


I can't think of any other skill besides Git that is universally applicable to any developer. It doesn't matter if you write code in C#, JavaScript, or Python, or for Windows or Mac or really anything else, there's a solid chance that these days you use Git for source control. And no, that doesn't mean just GitHub. Git is an open standard backed by the Git community. Various other products, such as Azure DevOps, Bitbucket, and Atlassian all support Git.
First things first. I'm going to avoid the lightning rod discussion of whether Git is a good product or not. The reality is that whether you like it or not, all of us use it. And let's be honest: It has proven to be scalable enough for the largest source code repositories, and it's pretty easy to get started with, too.
Yet it's one of those products that really drives me mad. So I thought it might be worth writing an article, explaining the basics of Git. With a strong foundation, you can build taller buildings.
Centralized Source Control vs. Decentralized Source Control
If you've worked with older versions of source control software, such as Visual SourceSafe, Mercurial, PVCS, or many others before that, you're familiar with centralized source control. In centralized source control, there's a server in the middle that all developers talk to. Any software project is comprised of many files. If you wish to work on a certain file, you check out that file. While that file is checked out, its status is marked checked out in the centralized source control repo. If any other developer wishes to overwrite that file, they're unable to, because it's checked out to you. You need to check in your changes first, and the other developer's changes are the other developer's headache. The other developer must probably do a merge or something similar. All of this works fine, but it has two main problems.
The first issue is what happens if that central server goes down. You can continue to work on the previous snapshot you pulled from the server. But sooner or later, when you need to re-sync your changes to the server or check-in files, you hit a wall. You can't for instance, continue working with source control locally. For that matter, you can't work with an alternate remote upstream location for the meantime, such as a co-worker's source control. And what if you want source control on just your computer, without any need to share with rest of the world, for a pet project that's complex enough to deem source control?
The second issue, of course, is scale. Centralized source control repos assume a small set of developers working very closely together. These days, we all contribute to very large source control repos, which are typical in popular open-source projects. A centralized source control mechanism that relies on locking in a central location to talk with simply doesn't scale to the general complexity of large-scale repos and a disconnected working model.
Both of these issues are fuzzy in nature. Visual SourceSafe fans insist that there are workarounds to these problems. But just because you can row to Japan in a tiny boat doesn't mean it's a good idea. To the rest of the world, it's clear that we need a new approach, a decentralized source control.
The opposite of centralized source control is decentralized source control, of which Git is an example. In decentralized source control mechanism, you can have many locations with the source control repo. These locations can be servers, or they can even be your own local hard disk, or they can be a coworker's hard disk. You can merge changes between these multiple source control repos. Also, you don't rely on exclusive check-in and check-out anymore. Instead, you rely on merges and commits. This invariably has the downside of merge conflicts. Good coding patterns, good architectural practices, and writing good tests reduce this pain to some degree, although don't eliminate it.
Let's start learning Git.
Install Git
Many development tools, such as XCode, already come with Git packaged. Even if you already have Git on your computer, it's a good idea to update it. The instructions are unique per operating system. Rather than rehashing instructions here, I suggest that you visit https://git-scm.com/book/en/v2/Getting-Started-Installing-Git and follow the instructions per your operating system and install Git on your computer.
Once you've installed it, you should be able to run the command “git” on terminal. For Windows, you'll notice that after installation, you get a special terminal called “Git bash”. This is a special terminal/command window on Windows that tries to emulate a Unix-like terminal. You're welcome to use it, although I've also used Git through the PowerShell window and never run into any issues. I do feel that you should lean on a Unix-like terminal even on Windows, because a lot of commands invariably end up making use of Unix-like commands intertwined with Git commands. Most devs mix and match them without even thinking about it.
Configure Git
Before you can use Git, you have to do some basic configuration. At the bare minimum, you'll need to specify a name and email - this is your information, who are you when you issue a commit. Of course, the server-side repo also authenticates you through the various means that Git supports.
You can also optionally specify a default editor and I highly recommend that you specify a line ending format as well.
Let's perform this basic configuration on your computer.
When you perform Git configuration, you can do so at one of three levels. You can do so at a global level, which affects all users on your computer. You can do so in your user profile, in which case it will affect all work on the user's profile. Or you can specify at a folder level, where you wish to have certain settings affect only certain repos. These settings go in a hidden file called “.gitconfig”. My gitconfig looks like that shown in Figure 1.
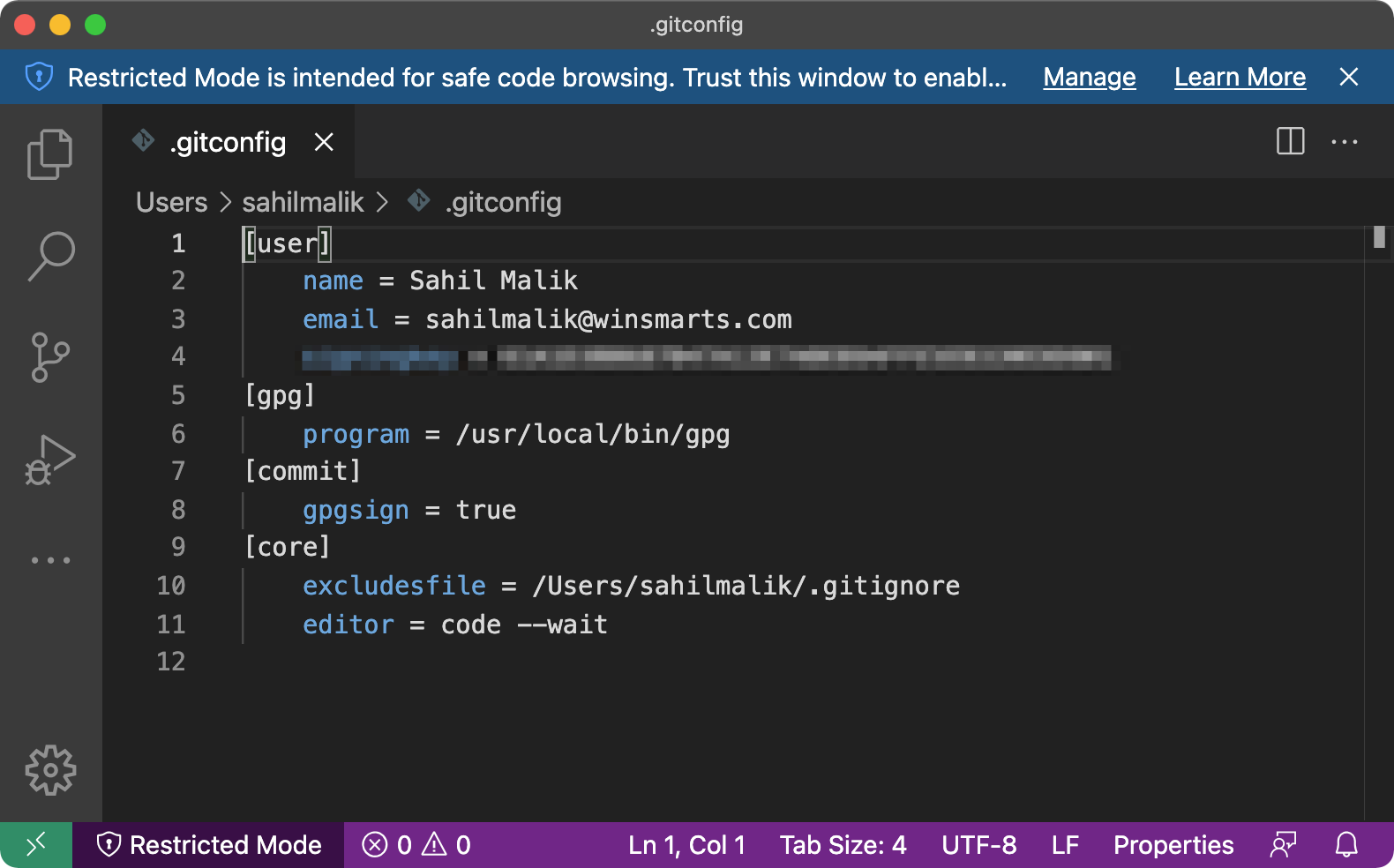
First let's configure the username and email address. Here's how. Remember to use your own username and email address.
git config --global user.name "Sahil Malik"
git config --global user.email sahilmalik@winsmarts.com
Next, let's specify a default editor. By default, Git uses Vim. A lot of people love Vim. Personally, I never have to restart my Mac unless I'm trying to exit Vim. There are just too many damned shortcut keys to remember. No, I don't dislike it; in fact when I am ssh'ed into a Docker container, using something such as VSCode may not be an option. But I do find myself more productive in VSCode, so I'll just set that as my default editor as follows.
git config --global core.editor "code --wait"
Of course, for the above to work, VSCode should be installed and be in your path. Now, whenever you need to enter multi-line commit messages, or do stuff that requires any kind of editing, VSCode pops up. Let's try this. Run the below command to edit all your settings.
git config --global -e
As you can see, VSCode pops open with your .gitconfig settings. No longer do you have to remember the shortcut “shift_ZZ” to save and exit, because this isn't Vim.
