


If your application requires some form of document rendering, you've likely needed to work with PDF files. Rendering output as PDFs has several advantages: they are browser and device independent; and they can be interacted with in a disconnected way. If you're adept at JavaScript, you already possess the skills necessary to extend a PDF's functionality.
The question may be “How can developers and users easily interact with PDFs in our applications?” The first step to answering that question involves understanding what PDFs are. PDFs are just another way to host data. A PDF is just a document that may have one or more fields and it can be highly graphic and formatted. In your applications, the most common task that users need is to read and write data to and from fields.
The second step to answering that question is to build a library to handle the core functions of reading and writing to and from a data source. In the Java and .NET world, there are the iText 7 PDF libraries. (https://itextpdf.com/). In this article, I'll demonstrate a library I created to interact with PDF files. Specifically, using the custom PDFLibrary illustrated in this article, you'll be able to read data from a PDF and write data to a PDF. You'll also be able to determine what fields a specific PDF has. With the PDF Library, built on the iText NuGet Package, you'll be able to easily incorporate PDF functionality into your applications, whether they be WPF-, Web-, or API-based.
PDF stands for Portable Document Format.
This article isn‘t a detailed or in-depth examination of iText. iText is a very extensive set of libraries that allow you to fully interact with and manipulate PDF files. If you've worked with older versions of iText (v5 or iTextSharp), you'll find a number of changes to the iText API in v7. Most of the time, somebody else has built the PDF and typically, all your applications need to do is take a PDF template and apply data values to it for some downstream process. In other cases, a PDF, and specifically its data fields, are the input to a process. This article covers the basics of reading and writing data to and from a PDF file. In another article, I'll demonstrate how to consume the library in a Web application.
PDFLibrary Source Code and Samples
If you want to go directly to the code and work through the tests, you can find the code in the following GitHub repository: https://github.com/johnvpetersen/PDFLibrary.
Examining the iText7 NuGet Package
Figure 1 illustrates the NuGet Package Manager with the iText7 package highlighted. It's interesting to note that under .NET Standard, the number of dependencies skyrocket! As a matter of full disclosure, I didn't create a .NET-Standard version and therefore, I can't opine on whether that aspect of the NuGet Package is well constructed.
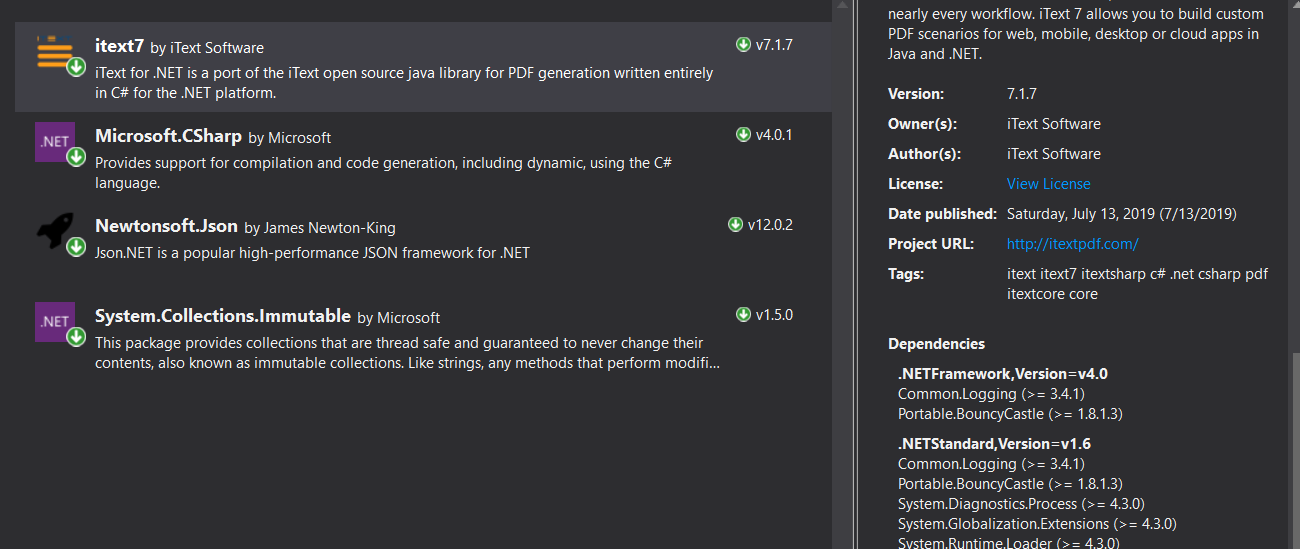
The source code for this article was compiled under .NET Framework 4.7. The Bouncy Castle Package is to support cryptographic features that are often incident to secured PDFs in HIPAA, PCI, and other environments that have regulatory requirements related to personal and medical information. That dependency isn't necessary if you're not using iText 7's cryptologic features. The same goes for the Common Logging NuGet Package Dependencies. Unless you're going to take advantage of iText's logging features, you won't need these logging packages.
