



Asynchrony is at the heart of NodeJS. Developers are told, “Don't block the event loop.” NodeJS uses a form of cooperative multitasking that relies on code yielding frequently so that other code can run. Asynchrony presents an interesting challenge to overcome when writing code that would normally be synchronous: uncompressing a file, reading a CSV file, writing out a PDF file, or receiving a large response from an HTTP request. In an Express-based Web server, it would be a terrible idea to synchronously take an upload request, compress it, and write it to disk. Express won't be able to handle any other incoming HTTP requests from other clients while the upload is being processed.
Many of these challenges are answered by an abstract interface in NodeJS called a stream. You've probably worked with streams in Node and not known it. For example, process.stdout is a stream. A request to an HTTP server is a stream. All streams provide two ways to interact with them: Events or Pipelines.
Events
All streams are instances of EventEmitter, which is exposed by the Events module. An EventEmitter allows consuming code to add listeners for events defined by the implementer. Most Node developers encounter this pattern when looking for a way to read a file. For instance, createReadStream in the fs module returns a Readable stream that's an EventEmitter instance. You obtain the data by wiring up a listener on the data event like this:
const fs = require('fs');
const readStream = fs.createReadStream('test.txt', {encoding: 'utf8'});
readStream.on('data', function (chunk) {
console.log(chunk);
});
As the Readable stream pulls the data in from the file, it calls the function attached to the data event each time it gets a chunk of data. An end event is raised at the end of the file. (See a full example in the samples download folder called “Events”.)
Problems quickly arise when using events. What if you want to take this data and do something else with it that's also asynchronous and slower than the data can be read? Perhaps you want to send it to an FTP server over a slow connection. If you call the second asynchronous service inside the event listener above and it yields to the event loop, you'll likely receive another call to your event listener before the data has finished being processed. Overlapped events can lead to out-of-order processing of the data, unbounded concurrency and considerable memory usage as the data is buffered. What you really need is a way to indicate to the EventEmitter that until the event listener is done processing the event you don't want another event to fire. This concept is frequently termed backpressure. In other parts of node, this is handled by requiring the event listener to make a callback to indicate that it's done. EventEmitter doesn't implement this pattern. EventEmitter does provide pause() and resume() methods to pause the emission of events.
Pipe offers a better alternative for reading data from a stream and performing an asynchronous task.
Pipe
All streams implement a pipeline pattern (as you can read in this interesting article: http://www.informit.com/articles/article.aspx?p=366887&seqNum=8). The pipeline pattern describes data flowing through a sequence of stages, as shown in Figure 1. There are three main players that you encounter in the pipeline pattern: a Readable source, a Writable destination, and optionally zero or more Transforms that modify the data as it moves down the pipeline.

As the chunks of data are read by the Readable stream, they're “piped” into another stream. Piping a Readable stream to a Writable stream looks like this:
const fs = require('fs');
const readStream = fs.createReadStream('test.txt');
const writeStream = fs.createWriteStream('output.txt');
readStream.pipe(writeStream);
Data is read by the Readable stream and then pushed in chunks to the Writable stream. In the example above, how do you know when the contents of test.txt have all been written to output.txt? Just because you're using the pipe method doesn't turn off the events raised by the streams. Events are still useful for knowing what's going on with a stream. To get a notification when all the data has passed through the stream, add an event listener like this:
const fs = require('fs');
const readStream = fs.createReadStream('test.txt');
const writeStream = fs.createWriteStream('output.txt');
writeStream.on('end', () => {
console.log('Done');
});
readStream.pipe(writeStream);
Note that the event listener is wired up before calling the Pipe method. Calling Pipe starts the Readable stream. If you wire up events after calling Pipe, you may miss events that are fired before your listener is in place.
Use a Transform if you want to modify the data as it passes from Readable to Writable. Perhaps you have a compressed file that you need to decompress. Use the Gunzip transform provided in the zlib module like this to uncompress the data:
const fs = require('fs');
const zlib = require('zlib');
const readStream = fs.createReadStream('test.txt.gz');
const writeStream = fs.createWriteStream('output.txt');
writeStream.on('end', () => {
console.log('Done');
});
readStream
.pipe(zlib.createGunzip())
.pipe(writeStream);
Calling zlib.createGunzip creates a Transform stream to uncompress the data flowing through it. Note that the event listener is wired up on the Writable stream at the end of the pipeline. You could listen for the end event on the Readable stream. However, in cases where the Writable stream or Transform stream is slower than the Readable stream, it may be a considerable amount of time before all of the data is processed. In particular, because of the way it buffers data for efficient decompression, the Gunzip transform causes the end event to fire on the Writable stream much later than the close event fires on the Readable stream. In general, listening for end on the Writable stream is the right choice.