Figure 1 shows my settings that have a few additional things I haven't talked about. Your settings file may look slightly different.
Finally, let's configure end of line settings. This is a very important setting, so let's understand what this is. On Windows, an end of line looks like this:
text\r\n
On Mac/Linux, try this:
text\n
Notice the difference? Windows likes to use carriage return and new line. The reasons for this are historical, and so deeply rooted that Windows isn't going to change. But this creates a big problem when some of your developer friends are on Macs and you're on Windows. In fact, when contributing to OSS projects, this will invariably be the case. So as a best practice, perform the following configuration on Windows,
git config --global core.autocrlf true
This will cause Git to strip out the /rs (carriage returns) when checking your files in.
Getting Help
There seem to be a lot of commands you need to remember here. Luckily, there's help. At any point, you can issue the following command to get help:
git --help
And if you wish to get specific help on a sub command, you can issue a command like this:
git config --help
One other thing I highly recommend is that if you're on a Mac or Linux environment, set up zsh with a theme called “oh-my-zsh”. It makes great use of the Git plug-in and gives you syntax highlighting on terminal and even tab completion. This can be seen in Figure 2. On Windows, you can either use the instructions at https://winsmarts.com/running-oh-my-zsh-on-windows-10-6fcb0fbc736b, you can set up WSL2, or you can use posh-git.

Initialize a Git Repo
A Git repo, or repository for short, lives in a folder. Go ahead and create a new folder. I created one called “gitlearn”. To initialize a new empty repository in this folder, when inside this folder in terminal, issue the following command:
git init
This creates a new Git repository in this folder. Additionally, it creates one branch in this empty repository. The name of the branch by default is “master” although they let you configure it to use “main” by default if you prefer. You can choose to change the name of the initial default branch as follows:
git config --global init.defaultBranch "main"
What makes a folder a Git repository? Inside this folder is a hidden folder called “.git”. This folder is where Git likes to store all its inner workings. If you delete this folder, it's no longer a Git repository. I advise you to not hand-edit stuff inside this folder. Leave it alone.
Commit Code
Let's first understand the very basics of the Git workflow. A typical project is comprised of multiple files and folders. In Git, you have to think in three parts: local files, committed files, and the staging area.
Your local files are your work-in-progress, also known as working copy. Here, you're making things, breaking things, and editing stuff, and edits don't preserve history. Git, of course, tracks what files are being changed, added, or deleted. But if you edit a file multiple times in a single commit, to Git, it appears as one edited file, not many versions of this edited file. This is work in progress after all.
Then you have committed files. For now, let's not mix in server and client. The cool thing about Git is that even your local hard disk has commits. I find this very useful when I'm progressively building a project, and I commit as I go along. I can revert back to a commit if I mess up or find out where I messed up using diffs etc., all without involving a server. See how productive Git is? Even without an Internet connection, I have so much power at my fingertips.
Now let's also add a server briefly. When you add committed code to your local repo, you can choose to “push” to an upstream location. That upstream location is the server. During the push, you may have to resolve conflicts, merge your team members' code, etc.
Finally, you have an area that sits in the middle of the committed area, and the working area, which is the staging area. The staging area is your “proposal to commit.” Think of it as: Okay I've been working on stuff in my local area, and I'm ready to commit. And here is my proposal of what I want to commit. For instance, I propose these three files to be added, these two files to be renamed, etc. I “stage” those changes in the staging area before I commit. And then I commit.
Let's see this in action. If you've been following this article sequentially, you should have an empty Git repo. In this repo, go ahead and add a file like the next snippet. Note that my commands shown here are for the *nix shell, but you can extrapolate this on a Windows computer also.
echo "first file" > readme.md
This command creates a file called “readme.md” with “first file” as the text contents. Note how my zsh prompt has also changed in Figure 3. I find this color change a very convenient mechanism to know that my tree is dirty.

The yellowish color indicates that my repo has unstaged changes. If I wish to see what the current status of my Git repo is, I can use the following command.
git status
In my case, it should produce output as shown in Figure 4.
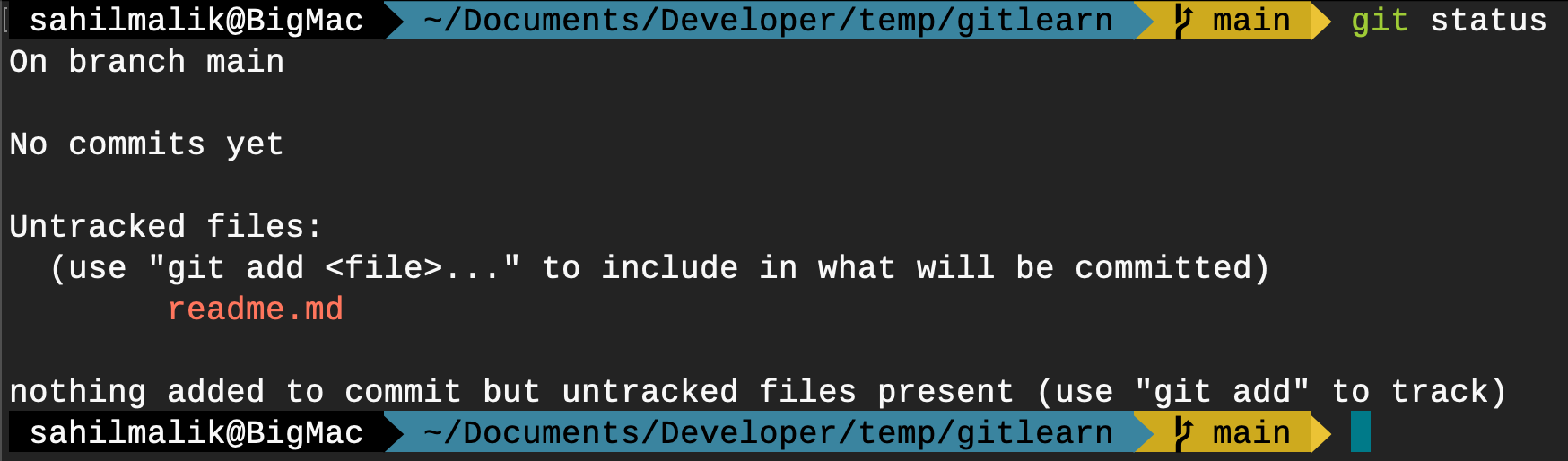
Git status tells me that I have an untracked file. That makes sense, as I just added a new file, but Git isn't tracking it for me - I haven't ever added it to my repo. To add it, I need to commit it. But before I can commit it, I need to stage it. To stage all changes, I can issue the following command.
git add .
Or alternatively, I can say git add and pass in the specific files I wish to stage. Notice again, in Figure 5, how my prompt has changed.

Now to commit, I simply issue the following command.
git commit
This should pop open your default editor, in my case VSCode, to enter a commit message. I could also say Git commit -m “message” to avoid opening the editor. I'll enter some message like “My first commit” and save to commit. Now my prompt should change as shown in Figure 6.

Congratulations, you just did your first commit. Now try executing Git status again. It should tell you that your working tree is clean. You can see your history of commits by executing the following command.
git log
At any point, I really encourage you to type -h in front of any command and examine what other options are supported.
That was fun, but there's still so much more to learn: branches, server-based stuff, forking, merging. So stay the course, young Padawan.
Push Code to a Server
You're a serious developer. You aren't just writing this to learn Git: You want to do some serious work. That means that you need a server-based Git repo that can scale to the Internet. An easy way to get such a repo, for free, is github.com. Feel free to use any other product you wish. For my purposes, I created a repo at https://github.com/maliksahil/gitlearn. (This is a private repo, so you won't be able to access it. All of these repos are protected by permissions, so you won't be able to commit to mine, even if it were a public repo. You should go and create your own.)
Now back to my local Git repo. I wish to push my local code into the server-side repo. How does my local repo know where to push to? The answer is that I need to add a remote origin, and here's how you do it:
git remote add origin
git@github.com:maliksahil/gitlearn.git
Now wait a second. Let's unpack this a bit. What's that funny looking syntax? How did Git authenticate me?