Given today's corporate IT governance requirements, you should always examine and understand every dependency your application directly and indirectly takes on because of other package dependencies. The iText7 NuGet Package is like many other packages with dependencies that aren't hard dependencies. In this case, it would be a better design if iText7 had additional NuGet Packages to bring in the cryptographic and logging features on an as-needed basis. The good news is that with NuGet, you can break packages apart and recompose them for better dependency management.
In your applications, the most common task is to read and write data to and from fields. PDFs are just another way to host data.
iText's License: The AGPL 3.0 License
What follows is not specific legal advice on what you do in your situation. What follows is just my own opinion from the standpoint of being both a software developer and an attorney. In all things legal that you encounter, you should always engage competent counsel in your own jurisdiction for legal advice appropriate for your specific facts and circumstances.
The iText7 DLLs in the NuGet Package are distributed under the AGPL License: http://www.gnu.org/licenses/agpl-3.0.html. The AGPL license grants you the right to use, modify, and distribute code (and DLLs) in your applications, including commercial applications. The AGPL's primary purpose is to remediate what's generally referred to as the “application service-provider loophole.” In a service environment, you never “distribute” software. The AGPL is based on the GPL. GPL/AGPL is a strong copy-left license mandating that modifications to covered work are shared when such code is “distributed,” but it doesn't cover what's referred to today as SaaS (software as a service). AGPL addresses that gap.
It's a common misconception that if you merely “incorporate” GPL/AGPL code in your applications, your application's source code must be made available to the public. This gets to what's commonly referred to as the “viral nature” of GPL./AGPL I put the phrase “incorporate” in quotes because in all things legal, conclusions depend on terms, and more specifically, defined terms. Reviewing the AGPL text, the term “incorporate” is in the preamble. The preamble is NOT binding language. The only binding language in the GPL/AGPL is enumerated under the terms and conditions. The first place to review is the definitions. The definitions of interest are the following (emphasis mine):
- “The program” refers to any copyrightable work licensed under this license. Each licensee is addressed as “you.” “Licensees” and “recipients” may be individuals or organizations.
- A “covered work” means either the unmodified program or a work based on the program.
- To “modify” a work means to copy from or adapt all or part of the work in a fashion requiring copyright permission, other than the making of an exact copy. The resulting work is called a “modified version” of the earlier work or a work “based on” the earlier work.
What can you conclude from these three definitions? First, the “program” is what's directly licensed under the GPL/AGPL. A “covered work” is the program itself or other code that's based on the program, which includes your modifications to the program. This is what strong copy left is all about: to ensure that modifications to GPL/AGPL code are shared and made available in the OSS ecosystem. Instead of making changes to the program, you may create a new work based on the program. What does based on mean? In the copyright context, it's a derivative work. Whether you make changes to a program or create a new work based on the program, for copyright purposes, you're creating a derivative work. Therefore, what the GPL and AGPL call a covered work is one of two things: the original program or a derivative work. In other words, the only things that can be subject to the GPL/AGPL, based on the GPL/AGPL terms is the original program or a derivative work.
