


Like any developer, I'm constantly challenged by the pace of technology. I've been in this industry for a few years, and almost anyone reading this with similar experience under their belt will agree with me that writing code today is quite different than it was many years ago. Many years ago, we paid a lot of attention to every logic path. Before any product was released, a lot of care was given to the API surface, and thinking through every possible way it would be used and abused. Products were released later, documentation was released first. Then some of us worked closely with product groups and wrote books.
How times have changed! Development today is built as a skyscraper of SDKs that we constantly update, sometimes automatically, and almost never understand the inner workings and dependencies of. Security vulnerabilities creep in after we ship code, and most companies don't have budgets to remediate or even detect these vulnerabilities. Developers ship code knowing it has bugs, as time to market and feature lists trump everything else. The recourse is the internet, constant beta state, and quick updates and frequent patches. Documentation is a soldier missing in action. Books are not something being written anymore, and it's all about time to market for guidance as videos and blog posts. Learning has become more of a reference.
Pair this with two other facts: products have gotten more complex and we depend increasingly on computers for everything, and that well-funded nation state actors have great incentives to cause damage.
And don't even get me started with AI-driven development where we aren't even writing code; we're hoping the computer will write it for us.
Boy, I'm a worry wart, aren't I? Well, when it comes to computer security, such shortcuts and speedy development will almost always land you in trouble. You need to understand how security works because your features are no good if the system isn't secure.
So I thought it would be a good idea to write an article highlighting some of the most common mistakes and misunderstood concepts I've seen that cause developers to write insecure applications. I'll keep my discussion specific to Azure Active Directory, but the protocols that are standard to many of the things I'll talk about in this article are portable to any identity platform.
Also, it's worth saying that these are not shortcomings of Azure Active Directory, but common mistakes that people make.
With that background, let's get started.
Redirect URI Pollution
Almost every modern identity protocol depends on redirect URIs. Redirect URIs is a whitelist of URIs where the identity provider feels safe sharing sensitive information, be it SAML that may post you back a SAML assertion, or an OIDC flow that posts back tokens or codes that be exchanged for tokens. Those tokens are post backs and are very sensitive. You should treat them with the same care you'd treat credentials with. In fact, I'd go one step further: Treat them with greater security than credentials. Credential leakage can be detected, but if a refresh token leaks, it's much harder to detect and could stay valid for a long time. Although resetting credentials in Azure AD invalidates your refresh tokens too, you can't take that as a guarantee. Similarly, a SAML post back that you don't secure can be used to establish a web session on a computer you never intended to establish a session with. And in this cloud-ready world where all these endpoints are on the internet, you'll soon find stolen cookies for sale on the dark web.
Every respectable modern identity platform puts some common-sense limitations on redirect URIs. You can see Azure Active directory's limitations in Figure 1.
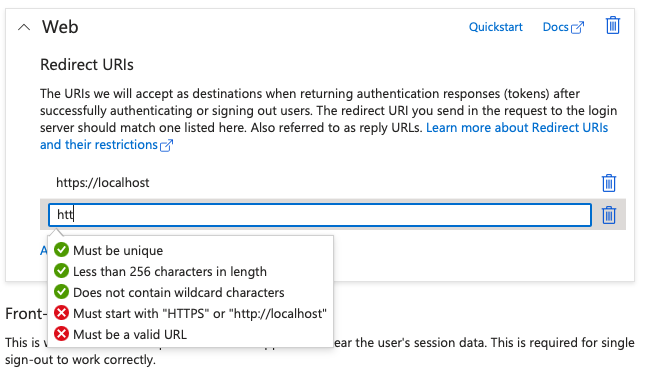
There are good reasons behind each of these limitations. For instance, requiring HTTPS ensures that the packets are not sniffable over the network. Also, browser protections ensure that a site masquerading as another will automatically be detected. Or, for that matter, a man-in-the-middle sniffer will also be detected. This is, of course, defeatable if the trusted certificate store of the client computer can be altered by the attacker. This is a common issue with certain governments or even organizations where they push certificates to your computer that can effectively allow a man-in-the-middle to sniff HTTPS traffic. So you can't assume that HTTPS is the final word in security.
Of special mention is the localhost redirect URI. It's quite common to use localhost as a redirect URI when developing locally or for certain categories of apps, specifically thick client apps that don't use brokers. The sad reality is that Azure AD does not have a good DevOps story, and yeah, lecture me as much as you wish about Microsoft Graph and the sales pitch. Developers are frequently forced to develop in a production tenant because that's where all the licenses are, and that's where all the data resides. If they do set up a separate tenant, it's quite an onerous task for them to move their app registration and all the necessary configuration, including all the users, permissions, roles, etc. to another tenant. It ends up being a lot of work writing scripts, relying on third-party products, etc.
So guess what most developers do? You guessed it. They develop in production (at least as far as Azure Active Directory goes), and there's been a battle waging for the past thousand years between developer fairies and IT ogres.
Now what URI will a developer use when developing locally? You guessed it: https://localhost. If you go back a few years, this used to be http://localhost. Invariably, this slips into production. The developer either leaves that redirect URI because they may still want to develop against the same app registration as production. Or they simply forget to remove that stray redirect URI.
The problem this causes is that a listener on any computer running on localhost can now accept your tokens, and oh, those listeners do exist and are hard to detect. Organizations also try to reduce authentication prompts, so effectively, you're SSOing a user into an app with a redirect URI to a nefarious listener that can now post your tokens to the internet. Ouch!
