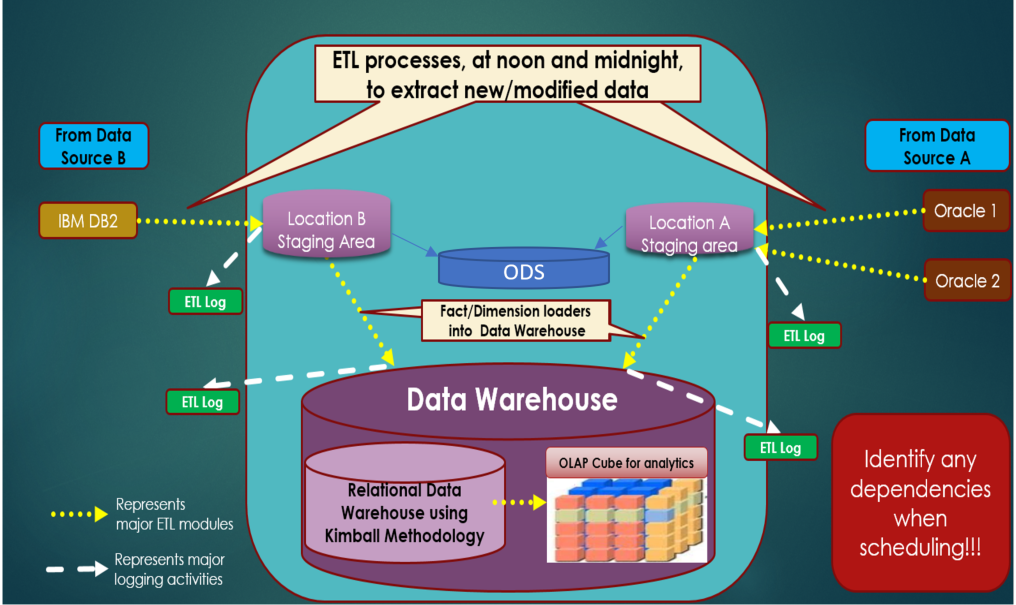
I've used the joke many times about 10 economists presenting 10 different economic models, where it can be difficult to tell whose model makes the most sense. In the same manner, you could present technical requirements to 10 data warehouse professionals and easily get the same number of approaches.
When I presented Figure 1 in the previous article, I talked about ETL processes reading data from the source systems into a staging area, and then from the staging area into the data warehouse. Well, sometimes a company might introduce what's called an operational data store (ODS) into the picture, either in addition to the data warehouse or, in some cases, in lieu of the data warehouse. You can think of an ODS as an intermediary, or “middle-tier” storage area: a stepping-stone along the way toward a data warehouse. There are several reasons a company might do this, and here are two that I've experienced first-hand:
- You might implement an ODS if the source system offers little or no transactional/operational reporting. As a result, you might implement transactional daily “flash” reporting out of the ODS, and then more comprehensive analytic queries from the data warehouse.
- You might implement an ODS if you have multiple staging areas for different source systems, and want to use a single common intermediary area as the source for the data warehouse. Additionally, an ODS can simplify verification queries when the staging areas contain many complex tables.
#3: Capacity Planning
I have an opinion on Capacity Planning (a document for anticipated system growth over three-to-five years and projected hardware/storage costs): No one ever accurately predicts the actual capacity in advance. It's a matter of whether you're in the ballpark or out in the next county.
At the end of 2017, I updated a capacity planning document I built in 2015. My original numbers were off, although not horribly so, and I was generally able to defend what I accounted for two years earlier. Having said that, there were still lessons learned. So, when determining the anticipated growth of your databases, factor in these four items:
- Any new or anticipated subject matter data, data feeds, etc.
- Backups
- Historical/periodic snapshots
- Redundant information in staging areas and operational/intermediary areas
First, account for any new or anticipated subject matter data, data feeds, etc. Granted, if 12 months from now the business asks you to incorporate a data feed that no one's discussing today, you can't account for what you don't know. Having said that, try to know as much as you can. Try to find out if company executives have any interest in seeing new data.
Second, take backups into account. Take a measure of how many backups you want to retain on your server (for easy restoration), and your backup policy in general.