Creating Your Own Streams
Using the streams provided by node is a great start, but the real power of streams comes into play when you start to build your own streams. You can create streams to read a 4GB compressed file from a cloud provider, convert it into another format, and write it back out to a new cloud provider in a compressed format without it ever touching the disk. Streams allow you to decompose each chunk of that process in a fashion that provides re-usable pieces that you can plug together in different ways to solve similar but different problems.
There are two main ways to construct your own streams based on Node's built in stream module: inheritance and simplified construction. Simplified construction, as its name implies, is the easiest. It's especially nice for quick one-off transforms. Inheritance syntax is a bit more verbose but allows the definition of a constructor to set object-level variables during initialization. In my examples, I use the inheritance-based syntax.
Create a Readable Stream
Readable streams source data that are piped into downstream Transform or Writable streams. I don't create Readable streams nearly as often as I create Transform or Writable streams. A Readable stream can source its data from anywhere: a socket, a queue, some internal process, etc. For this article I've created a simple Readable that streams bacon ipsum from an internal JSON data structure.
Creating a Readable stream is fairly simple. Extend the built-in Readable stream and provide an implementation for one method: _read.
class BaconReadable extends stream.Readable {
constructor(options) {
super(options);
this.readIndex = 0;
}
_read(size) {
let okToSend = true;
while (okToSend) {
okToSend = this.push(
baconIpsum.text.substr(this.readIndex, size));
this.readIndex += size;
if (this.readIndex > baconIpsum.text.length) {
this.push(null);
okToSend = false;
}
}
}
}
The baconIpsum.text contains the text that the readable emits and _read() does the bulk of the work. It's passed an advisory size in bytes that indicates how much data should be read. More or less data than indicated by the size argument may be returned, in particular, if the stream has less data available than the size argument indicates, there's no need to wait to buffer more data; it should send what it has.
When _read() is called, the stream should begin pushing data. Data is pushed downstream by calling this.push(). When push returns false, which is a form of backpressure, the stream should stop sending data. Calling push doesn't immediately pass the data to the next stage in the pipeline. Pushed data is buffered by the underlying Readable implementation until something downstream calls read. To control memory utilization, the buffer isn't allowed to expand indefinitely. Controlling the buffer size is handled by the highWaterMark option that can be passed into the constructor of a stream. By default, the highWaterMark is 16KB, or for streams in objectMode, it's 16 objects. Once the buffer exceeds the highWaterMark, push returns false and the stream implementation shouldn't call push until _read is called again. Flow control like this is what allows streams to handle large amounts of data while using a bounded amount of memory.
Passing a null value to push is a special signal indicating that the Readable has no more data to read. When there's no more data to read, the end event on the Readable stream fires.
BaconReadable is used like the previous example's Readable methods:
const BaconReadable = require('../BaconReadable');
const fs = require('fs');
const baconReader = new BaconReadable();
const fileWriter = fs.createWriteStream('output.txt');
fileWriter.on('finish', () => {
process.exit(0);
});
baconReader.pipe(fileWriter);
When run, this code writes 50 paragraphs of bacon ipsum to output.txt.
Create a Writable Stream
Writable streams sink data at the end of a stream pipeline. I use them quite frequently to post the contents of a file to an HTTP endpoint or to upload data to a cloud storage service. The SlackWritable I show here posts data from the stream into a Slack channel. It's a perfect way to share some bacony goodness with your coworkers!
Creating a Writable stream follows a similar pattern to Readable. Extend the built-in Writable stream and implement a single method, _write.
const request = require('request');
const stream = require('stream');
class SlackWritable extends stream.Writable {
constructor(options) {
options = options || {};
super(options);
this.webHookUrl = options.webHookUrl;
}
_write(chunk, encoding, callback) {
if (Buffer.isBuffer(chunk)) {
chunk = chunk.toString('utf8');
}
request.post({ url: this.webHookUrl,
json: true,
body: {text: chunk}
}, callback);
}
}
The first thing to note in this example is the constructor. I've extended the default option implementation of the underlying stream and used it to pass in the webHookUrl for the Slack integration. Just a reminder for those new to ES6: You can't set properties on this until after you have called the super method. I've left out the code ensuring that a webHookUrl is always passed in. See the SlackWritable example in the downloads for how to handle this.