First of all, Git remote lets me manage tracked remote repositories. By saying Git remote add, I'm saying that I wish to add a remote tracked repository. The origin keyword indicates that here is where this project was originally cloned from. You didn't clone your project from the remote repository, but you're basically saying that in the process of setting things up, in future, developers can clone from here. The final parameter is the URL.
The way authentication works here is that by default, GitHub uses username password. But that's neither secure nor manageable. So it also supports ssh, which is what I have set up on my computer. Finally, you can use credential helpers to use alternate mechanisms of authentication as well.
Go ahead and execute the Git remote add origin command, as shown in the last snippet.
Next, you need to set the upstream branch. I haven't yet had a chance to talk about branches, but since you have only branch “main”, that will be your upstream branch. The idea is that an upstream branch is what's tracked on the remote repository by your local branch. My local “main” needs to mirror the server side “main”, so my “main” branch is a great choice for an upstream branch. To set the upstream, and to push my “main” into “origin”, I use the following command:
git push -u origin main
Now visit the GitHub repo in your browser and your code should be visible, as shown in Figure 7.
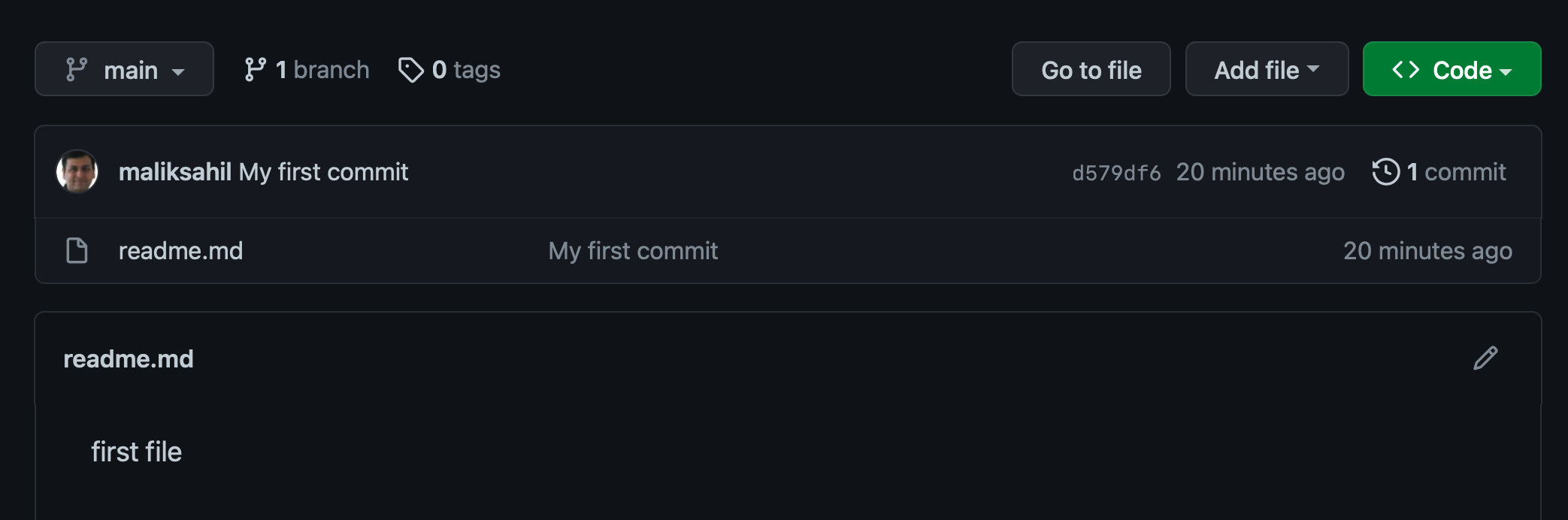
Modify Code
Okay, at this point, you should have a server-side repo similar to https://github.com/maliksahil/gitlearn and a locally cloned repo. Assuming that you don't have a locally cloned repo, you can use “git clone” to clone the repo from the server location. You know you can pass the –help parameter to any command, right? Try doing a git clone yourself.
Now I wish to make changes. A typical software project contains a number of files. You also go through many releases. Although nothing stops you from making changes to “main”, it's generally considered a bad idea. Most real-world repositories set a policy on the Git repo to prevent making changes to the “main” branch. The idea is that you create an issue. Then you discuss what you wish to do on that issue. You associate the issue with the files you're changing and you create a separate branch for your changes.
Aha! You're into branches now. What is a branch? For now, just think of it as a copy you've made of your code. I'll get into this in a minute.
You create a branch and you make your changes there. And then you “merge” your changes into “main” via a pull request.
Gosh that's a mouthful. Before I get any more confused, let's see this in action.
First, in my local repo, let's create a branch.
git branch newchange
This command has now effectively given you a copy of “main”. Don't worry, it isn't literally a full copy. Git is smart enough to abstract the details only for changes. For you, it feels like a copy. Before you can start working on this copy, you need to check out this branch, as follows:
git checkout newchange
I could have also abbreviated the above two commands into one, effectively saying “create a branch and check it out” like this:
git checkout -b newchange
Alternatively, I could create a branch in the server-side repo and pull the changes using Git pull etc. That would be very useful if your coworkers have created a branch that they've pushed to the server and you wish to work on it collaboratively.
At any point, you can run “git branch” to verify which branch you're on and which branches are available locally.
Now that you've checked out the newchange branch, let's make some changes. Modify the first file by appending some text.
echo "more changes" >> readme.md
And create a new file.
echo "a new file" > secondfile.md
Now, you should have to changes ready to go, as can be seen in Figure 8.

Now let's stage these changes, commit them locally, and then push them into the cloud.
First, stage:
git add .
Then commit:
git commit -m "My second commit"
Look at you, issuing Git commands like a pro. I'm so proud. Now let's push it to the cloud.
git push
The last command didn't work. You should see an error, as shown in Figure 9.

This makes sense if you think about it. I never told my Git repo which upstream location “newchange” should be sent to. And it gives me a helpful command to fix it. So go ahead and run that command, which then sets the upstream location and pushes my changes.
git push -u origin newchange
Oh yes: -u is a shorthand for –set-upstream
This is where the fun starts. Observe Figure 10.
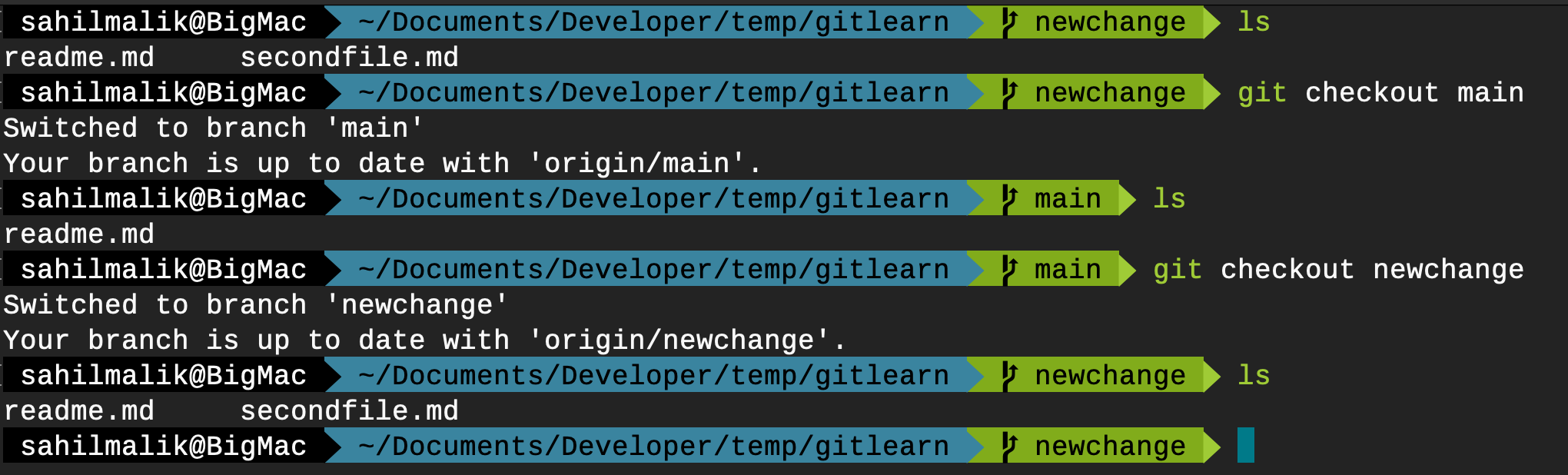
See, in Figure 10, I effectively now have multiple versions of my code base. Isn't this great? I can now revert back to a production version in “main” while switching to a dev version in “newchange”.