Third, take historical snapshots into account. If you're taking complete or partial snapshots every month (for accounting/reporting purposes, Sarbanes-Oxley requirements, etc.), remember that those snapshots take up space.
Finally, make sure to factor in redundant information in staging areas and operational/intermediary areas. Remember that storing legacy data in one of your data stores adds to your physical storage requirements.
I maintain a spreadsheet of all items to account for, and I've learned to periodically review the contents (along with database growth patterns) with my team. One suggestion is to have a quarterly meeting to review capacity planning.
#4: Change Data Capture and Temporal Tables and Their Place in the Data Warehouse Universe
At some point in the Data Warehouse process, either reading from source systems or loading into the data warehouse or somewhere in between, developers want to capture “what got changed and what got added.” Sadly, developers also have to deal with “what got deleted,” even though we all know that the best systems flag transactional rows for deletion (or send reversing entries) but don't physically remove them.
Certainly, capturing what was inserted and updated isn't unique to data warehousing: Many applications need to store audit trail logs and version history so that you can see who added/changed data and when.
Until SQL Server 2008, the only way you could capture changes in SQL Server was to do one of the following:
- Implement database triggers to capture inserted/updated/deleted data.
- Implement logic in stored procedures (or in the application layer) to capture inserted/updated/deleted values.
- Purchase a third-party tool, such as SQLAudit.
All of them worked, although each solution harbored challenges to keep an eye on. Database triggers are very reliable, but they're a very code-intensive solution and can introduce performance issues if you're not careful. Implementing logic in stored procedures or the application layer can also work, even though it means that every module writing to the database must adhere to the logic. Third-party tools can provide excellent functionality, yet you can encounter licensing challenges and possibly other challenges from using a solution that isn't as configurable as you'd like.
Some criticized Microsoft for not providing a built-in solution in the database engine to capture and store changes. Those criticisms reflected that in SQL Server 2005, the Microsoft database platform was OK for medium-sized databases, but it lacked the core functionality needed in data warehousing circles. Even though I've loved SQL Server from day one, those critics had a valid point.
Fortunately, Microsoft responded with functionality in SQL Server 2008 called Change Data Capture (CDC). For years, Microsoft only made CDC available in the Enterprise Edition of SQL Server, but relaxed that restriction and included CDC in Service Pack 1 of SQL Server 2016 Standard Edition. CDC monitors the transaction log for database DML operations, and writes out a full log of the before/after database values to history tables that you can query. Because it scans the transaction log asynchronously, you don't need to worry about additional processing time for the original DML statement to execute. CDC is an outstanding piece of functionality that provides database environments with a reliable way of capturing changes with very little code.
If you want to learn more about CDC, I wrote about it back in the September/October 2016 issue of CODE Magazine. Here is the link to the article: (specifically, look at Tips 3 and 4) http://www.codemag.com/Article/1009081/The-Baker's-Dozen-13-More-Examples-of-Functionality-in-SQL-Server-2008-Integration-Services.
Also, I created a webcast on CDC back in January of 2014. If you navigate to my website (www.KevinSGoff.net), and go to the Webcast category on the right, you'll see a list of webcasts, including the one on CDC.
In 2016, Microsoft added a second piece of functionality called temporal tables. At first glance, temporal tables seem like “CDC-light.” Temporal tables collect changes to data and write out version history to a history table. I wrote about temporal tables in the September/October 2016 issue of CODE Magazine (specifically, Tip #9): http://www.codemag.com/Article/1609061/The-Baker's-Dozen-13-Great-Things-to-Know-About-SQL-Server-2016.
I'm not going to promote one feature over another, as each has its place. A good data warehouse architect should be aware of these features, what they provide, and what they don't provide (at least out-of-the-box). So here are six things to keep in mind.
First, if the source system is a database system with no audit trail history and no way to capture changes, all you can do to extract data from a source system is to have a reliable means of detecting inserts/updates based on the management of the last update/timestamp values in the source data.
Second, source systems might have their own version/implementation of CDC. CDC, in itself, is not a Microsoft-specific invention; other databases, such as DB2, have had CDC for years. The question is whether the source system uses it, and whether there are any rules that they've already defined for it. Once again, ETL developers need to know as much as possible about that source system.