Does that mean that a Using statement referencing a GPL/AGPL library make your entire application a derivative work? In my opinion, you need something more than just a library reference. If the majority of your application's functionality requires the GPL/AGPL library, then your application may be a derivative work. The PDFLibrary I created for this article, in my opinion, is a derivative work and would need to be licensed under the GPL/AGPL. What about a website that leverages the PDFLibrary and, by reference, the GPL/AGPL library? Would the website be a derivative work? In my opinion, the answer is no because an entire website is not based on any one specific library. A website is often a composite of many things, including open source works with different licenses and although the website itself wouldn't need to be licensed under any open source license, the requirements of any associated open source licenses still apply. If you're interested in more in-depth coverage on this issue, you can read my recently published LinkedIn article: https://www.linkedin.com/pulse/dispelling-myth-gnu-licenses-gpl-agpl-lgpl-john-petersen/.
The following is the link to iText's license: https://github.com/itext/itext7-dotnet/blob/develop/LICENSE.md. The provision I want to draw your attention to is the final paragraph:
You can be released from the requirements of the license [AGPL] by purchasing a commercial license. Buying such a license is mandatory as soon as you develop commercial activities involving the iText software without disclosing the source code of your own applications. These activities include: offering paid services to customers as an ASP, serving PDFs on the fly in a Web application, and shipping iText with a closed source product.
If you find yourself scratching your head from confusion, you're not alone. I'm a lawyer with a lot of experience in OSS and OSS licensing and I was confused. The first point of confusion is the implication that the AGPL forbids commercial usage. The GPL/AGPL has no such prohibition. The second point of confusion is the implication that if you use the library under the AGPL, your application's entire source code must be disclosed. I just provided a detailed explanation of why this isn't the case. The other interesting point is that if you obtained this library in a .NET environment, you likely did so via NuGet. The NuGet license URL is: https://www.gnu.org/licenses/agpl-3.0.html. In other words, unless you interrogated the GitHub repository, you wouldn't have notice of other license terms.
Is the paragraph quoted above supposed to represent a dual license scenario? If it is such an attempt, the attempt is in-artfully drafted. In the legal context, words matter. Words are composed to create instruments which a party seeks to enforce in an effort to achieve some remedy? Is the paragraph enforceable? I'll go as far to say that it creates ambiguities. The only thing I'm certain of is the AGPL's role in the licensing scheme. Setting aside the license drafting problems, the iText library is functionally quite good. To that end, if you find iText useful in your commercial application, you should support their efforts and purchase a commercial license.
Even if, legally, there are enforceability problems, there's the question of ethics. There's a tremendous free-rider problem in OSS today. Too many just take…and too few contribute. For open source to thrive, it needs more than unicorns and rainbows: It requires funding. At the same time, companies that seek to monetize OSS need to be good citizens too. In that spirit, I submitted a pull request to fix the license verbiage: https://github.com/itext/itext7-dotnet/pull/10/commits/a672afe5522f39436c68f720366e593fdda48111. The modified text achieves the dual-licensing objective in the AGPL context that was iText's original intent. It remains to be seen whether iText accepts my pull request.
Who says the legal stuff can't be interesting! Let's get to the stuff we know is interesting, the code.
The PDFLibrary and Its Methods
The PDFLibrary's primary function is to be an abstraction over the iText 7 library. To that end, the PDFLibrary handles two broad tasks: to read data from a PDF and to write data to a PDF. These two broad tasks encompass four distinct functions:
- File-Based Functions:
- Read a byte array from an existing PDF file.
- Write a byte array to create a new PDF file or replace an existing PDF file.
- Field-Based Functions:
- Read field data from a PDF byte array.