This brings up a question. How do I get my changes from “newchange” into “main”? There are two ways.
First, you can do a pull request. This means, you go to the Git repo and issue a PR (short for pull request). This is you asking, hey, I would like to merge these changes into main, and usually you'd also have some reviewer on the PR. The idea is that you don't have permissions to merge into main, or, as a policy, you wish to have an extra set of eyes look at your code. It's possible to set these policies on your repo, and most real-world projects have such policies.
The other mechanism is that you can merge from newchange into main and then push main to an upstream location. This is where, typically, you have both branches under your control. For instance, perhaps you have created a branch of a branch, but both branches are your dev work.
git merge newchange main
This workflow can be seen in Figure 11.
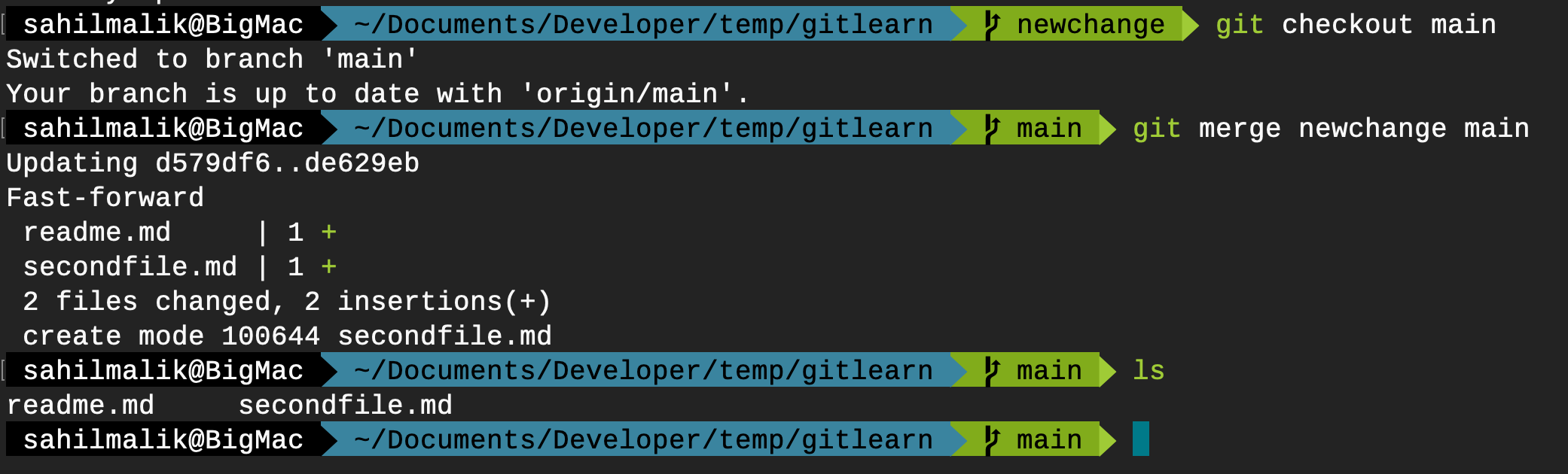
You can push this and your remote repo will reflect these changes. But I have other plans. Let's use the PR method. Visit your GitHub repo, and you should now see a nice helpful message, as shown in Figure 12.
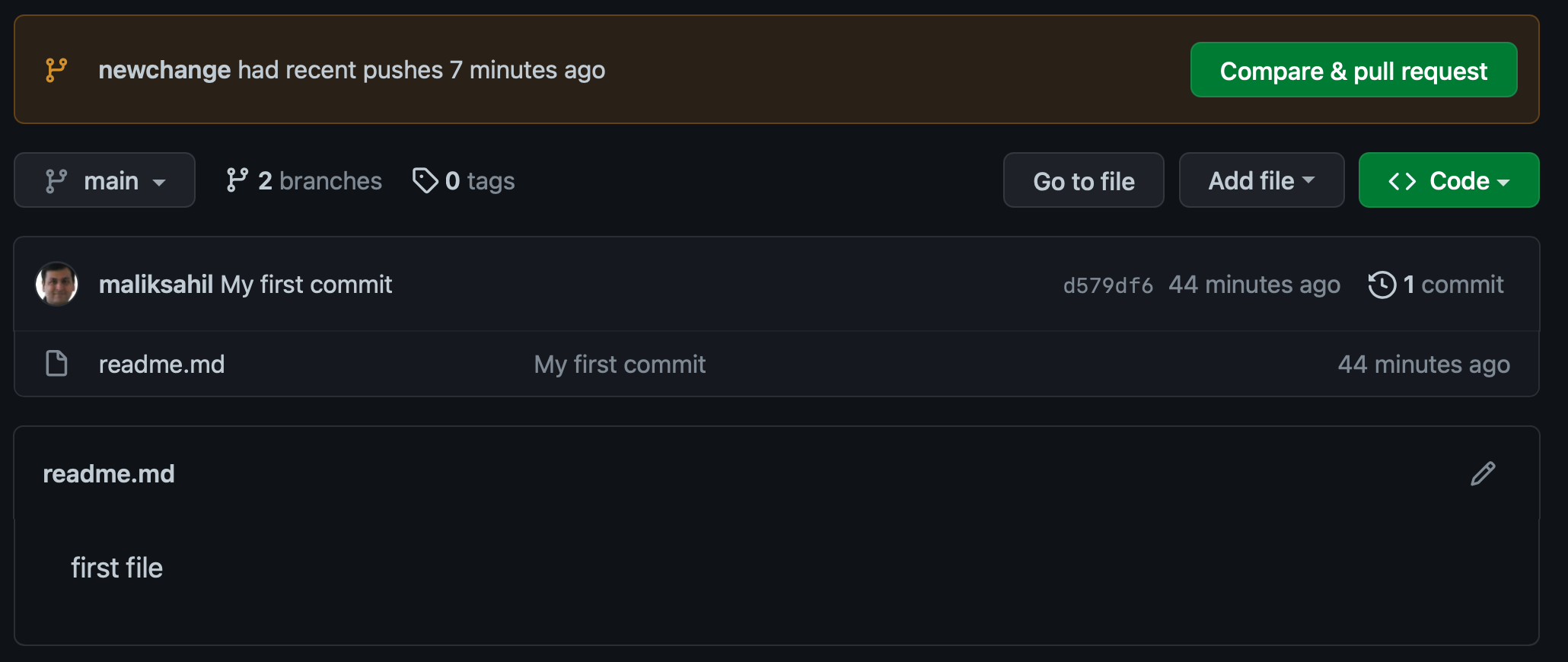
Use that “Compare & pull request” button to create a PR. This gives you a nice overview of the changes, the comments, files committed, approvers, labels, etc., which is great for a development workflow. You can also set up bots to do some basic review for you, and all sorts of other automation involving humans. When you're done, you can merge the pull request, and delete the branch, as shown in Figure 13.