The core of the implementation is _write . It receives three arguments: a chunk, the encoding, and a callback. Chunk is the data received from upstream. It can be in multiple formats including a buffer, a string, or an object. It'll almost always be a buffer unless objectMode is set to true, in which case, it'll be an object. Because SlackWritable needs a string, it first checks to see if the chunk is a buffer. If it's a buffer, you convert the buffer to a string.
You may wonder why SlackWritable explicitly uses utf8 instead of using the passed-in encoding variable. Encoding is only valid if the chunk is a string. If the chunk is a buffer, it should be ignored. Once the buffer has been converted to a string, it's then posted to Slack using the request module. When the post has completed, the callback is called. Calling the callback indicates to the upstream that the data sent in via _write has been handled and that new data can be sent. Node won't call _write again until the previous write command has completed. If you combine the BaconReadable with your new SlackWritable, you get code that looks like this:
const BaconReadable = require('../BaconReadable');
const SlackWritable = require('../SlackWritable');
const baconReader = new BaconReadable();
const slackWriter = new SlackWritable({ webHookUrl: process.env.WEBHOOKURL});
slackWriter.on('finish', () => {
process.exit(0);
});
baconReader.pipe(slackWriter);
The webHookUrl is passed in via an environment variable to avoid it being committed in code and inadvertently disclosed. If you run the code and pass it a valid slack webHookUrl, you'll see something like Figure 2 in your Slack client.
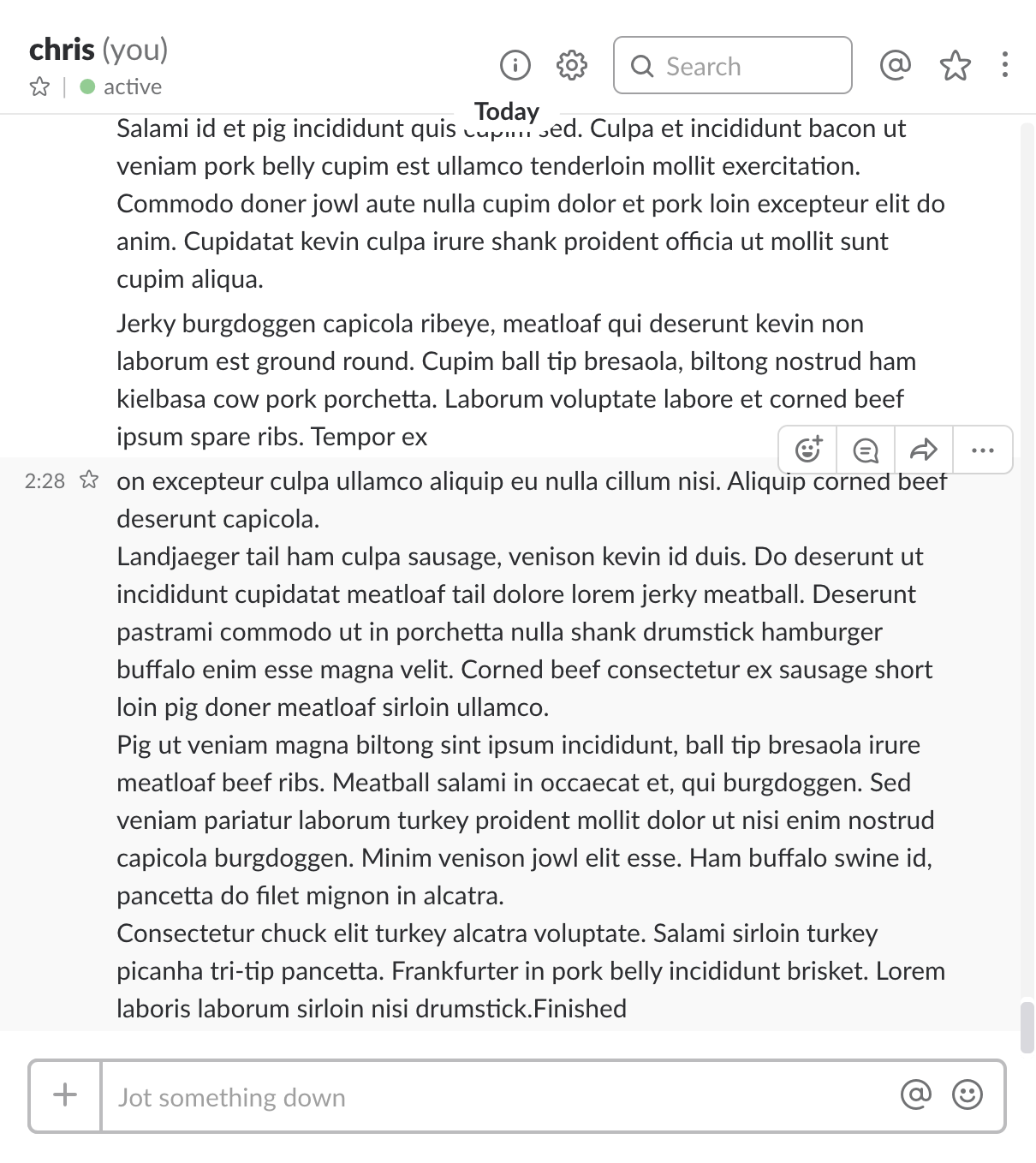
If you look closely at the Slack output you'll notice that the bacon ipsum is broken up into chunks of text. These chunks do not align with the \n line feeds in the original text. There are two reasons for this:
- Slack breaks up all text sent via a webHook into chunks of < 4096 characters before sending.