- Write field data to a PDF byte array.
Additional functions include:
- Determining whether a given file is a PDF.
- Retrieving a field name list from a PDF.
The iText7 has many objects and sparse documentation. The PDFLibrary's goal is two-fold. First, to make it as easy as possible to handle the basic functions that application will need to perform on a PDF, namely reading and writing data. Second, to improve upon iText's samples which, candidly, perpetuate poor .NET coding practices. Figure 2 illustrates the problem with iText's HelloWorld.cs program.
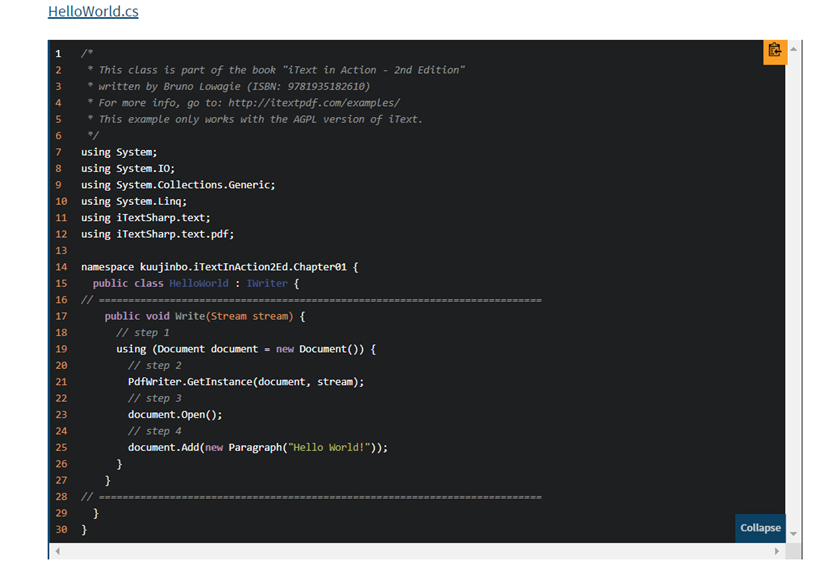
- There are several problems with the code. First, although the text mentions that streams can be used to create files, nowhere is that technique demonstrated. Instead, they just show a figure with a rendered PDF, notwithstanding the fact that the helloworld.cs code illustrated doesn't render a PDF! Second, in the real world, not all layers in your application architecture have knowledge of or can use a file path. This is especially true if you're using loosely coupled services (as you should be using). In the real world, you need to deal with byte arrays and streams to read from and write to components that, in turn, will eventually write that data to some source, whether it's a disk or another service. And when you deal with streams or iText objects like PDFDocument, PDFReaders, and PDFWriters, you're dealing with components that implement the IDisposable Interface. That necessarily means that when you use such things, you must wrap their usage in a Using statement. To not do so ends up leading to the real and likely possibility of memory leaks. Just because something is a “Hello World” type of example, that's not an excuse to perpetuate bad and incomplete programming practices.
Determine Whether a File is a PDF
There are techniques that advocate opening the file and reading the first five bytes looking for { %PDF- }. As Listing 1 illustrates, I like to take it a step further and use iText to open the file with the PDFReader object. If it's successful, no exception will be thrown. If it's not successful, an exception is thrown. As for how to deal with the exception, that's up to your application that consumes the PDFLibrary. The PDFLibrary is a low-level library and its job isn't to trap and swallow exceptions. That's a higher-level function.
Listing 1: IsPDF Method
// Determine if a file is a PDF
public static ImmutableBoolean IsPDF(ImmutableArray<byte> file)
{
using (var ms = new MemoryStream(file.ToArray()))
using (var reader = new PdfReader(ms))
{
return new ImmutableBoolean(true);
}
}
Riddling a low-level function with excessive try catches is another common mistake. If a low-level function traps and swallows an error, your component will fail silently. For the purposes of this library, I made the design decision to vest such error handling in a calling library.