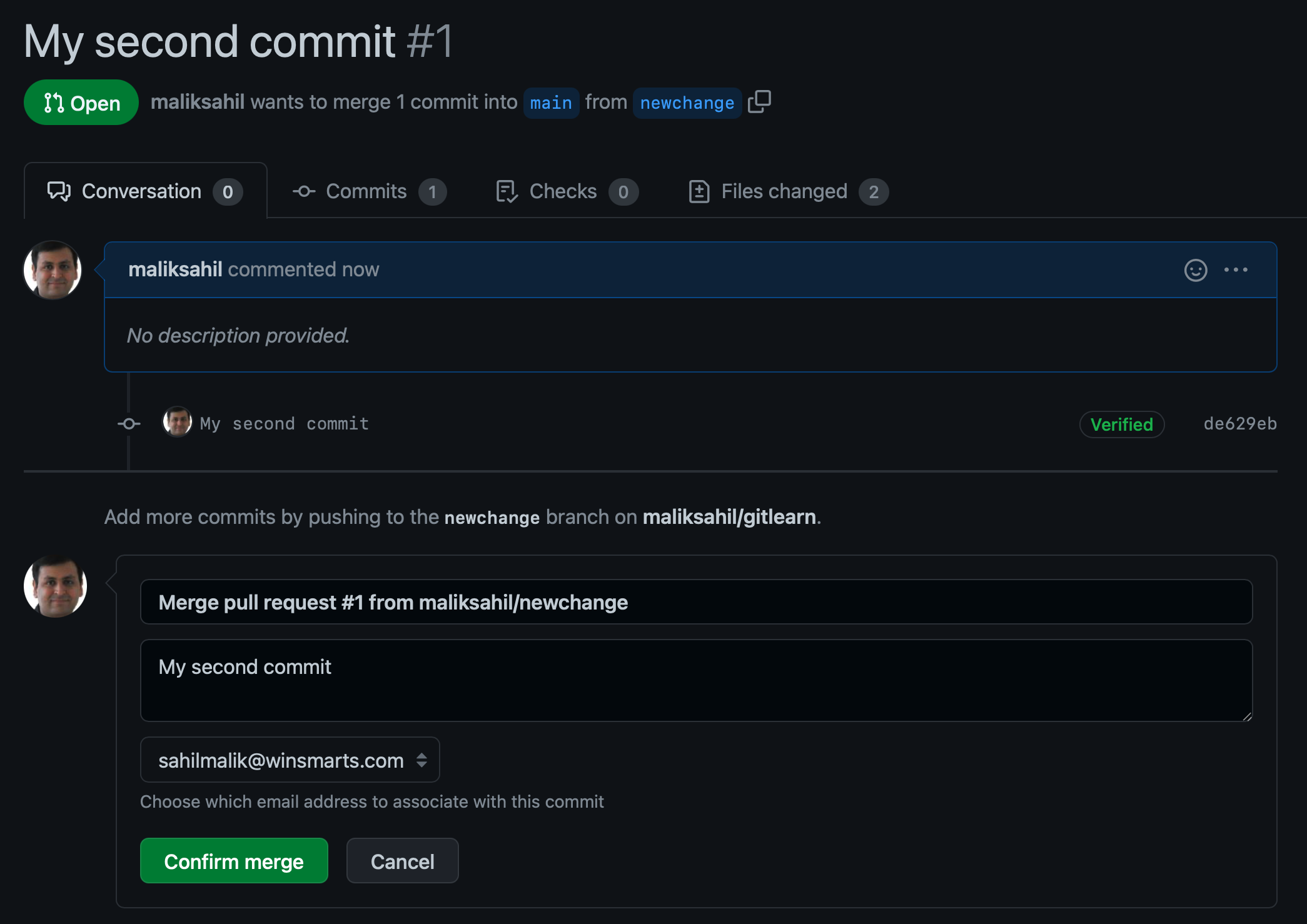
Now you've merged the PR, deleted the branch, and your changes are in main. You can feel free to also delete your local “newchange” branch as follows:
git branch -d newchange
Move, Rename, or Delete Files
I'll keep this section short because Git automates this nicely. And to save time and ink, I'll do everything in the “main” branch. Go ahead and perform the following changes to your repo.
mkdir afolder
mv secondfile.md afolder
mv readme.md dontreadme.md
You created a new folder and moved the secondfile.md into that folder, effectively deleting it from the root folder and adding a new file in afolder. Then you renamed readme.md to dontreadme.md.
Now, running a Git status basically tells me everything that I just did. You can see this in Figure 14.
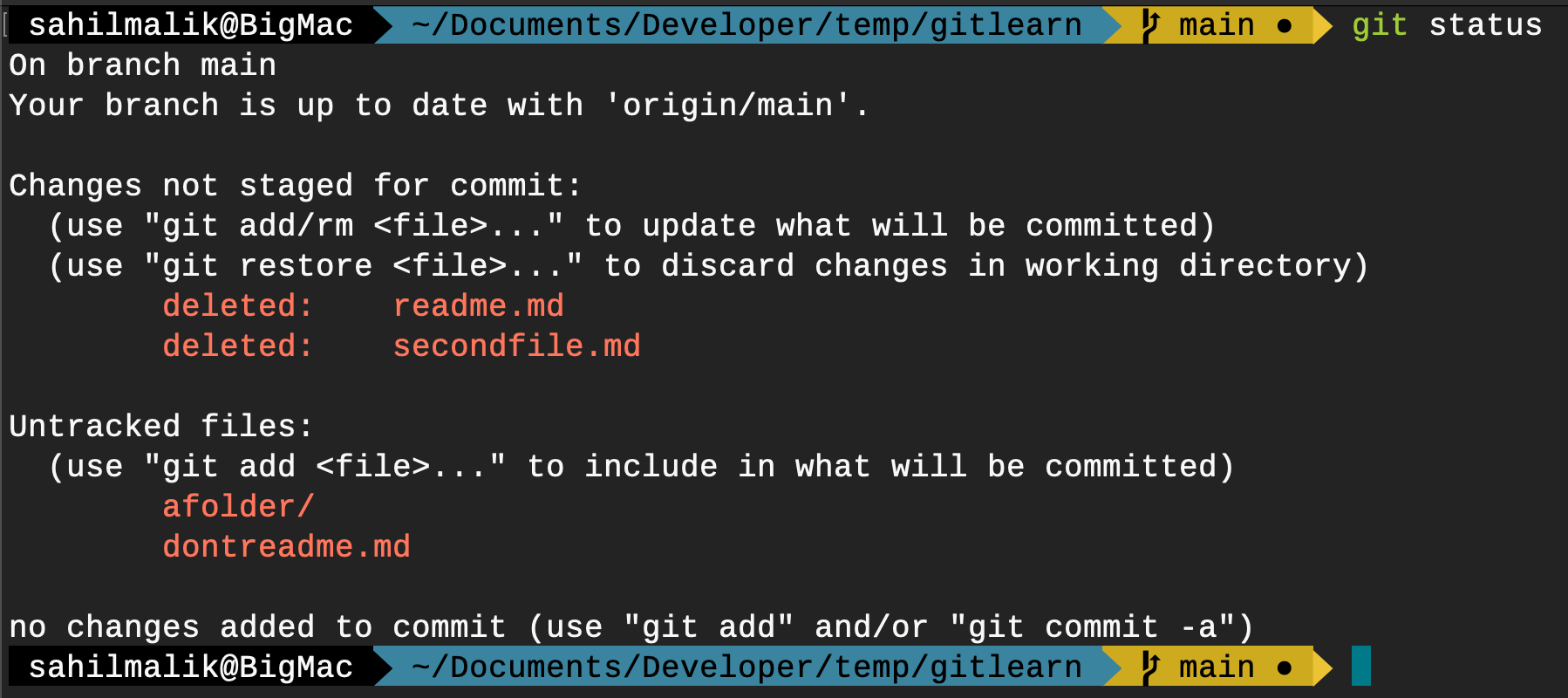
And now I can stage, commit, and push my changes as follows.
git add .
git commit -m "More changes"
git push
You just made some amazing changes and pushed them to the remote repo. Best of all, you did so using the concepts you have learned so far. I encourage you to repeat these changes using a branch and do a pull request to solidify your knowledge.
Ignore Files
In any development project, you'll have files that you don't wish to check-in as a part of your source code. These may be node_modules in a node project, or bin, obj folders in a .NET project. Your dev tools or development environment need these files, but they're downloaded or generated on the fly. Sometimes they're even specific to the operating system you're working on. Or perhaps you have configuration files with secrets or keys specific to the developer's environment. There are many situations where you want certain files to not be checked in.
Let's understand how you can teach Git to ignore files.
If you've been following this article, you should have a Git repo that looks like Figure 15.
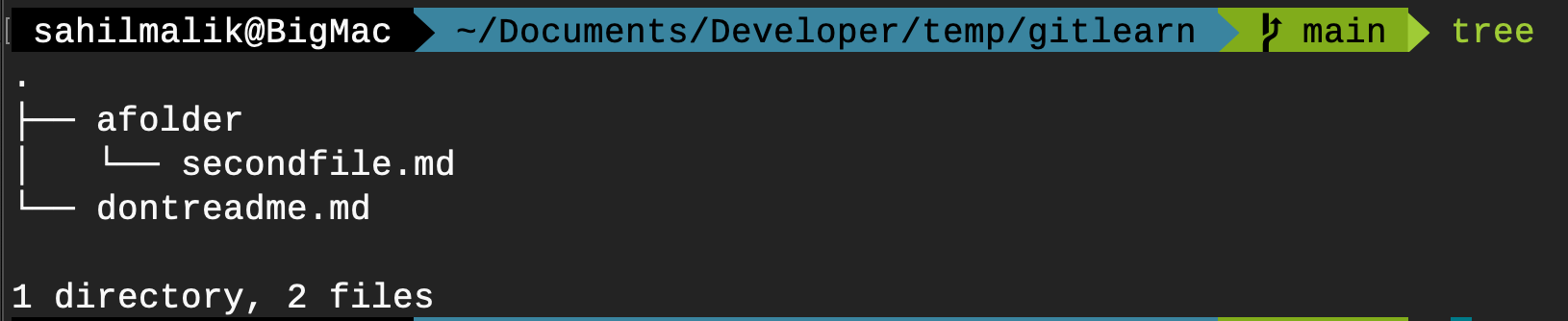
What I wish to do now is instruct Git to ignore the “afolder” contents going forward. Also, I'm going to create another file in the root of my repo. Let's call it env.txt, and I don't want to check it in. To save time, I'll do stuff in the main branch, although in real-world scenarios, you want to branch and merge.