- Twice,
_writewas called: once with a 16KB block of text and once with a 953-byte block of text.
The number 16KB should ring a bell. It matches the default highWaterMark size for buffering between streams. By changing this value, you could alter the size of each chunk that _write receives. What if you want _write to get called each time a line ending in \n appears in the stream? Transform streams to the rescue!
Creating a Transform Stream
Transform streams sit between Readable and Writable streams in the pipeline. You're not limited to one Transform stream. It's possible to string together multiple transforms. Taking advantage of this allows you to create Transforms with a single responsibility and re-use them in multiple pipelines in various ways. You might imagine a Readable AWS S3 stream piped into a Gunzip Transform and then piped into a CSV parsing Transform piped into a Filter Transform that removes certain rows piped into a Gunzip Transform piped into a Writable AWS S3 stream. A pipeline built like this can handle a file of any size with no change in memory or disk requirements. A larger file would, of course, require more time/CPU to process.
You can easily create a Transform that breaks up the bacon ipsum into lines before sending it along to SlackWritable. Creating a Transform stream follows the well-worn pattern you've now established with Readable and Writable: extend the built-in Transform stream and implement the _transform method. See Listing 1 for the complete Line Transform implementation.
Listing 1: Line Transform
const stream = require('stream');
class LineTransform extends stream.Transform {
constructor(options) {
options = options || {};
super(options);
this.separator = options.separator || '[\r\n|\n|\r]+';
this.chunkRegEx = new RegExp(this.separator);
this.remnantRegEx = new RegExp(this.separator + '$');
this.remnant = '';
}
_transform(chunk, encoding, callback) {
// Convert buffer to a string for splitting
if (Buffer.isBuffer(chunk)) {
chunk = chunk.toString('utf8');
}
// Prepend any remnant
if (this.remnant.length > 0) {
chunk = this.remnant + chunk;
this.remnant = '';
}
// Split lines
var lines = chunk.split(this.chunkRegEx);
// Check to see if the chunk ends exactly with the separator
if (chunk.search(this.remnantRegEx) === -1) {
// It doesn't so save off the remnant
this.remnant = lines.pop();
}
// Push each line
lines.forEach(function (line) {
if (line !== '') { this.push(line); }
}, this);
return setImmediate(callback);
}
_flush(callback) {
// Do we have a remnant?
if (this.remnant.length > 0) {
this.push(this.remnant);
this.remnant = '';
}
return setImmediate(callback);
}
}
Let's examine the constructor first. An optional line separator is passed into the constructor as part of the options hash and if it doesn't exist uses CRLF, LF, or CR. It creates two regular expressions that are used to parse the text as it's transformed. Finally, it creates a string variable to hold partial lines, called remnant.
The bulk of the work is done by _transform. Similar to the Writable stream, it receives a chunk, an encoding, and a callback. If a buffer is received, it's first converted to a string. It checks for any remnants from the last transform call, prepends that data onto the chunk of data that was just received, and clears the remnant. It then splits the lines up using the separator regular expression. After splitting the lines, it checks to see if the last line is a partial line. If it is a partial line, it's put into the remnant buffer for the next call to _transform to pick up. Finally, it pushes out any non-blank lines. It isn't required for a transform to push any data. Think about implementing a filter as a transform. A filter necessarily drops data out of the stream by not pushing it.
A second method, _flush, shows up in this transform due to the way the transform buffers unsent lines in the remnant variable. In this way, _flush provides an optional way for a transform to empty any data it has buffered during the transformation process when the stream ends. LineTransform uses the _flush method to empty any remaining partial lines from the remnant variable.