The IsPDF method accepts one parameter, an immutable array of bytes. You‘ll see byte arrays used often in code because that's the only way to pass data from one application layer to another. In Listing 1, once the byte array is received, it's applied to a memory stream that, in turn, is used to create an iText7 PDFReader object. If that instantiation process succeeds, you can infer that the file is indeed a valid PDF file. If the file isn't a valid PDF, iText throws an exception. How that exception is dealt with is a matter for the calling code to handle.
Note on the Immutable Classes
Throughout the code in this article, you'll see numerous references to immutable classes. For every parameter argument sent to the PDFLibrary method and for every type a PDF Library returns, an immutable type will be involved. In this way, you can presume that the data, when created, is what was sent to the PDF Library and is what the PDF Library received. In other words, variables used in PDF Library calls, can't be subject to side effects. The libraries necessary to support the immutable types used in this article are included in this source code link. If you're interested in delving further into the immutable classes, you can find that source code here: https://github.com/johnvpetersen/ImmutableClass.
Retrieving a List of PDF Field Names
You may need to determine the field names contained in a PDF. Listing 2 illustrates the call to get a field array which, in turn, relies on the private method that retrieves the form fields.
Listing 2. Fields Method
// Get a list of fields in a PDF
public static ImmutableArray<string> Fields(ImmutableArray<byte> pdf)
{
return getFormFields(pdf).Keys.ToArray().ToImmutableArray();
}
Reviewing Listing 3, you can see the core iText objects relied upon:
- PdfReader: Used to read and expose the PDF attributes at a low-level (think security, encryption, etc.)
- Pdfdocument: Uses a PdfReader to expose a PDF's form and its fields
- PdfFormField: Exposes the data and attributes of a specific form field in a PDF
Listing 3. getFormFields Method (private)
static ImmutableDictionary<string, PdfFormField> getFormFields(ImmutableArray<byte> pdf)
{
using (var ms = new MemoryStream(pdf.ToArray()))
using (var reader = new PdfReader(ms))
using (var doc = new PdfDocument(reader))
{
var builder = ImmutableDictionary.CreateBuilder<string, PdfFormField>();
PdfAcroForm.GetAcroForm(doc, false).GetFormFields().ToList().ForEach(x => builder.Add(x.Key, x.Value));
return builder.ToImmutable();
}
}
In this case, the code cycles through a PDF's form fields and extracts the field name and the PdfFormField reference and adds each to a dictionary. The PdfFormField object contains a lot of information that concerns the field's attributes in the context of form and the PDF itself that, in many cases, aren't relevant if all you're concerned with is reading and writing data. If your application is concerned with PDF generation where field attributes such as page placement, size, font name, etc. are concerned, then the PdfFormField object takes on more relevance.
Read and Write PDF Files
So far, I've covered how to determine whether a file is a PDF and the fields a PDF contains. The next task is how to read and write PDF files. Listing 4 illustrates the Read and Write Methods. The capabilities in these methods come from System.IO in .NET, not from iText. This is one area where a path value becomes a necessary because the ultimate disposition of these methods is to read from or write to a file on disk. What's returned is a byte array. The Write method, after the bytes are written to the specified path, invokes the Read method to return the bytes just written. I concede that this is a bit inefficient because why should I have to read to get the bytes I just provided? That's a fair critique. Like making the one method private, this too was an arbitrary design decision I made. The idea is that if I get bytes back, the calling program can presume the bytes were written in the first place. Could the method return a Boolean instead? Of course it could, and if you want that behavior, you're free to change the code as you see fit.