First, let's create the env.txt file as follows:
echo 'someconfig' > env.txt
To instruct Git to ignore the env.txt and afolder folder, I'll create a new file in the root of my repo called .gitignore. You can also choose to create a .gitignore file per folder and have those settings apply only to that folder and its children.
In my .gitignore file, I choose to put the following text:
env.txt
afolder/
At this point, I'm going to add, commit, and push. Now let's visit my repository on github.com and examine what it looks like. This can be seen in Figure 16.
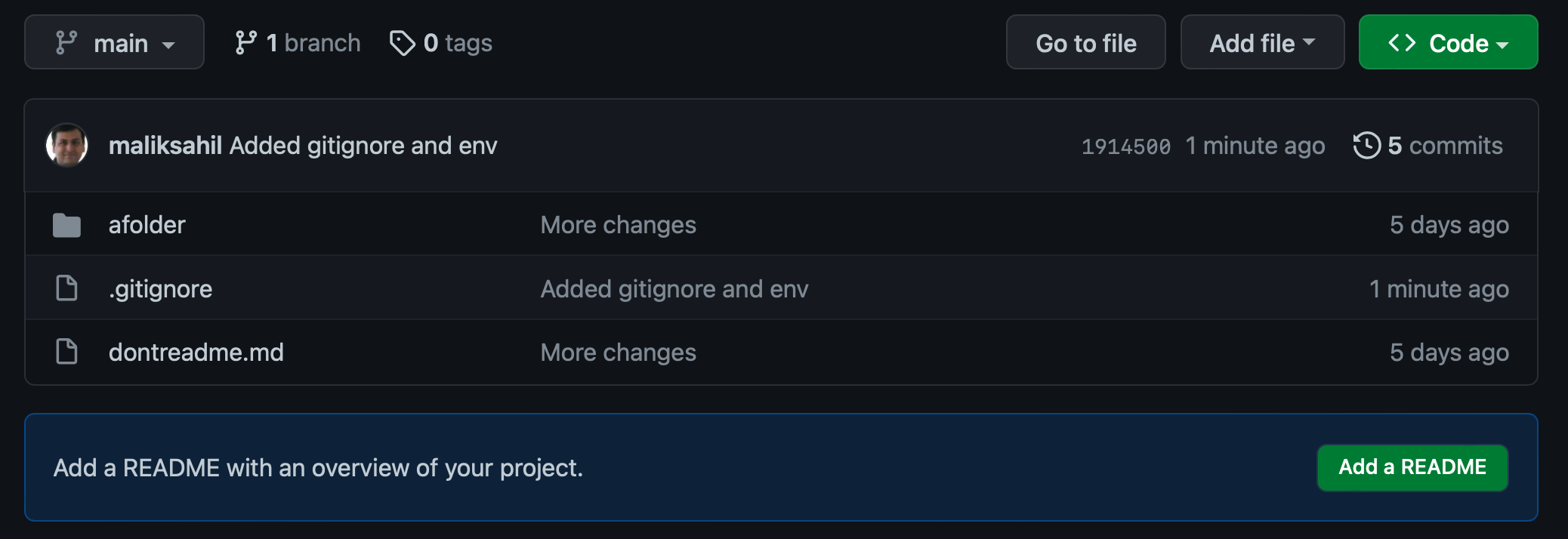
Are you surprised by what you see in Figure 16? I do see that env.txt was ignored. But why is afolder still there? It's still there because you're ignoring it going forward. This means that now if you were to put another file under afolder and try to check it in, that new file won't be checked in.
You can see this in action in Figure 17. Notice that the working tree remains clean, no matter what I do in afolder. Or is it?

Let's append some text in the afolder/secondfile.md file - remember that the secondfile.md file is checked into Git already. This can be seen in Figure 18.

Interestingly, now my working folder is no longer clean - even though I made the change in a file that resides in a folder that I've instructed to be ignored. This is because the file secondfile.md was already being tracked.
Why is this useful? It's useful for configuration settings, such as web.config or .env files. It's quite normal for developers to check-in an .env.sample file instructing other developers who clone the repository to follow the structure of .env.sample when they create their own .env files.
This .env file is instructed to be ignored from the get go, but the .env.sample file is not. This means that I can continue to maintain .env.sample and keep my instructions updated, while the .env remains safely out of source control.
But this behavior can also be problematic sometimes. Let's say that you forgot to include an auto-generated folder such as ``node_modules` in the first check-in. How do you now instruct Git to not track this folder going forward, even though you checked it in once?
First let's reset my repo to what's checked into remote.
git reset --hard && git pull
This command discards all of my changes and refreshes my local working copy from the remote location, just to make sure I have my teammates' changes on my disk.
Now I wish to instruct Git to stop tracking afolder but leave my working copy of afolder alone. This entire sequence can be seen in Figure 19.
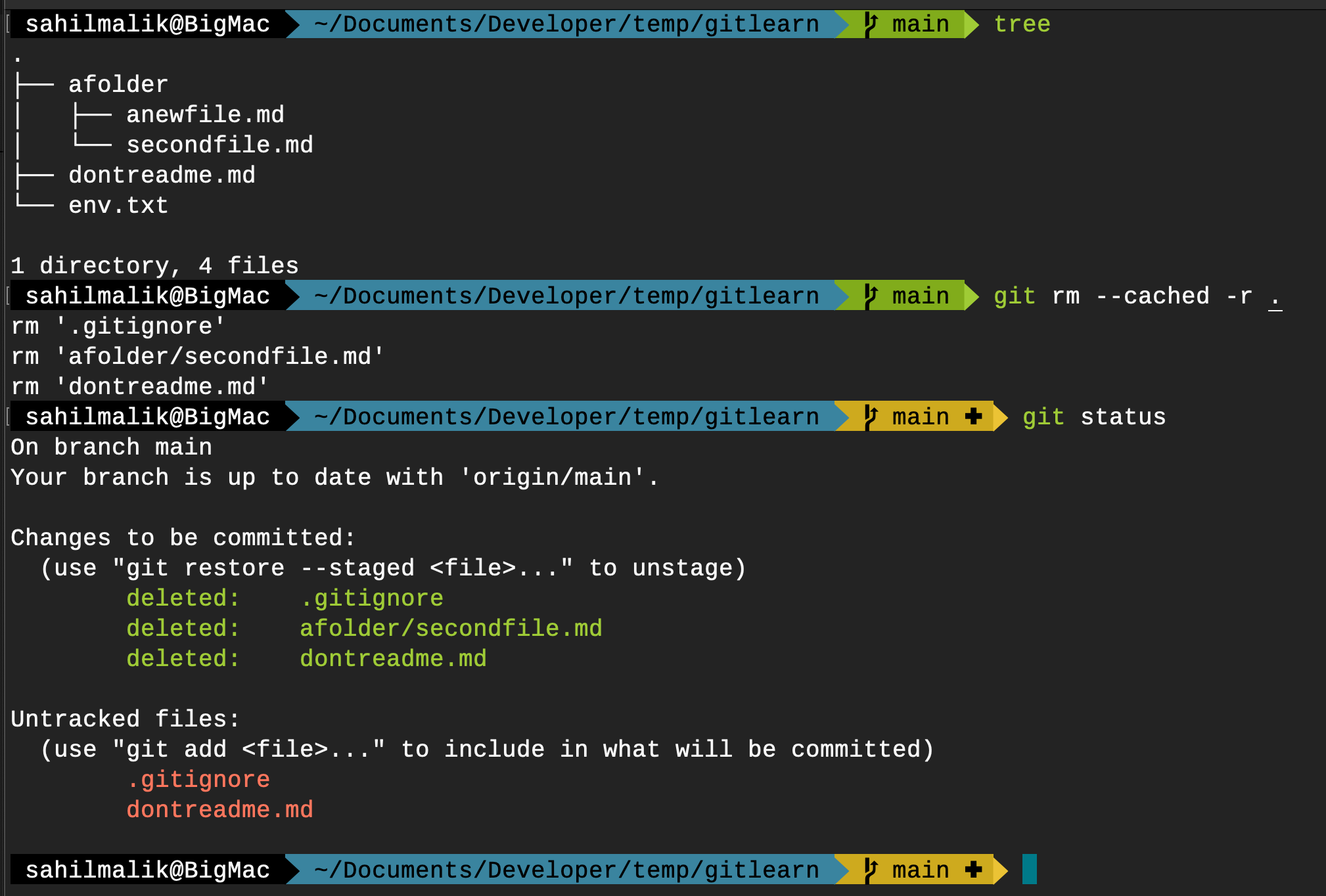
There's a lot going on in Figure 19, so let's break it down step by step.