To use the LineTransform, you just add an additional pipe statement to the previous example like this:
const BaconReadable = require('../BaconReadable');
const LineTransform = require('../LineTransform');
const SlackWritable = require('../SlackWritable');
const baconReader = new BaconReadable();
const lineTransform = new LineTransform();
// Get a webhook uri at:
const slackWriter = new SlackWritable({ webHookUrl: process.env.WEBHOOKURL});
slackWriter.on('finish', () => {process.exit(0);});
baconReader
.pipe(lineTransform)
.pipe(slackWriter);
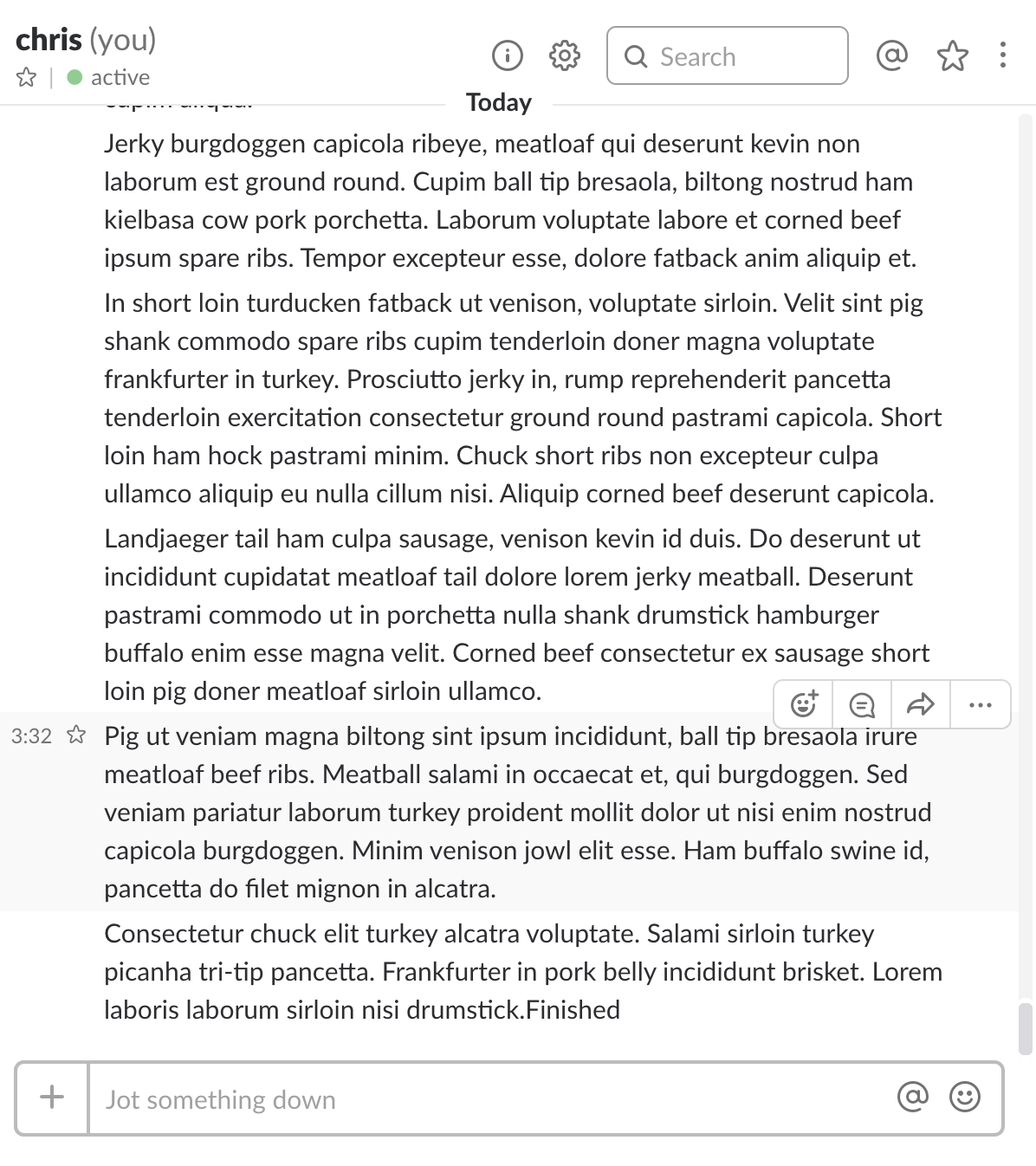
Running this sends bacon ipsum line-by-line to Slack, as shown in Figure 3, resulting in 50 messages, one for each paragraph of text emitted by BaconReadable.
Summary
Node streams provide a powerful mechanism to manipulate streaming data. Consider using streams whenever you're reading, writing, or transforming large data sets. Whatever you do, don't cross the streams!