Listing 4: Read and Write Methods
public static ImmutableArray<byte> Read(ImmutableString path)
{
return ImmutableArray.Create<byte>(File.ReadAllBytes(path.Value));
}
public static ImmutableArray<byte> Write(ImmutableString path, ImmutableArray<byte> bytes)
{
File.WriteAllBytes(path.Value, bytes.ToArray());
return Read(path);
}
Read from and Write to PDF Files
Now that you can create and read PDF files, the next and final step is to read and write field values from and to those PDF files. Listing 5 illustrates the code to accomplish the first task, to get field data. The GetData method leverages the same getFormFields private method as does the public Fields method. The one thing to take note of is that in all cases, the value retrieved is a string. Once a field value is rendered on a PDF, it's a string and often, it's a formatted string, as would be the case for phone numbers, dates, and social security numbers, to name three examples.
Listing 5: GetData Method
public static ImmutableDictionary<string,string> GetData(ImmutableArray<byte> pdf)
{
return getFormFields(pdf).ToDictionary(x => x.Key, x => x.Value.GetValueAsString()).ToImmutableDictionary();
}
The SetData method, illustrated in Listing 6, accepts two arguments:
Listing 6: SetData Method
public static ImmutableArray<byte> SetData(ImmutableArray<PdfField> fields, ImmutableArray<byte> pdf)
{
using (var ms = new MemoryStream())
using (var doc = new PdfDocument(new PdfReader(new MemoryStream(pdf.ToArray())), new PdfWriter(ms)))
{
var form = PdfAcroForm.GetAcroForm(doc, false);
var formFields = form.GetFormFields();
foreach (var field in fields)
{
if (string.IsNullOrEmpty(field.DisplayValue))
{
formFields[field.Name].SetValue(field.Value);
}
else
{
formFields[field.Name].SetValue(field.Value, field.DisplayValue);
}
doc.Close();
return ImmutableArray.Create<byte>(ms.ToArray());
}
}
}
A PdfField array where each element contains the field name, the value, and the formatted value. Listing 7 illustrates the PdfField Class.
Listing 7: PdfField Class
public class PdfField
{
public PdfField(string name, string value, string displayValue = null)
{
DisplayValue = displayValue;
Value = value;
Name = name;
}
public string Name { get; }
public string Value { get; }
public string DisplayValue { get; }
}
A byte array that's the target PDF containing the fields to update
Why doesn't the SetData method use the getFormFields method? The getFormFields method closes the PdfDocument instance. When writing data to PDF fields, you need the PdfDocument to remain open for that process. Accordingly, while you strive for maximum re-use, practicality often dictates that you sometimes need to put that ideal on the shelf.
Why is the field value in this context always a string. It has to do with the context in which the data is being used. When you render data in a report, the fact that the underlying value is a date, integer, or Boolean type isn't important. When you deal with and manipulate data in code, its underlying data type matters. Integers are a great example. In code, an integer value will be 12345. When rendered on a report or a PDF, the value becomes “12345” and the formatted value may be “12,345.” It's up to some other facility to know what the underlying types and display formats are. The PDFLibrary simply takes that information and applies it. From a separation of concerns standpoint, the PDFLibrary isn't concerned with how or why a given piece of data is an integer or a date or why it's displayed in a certain way. Rather, the PDFLibrary takes the data as it finds it.
Why Are the PDFLibrary Methods Static?
The PDFLibrary is stateless. It accepts arguments (immutable arguments, to be precise), acts on those arguments, and provides an immutable response. The PDFLibrary is inherently thread safe. Therefore, there's nothing to be gained from creating an PDFLibrary instance variable. If you don't need to create state, don't. If you don't need a variable, don't create one. The same goes for always implementing a Using statement when the underlying class implements the IDisposable interface. Performance issues always start with a simple overlooked detail, which eventually repeats itself to the point that the “death by a thousand cuts” idiom applies.
Next Steps
The PDFLibrary is my approach to a simple abstraction over the iText library. Now that you have an understanding of how the PDFLibrary works, I encourage you to get and run the code from GitHub. The best place to start is with the unit tests. In my next article, I'll discuss how to implement the PDFLibrary in a Web application. In the Web application, I'll cover how to create an abstraction to the PDFLibrary that's better suited to meet the Web application's needs.