First, using the tree command, I show the current structure of my working tree. Note that my gitignore has instructed Git to ignore afolder and env.txt, but afolder\secondfile.md is already being tracked. The afolder\anewfile.md was created after the gitignore file was created, so it's not being tracked.
Next, I ask Git to remove files from the index recursively using the -r option, but using the --cached option, I instruct Git to remove files only from the index but leave the working tree alone. Long story short, this means: Leave my local files alone but fix the Git repo.
Running this command informs me of the changes Git made. It didn't remove the files from my disk though. To fully understand the changes, I then run a Git status command, which tells me that it deleted .gitignore, but not really - it now shows .gitignore as untracked. This means that now when I do a git add ., those untracked files will now be tracked. But you know what won't be tracked? The afolder/secondfile.md won't be tracked going forward.
This achieves my goal of telling Git, hey, really, stop tracking this entire folder, just like my .gitignore instructs you to do.
To put things simply, simply adding a .gitignore won't cause Git to stop tracking files that are already being tracked but match the .gitignore spec. This is by design. To actually untrack files, you also need to remove them from the index.
Now, go ahead and do an add, commit, and push. Now your Git repo should look like Figure 20.
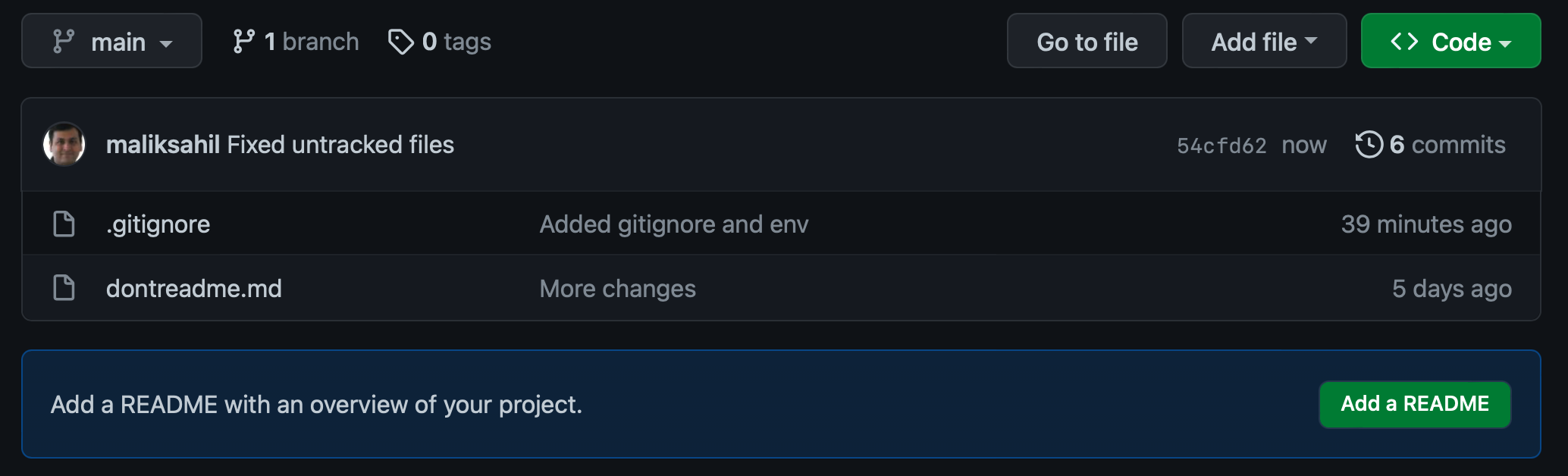
You can imagine that afolder could be something like node_modules, or something that you actually wanted to get rid of.
Diff
When you're working on a software project, you're editing files. This is your source code, and you need plenty of things to help you keep control of what's being committed. You've already seen a Git command called Git status that lets you do this at file level. But what about changes inside a file? Perhaps you want a good way to compare two versions of a file and get a clear idea of what changes will be made if you push your changes.
Let's understand this with an example. The current state of my Git repo is shown in Figure 21.
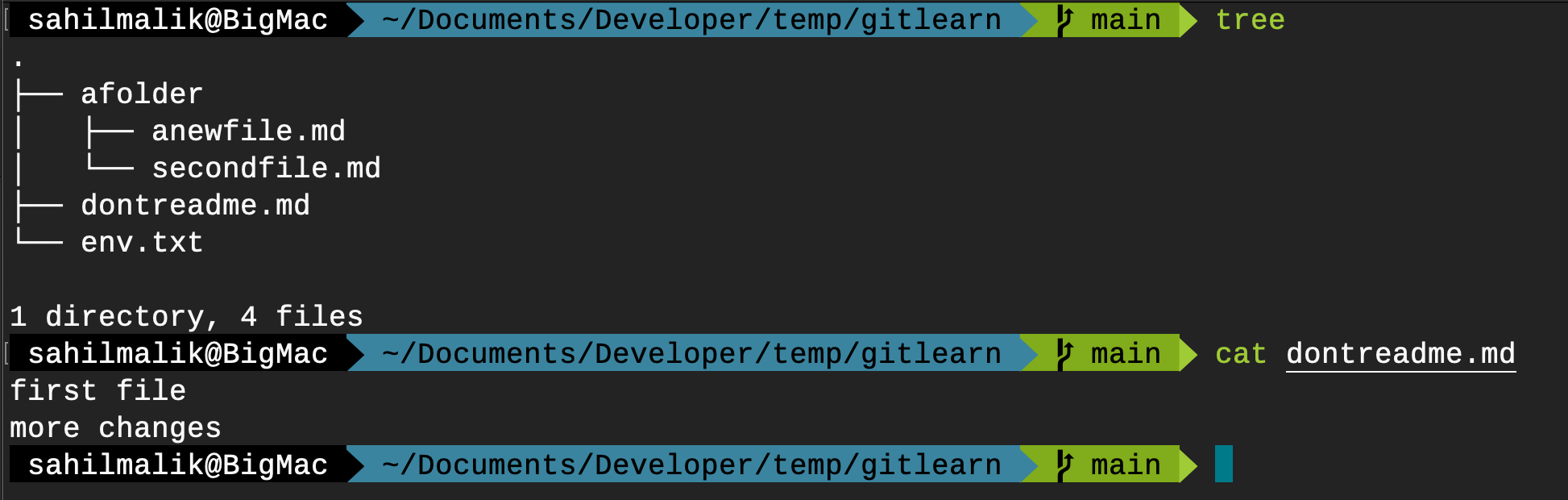
As can be seen in Figure 21, I have one file in the root called dontreadme.md, and a few other files and folders (mostly ignored by gitignore). What I wish to do is add some text to dontreadme.md and create a new file called readme.md.
echo 'even more stuff' >> dontreadme.md
echo 'brand new file' > readme.md
You can now run Git status to see what has changed. Here's a trick. The output of Git status can be quite wordy. If you want to see a quick shorthand output, which may be useful when you have a lot of files, use the following command:
git status -s
The output of this command looks like this:
M dontreadme.md
?? readme.md
This output tells you that the dontreadme.md file has been modified. But the readme.md file is unstaged.
Now, go ahead and stage dontreadme.md.
git add dontreadme.md
Run a Git status -s again. The output in text remains the same, but notice closely that the “M” by dontreadme.md has changed from red to green.
Now append some more text to dontreadme.md. Don't stage this newly appended content and run Git status -s again. This time you'll see that dontreadme.md status now says “MM”, one M is green, and the other is red. This can be seen in Figure 22.