Third, you can use CDC in your middle layer if you're persisting transactional history in your staging or ODS layer. For instance, you might extract 1,000 invoices from the source system and merge them into your staging area. Maybe 100 invoices are new (based on the invoice key), 200 are existing invoices where some non-key field has changed, and 700 invoices are ones you already have in your intermediate layer where no values changed. You can use CDC to capture the 100 new invoices (and the old/new values of the 200 updated invoices), and send just those values to the data warehouse model (or whatever the next phase is in the process).
Fourth, as a follow-up on that last point, even if you're not using CDC, you could use the T-SQL MERGE to insert/update those 100 new and 200 changed rows (and ignore the 700 that didn't change), and OUTPUT the information to some destination yourself. Having said that, you'd have to implement/maintain the logic yourself that checks all non-key fields for changes. Some shops might build an engine that generates MERGE statements using metadata to automate this.
Fifth, some developers who evaluate SQL Server 2016 wonder if the new temporal tables feature (and support for versioning history) in SQL Server 2016 can be used in place of CDC. It's important to understand how temporal tables differ. Suppose I insert a row into a base table where I've configured temporal tables. The version history of that table is empty, because temporal tables only deal with changes. Now suppose I update that row and change a column. The temporal table stores the old version of the row along with time-stamped versions of the start/end date of the life of that row. But you'd need to examine the version history row and the base table to see which column(s) changed. Maybe you care about that, maybe you don't. However, there's a catch. Suppose I update the row in the base table, but I don't change any values. SQL Server still writes out a new row to the temporal table version history, even though nothing changed. (By contrast, CDC is intelligent enough to detect when an update doesn't change any values, and doesn't write out any change history). I consider that a shortcoming in temporal tables.
Finally, there's a shortcoming in CDC. If you perform a DDL change on a table (e.g., add a new column), CDC doesn't automatically cascade that change into the change tracking history for the base table. You have to perform a few extra steps. The steps can be automated, and they certainly aren't deal-beakers, but you need to be aware that CDC doesn't handle DDL changes automatically to begin with.
In summary, I like both features. I like the intelligence that Microsoft baked into the CDC engine and I like the level of detail that CDC stores in the change tracking history tables. However, because CDC writes out just column changes, trying to reconstruct full row version history isn't a trivial task. By contrast, I like the row version history in temporal tables, but I was disappointed that the engine doesn't even give me the option of suppressing row history if an UPDATE truly didn't change column values.
Whether you include either feature in your arsenal is up to you, but it's very important to understand how these tools work and whether you can effectively leverage them in your ETL operations.
#5: Data Lineage Documentation
One of my pet peeves is seeing data teams construct documentation quickly, where the documentation has limited (or no) practical value. My conscience just doesn't permit me to quickly go through the motions and produce something for the sake of saying I produced documentation, when I know I wouldn't find it helpful if I were new to the situation.
There are individuals who acknowledge that much of the data documentation out there isn't fantastic, but also acknowledge the following:
- Producing good documentation can be very time-consuming.
- Producing good (and up-to-date) documentation can be especially difficult if the team constantly faces change/enhancement requests.
- Different team members can have reasonable disagreements about what constitutes good and useful documentation.
Although I love the Microsoft Database platform, I'll freely acknowledge that the SQL Server environment isn't inherently conducive to good data documentation. The tools certainly don't stand in the way of building good meta-data, but they don't exactly offer what I consider to be good tools to facilitate it. So, the less-than-sanitized little secret is that if you want to build good data documentation that other developers and maybe even some analysts will find useful, you have to build it yourself.
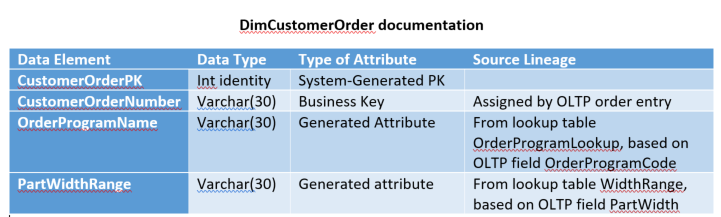
Although I've summarized here for brevity, here's an example of a document (Figure 2) that I recently worked with my team to build. For every data element, we define the system data type and how we treat the element (was it system generated, a business key, a straight feed from the source, or a derived column that's based on lookup rules or other rules). The source lineage is in narrative form and sometimes contains several lines of CASE statements. At the end of the day, you base the format on what works for you.