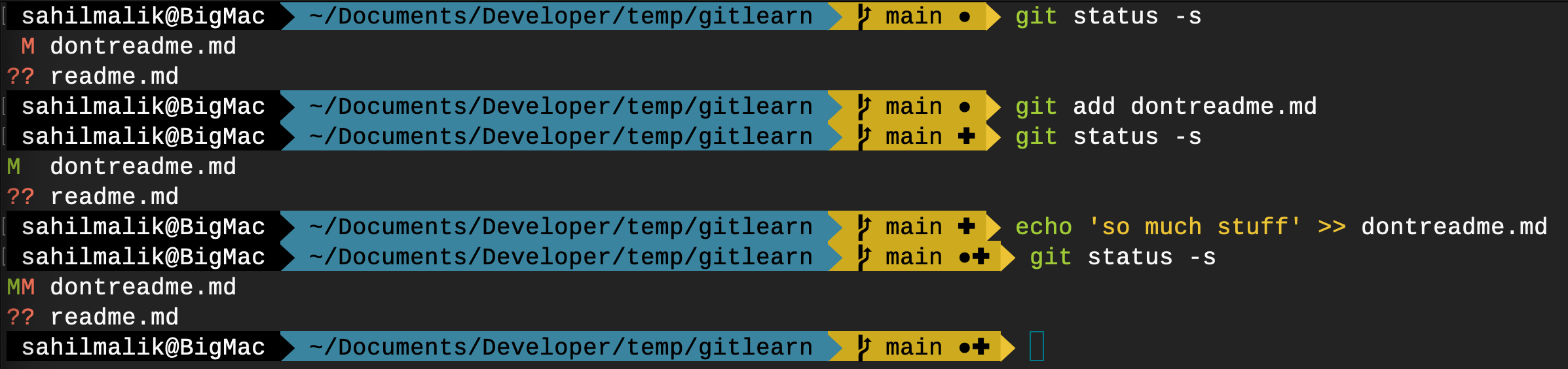
So now you have some content in remote, some content staged, and some in working copy, and all this content is slightly different from each other.
How do you get ahead of the differences between these three? The magic command is:
git diff
The output of this command can be seen in Listing 1.
Listing 1: Output of git diff
diff --git a/dontreadme.md b/dontreadme.md
index b84a4f4..d41a9fb 100644
--- a/dontreadme.md
+++ b/dontreadme.md
@@ -1,3 +1,4 @@
first file
more changes
even more stuff
+so much stuff
Let's be honest: This output is quite cryptic. Let's try to understand what this output means. This command compares your working copy to staged changes.
- The
a/andb/are directories - not real directories, but a way to show you thata/is index, andb/is the working directory. - The IDs you see after that (b84a4f4) are BLOB IDs of the files mentioned.
- The 100644 you see is “mode bits”, telling you that this isn't an executable file or a symlink; it's just a text file.
- The
---a/+++b/you see on the next line is interesting. The minus signs show lines in thea/version but they are missing from theb/version. And the plus signs show added lines inb/. - The next line starting with
@@is also interesting. The changes are summarized as chunks, and here you have one chunk. This@@line is the header of this chunk. It's telling you that starting at the first line, you have three files from thea/. And starting at line 1, you have four lines extracted.
It tries to color code it, but the color coding can frequently get messed up over ssh sessions or your local settings.
If you want to compare staged with remote, you simply use this command:
git diff --staged
Phew! This works, but it's tedious. Is there a better way?
Use VSCode as a Diffing Tool
In the real world, you use Git diffing tools. You can use any tool that supports diffing - cross-platform tools such as KDiff3, P4Merge, or, for Windows, you can use WinMerge. Personally, I prefer to use VSCode - it's a pretty nice diffing tool.
Most modern tools support this out of the box. You simply open a Git repo in VSCode and VSCode starts leveraging the output of Git behind the scenes to give you a visual Git experience. You can completely integrate diffing right inside of VSCode. Here is how.
First, instruct VSCode to act as the diffing tool for Git. To do so, edit your gitconfig file:
git config --global -e
Once your .gitconfig opens in your configured editor, add the following lines at the bottom of it:
[diff]
tool = vscode
[difftool "vscode"]
cmd = "code --wait --diff $LOCAL $REMOTE"
Now, instead of saying git diff, run git difftool. It should show you an output like this:
Viewing (1/1): 'dontreadme.md'
Launch 'vscode' [Y/n]?
If you hit “Y” on that prompt, it opens VSCode, which then takes care of showing you the diff. This can be seen in Figure 23.
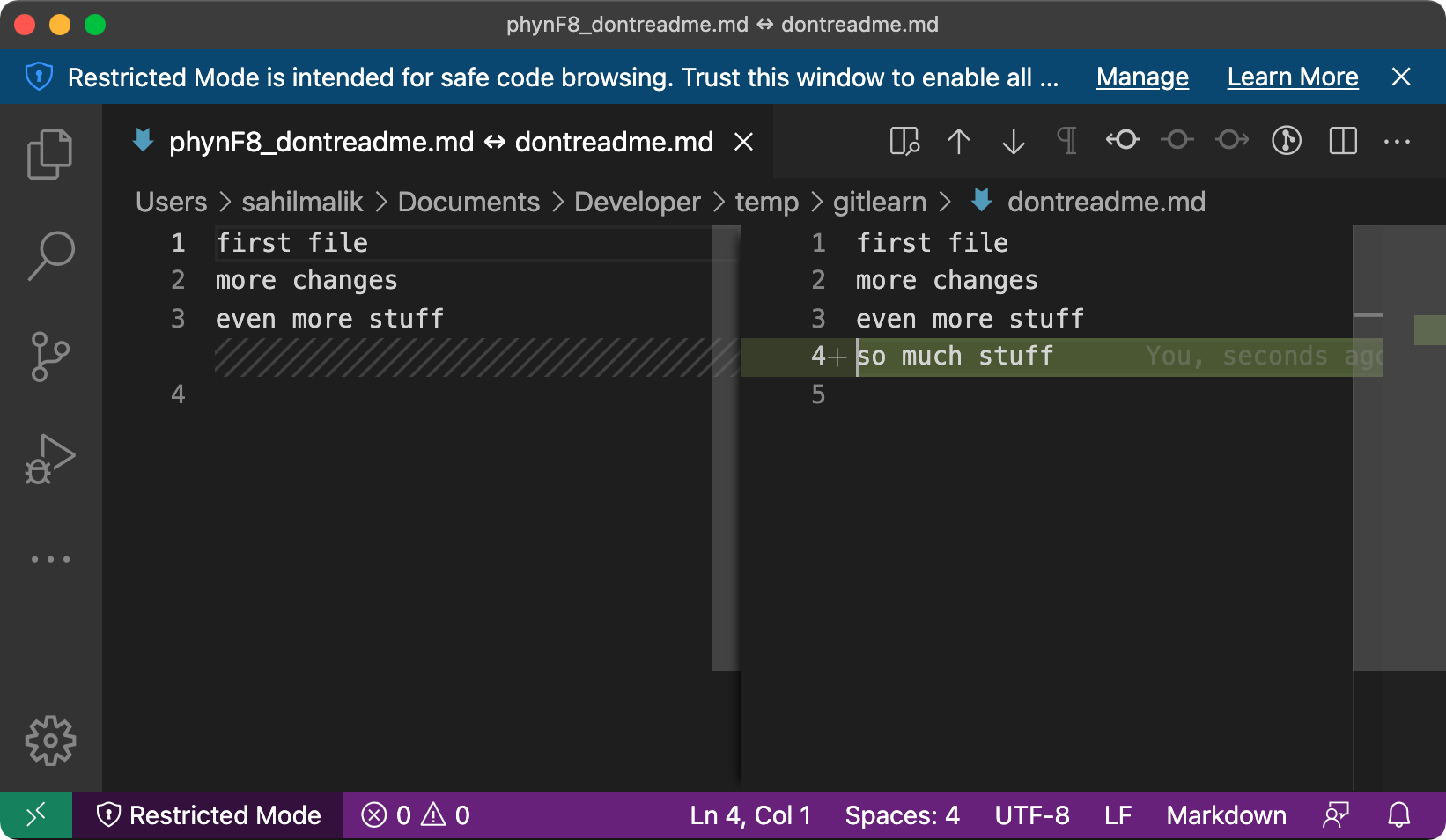
You can also try git difftool --staged to view the staged diff.
This is a more visual diff. Using VSCode is so much easier to understand than viewing the ASCII wall that git diff threw at me.
Summary
Git is an incredibly important skill. And let's be honest: There's a learning curve here. When I started writing this article, I thought I'd cover a bunch of interesting stuff that some developers consider advanced, such as merging, forking, concurrent developers working, and resolving merge conflicts. Those are skills that you'll need and use daily in a typical developer's workday. But as I started writing this article, I realized how much knowledge and how many nuances I take for granted, and before I knew it, this article started getting longer than I had anticipated.
Even to cover the basics of Git and tie it to practical real-world situations, there's an unsaid skill, assumed knowledge, that can be frustrating to discover.
I'm really curious to know: Do you consider yourself to be a seasoned developer? Do you use Git regularly? Even in these ultra-basic commands around Git usage, did you discover anything new? What complex Git situations would you like to see broken down in future articles? Do let me know.
git commit -m "That's a wrap" && git push.