#6: Just How Important are Technical Skills When Defining Requirements?
Recently, at a SQL Saturday event, I engaged in a spirited but friendly lunchroom debate about the role of technical skills in identifying business requirements. Although I've never conducted a formal poll, I'll bet the price of a fancy dinner that more people would say that those creating good solid business requirements should not need technical skills. Well, I'm going to go against the predominant view in our industry and state boldly that technical skills are often necessary to the process of defining clear business requirements for a Data Warehouse application.
We could have a separate debate about whether it should be necessary in the ideal world, but we live in a world that's often messy. So here are three compelling reasons why I say tech skills are realistically important in hammering out requirements.
First, often I'm able to work through specific user requirements by building prototypes and meaningful demos. Business users are often very busy and don't necessarily have the time to read/build meaningful specs. They need to see something live and “shoot down” the wrong assumptions in the demo to get to what they're really after. Even if you work in a highly-regulated industry such as health care, even within the rules, there can be all sorts of areas of variation that won't get covered in a vacuum. Obviously, it's going to take someone with some technical knowledge to build a good demo. So yes, sometimes you need to use the technology as a means to gathering user requirements.
In some cases, I've been able to “cut to the chase” of hashing out business requirements by building prototypes and showing them to users. Without this approach, we might never have identified some of the more intricate details.
Second, I've seen cases where business users have lulled themselves into a false sense of security about legacy systems. The business might prepare what they believe to be fully detailed and bullet-proof specifications on what they want in a new data warehouse/analytic system. But their false assumptions might lead to a “garbage in, garbage out” scenario. The final data warehouse solution might work according to specification, but might only serve to propagate an undesired aspect into a new system. This could be anything, including the business having conflicting views about the nature of historical data, or a misunderstanding about business logic. Remember, businesses deal with turnover just like IT does - they patch their rules and their understanding over time, just like legacy systems get patched. On more than one occasion, I've spotted serious issues in source data long after the business wrote the requirements. Had a technical person participated in the requirements and profiled the data properly, developers wouldn't have gone down the wrong path.
Finally, a person with good technical skills can sometimes review requirements and improve them. When I was a rookie developer, my boss (a developer manager) sat in on a business meeting with a project manager who was gathering requirements. My boss had a fantastic idea in this phase that immediately generated great interest with a business team that was previously lukewarm on the new system. My boss was one of those types who could see the entire picture: the technology, the use, the implementation, everything. Data Warehouse projects always need the big picture people, and the big picture includes technical skills.
To my colleagues in the database world, your statements that a person can build good data warehouse specs and requirements without tech skills are well-intentioned. Sadly, reality says otherwise.
Patience and Balance: A Periodic Reminder to Actively Study the Kimball Methodology
Once a month I try to reread a chapter or at least part of a chapter in the Kimball data warehousing/dimensional modeling books. I set aside time to read the design tips on their website. I've read them many times, but to this day, I still catch something that didn't fully register before. Other times, I'll have forgotten some scenario, only to have some information jog my memory.
When our children complain about getting up to go to school every morning, we try to find the words to convey the concept of a lifetime of learning. We need to carry that passion into our own work, but we also need to be patient. Sometimes it's difficult to keep even one toe in the nice tranquil waters of learning while the other 99% of our body feels the heat from the scalding waters of deadlines, difficult projects, etc.
It takes time to go through a learning curve and even longer to incorporate what you've learned into active projects. For some, it's months, for others, it can be years. Perhaps the only thing worse than having no time to learn new things is actually learning things and being frustrated that you can't apply any of it because your current projects won't permit it. I know this is the easiest thing in the world to say, but it takes time to establish good practices. Be patient but keep moving. These changes don't occur overnight: They're organic and seminal. The bridge between a dream and success is hard work, and you must pay close enough attention to seize any opportunity to more forward!
It bears repeating: Good practices are organic and seminal. It takes time to achieve repeatable success.
Tune in Next Time…
Many years ago, I worked on a large public-sector application for which I won awards from the United States Department of Agriculture. I've been refactoring it to create a community data warehouse ETL demo. In my next article, I'm going to present portions of the ETL application and will reference the content from this article. Stay tuned!