So best practice: Always trim down the redirect URIs to the bare minimum, and only to ones you trust, and remember that your security is only as good as the target computer.
Mixing App Concerns
This brings me to my second beef, which is overusing a single app registration and not fully understanding the ramifications of your decisions. An obvious improvement to what I described in the Redirect URI section is for the developer to have an app registration separate from the production app registration. Look, I know having a completely separate development/staging environment can be impractical when it comes to identity, but having a separate app registration, secrets, and developer identities is a quick and easy win.
But this problem of mixing app concerns goes a bit deeper than that. Not every OIDC flow is equally secure. The problem is that the flows are designed to offer you the maximum security any individual platform offers. But there's no way a single page application (SPA) can be as secure as a thick client app. This is simply because the browser can't offer the same crypto capabilities that a mobile app can. Similarly, a mobile app can't be as secure as a web app that never shares the tokens to the client app. The client computer is an untrustable surface.
So the one obvious conclusion that comes out of this is that you should always use the right OIDC flow for the right kind of app. The second conclusion that comes out of this is to offer your users the most secure app choice you can offer. For instance, if you have a choice between a SPA doing an OIDC flow to acquire an access token vs. hosting APIs within the web app and doing an OIDC flow suited more for web apps, all other things being equal, lean toward the web app approach.
But this is where things get funny. Earlier, I talked about IT ogres being onerous while developer fairies try to keep the users happy. So imagine that Olaf the IT ogre refuses to create a new app registration for you. But for a particular scenario, you need to support a web application and a thick client application. So instead of dealing with Olaf, you decide to enable public client flows in the same app as the web app. This can be seen in Figure 2 under the authentication section of an app registration.
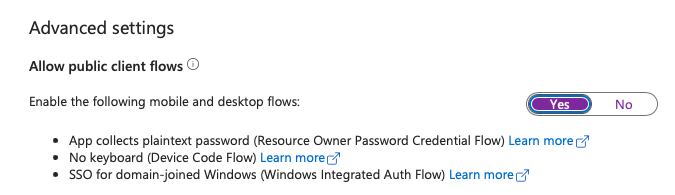
You may be thinking that you're using thick client application OIDC flows and web application flows in the same app registration. But it's important to see that you just opened the gates to also allow device code flow, windows integrated auth flow, and ROPC flow. None of these are great choices when it comes to security. Don't get me wrong, there are situations where you need them and you have no alternative. ROPC, for instance, relies on sending the user's password and username as a POST request. Device code flow involves authenticating on a separate computer than where you did your authentication. Neither of these works well with conditional access policies or device cleanliness. But you just opened the doors to these less-than-ideal OIDC flows.
What you should have done instead is restrict the less desirable OIDC flows to as low of a consent surface as possible. And separate them in a new app registration. If Olaf the IT ogre objects, have him read this article please, ok?
Manage Client Secrets
App registrations allow for client secrets. Client secrets are necessary for certain flows, such as client credential flow. Here you have two choices. Either you can use a client secret that's a string or you can use a certificate. The string is no better than a password. Actually, it's way worse. At least passwords are typed by the user, so enterprises can detect if the same password was entered into an unintended place and immediately revoke your credential. Or hashes of passwords can be compared with leaked passwords and most modern browsers will alert you to compromised passwords. Client secrets enjoy no such luxury. If they're out in the wild, they are out. The client ID and tenant ID are public info anyway. And all you need to gain an access token via the client credential flow is the client secret, the client ID, and the tenant ID. Now you can acquire access tokens for as long as you desire. What's worse, if such a client secret is leaked, there's no way to get an alert either.
It's for this reason that Microsoft doesn't allow you to create non-expiring client secrets from the user interface. This can be seen in Figure 3. They want you to rotate these secrets every now and then, although through the API, you can create non-rotating client secrets.
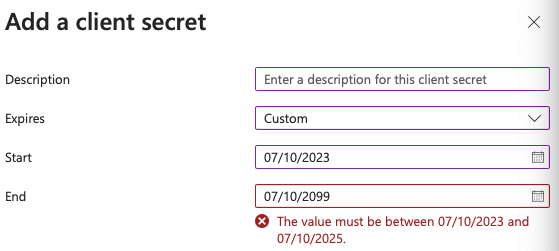
You may be thinking that rotating secrets is a giant pain. I'm not going to disagree with you there. But you need to put in procedures to check for upcoming expirations and proactively rotate them. Afterall, Microsoft does allow you to create more than one client secret, so you can achieve this rotation without outages.
However, there are a few things I'd like to recommend.
The obvious first recommendation is to have procedures in place to rotate client secrets proactively. I already talked about that.
Second, I prefer to use certificates over secrets. Secrets can leak just like certificates, so certificates aren't much better. But the slight advantage here is that when you use certificates, the protocol doesn't send the actual certificate over the wire. This makes them slightly more secure than a string. Additionally, you can add an extra layer of check to have a CRL revoke certs immediately if you detect a leak. Note that Azure AD won't check for CRL but your application can.
Third, configure an app instance lock. A common attack vector isn't stealing your client secret, but rather it's adding another secret in addition to the secret you use. When a new secret is added, especially to a privileged app, you can keep rotating the existing secret as much as you wish, and the newly added secret, presumably added by a bad actor, will continue to work. Using an app instance property lock, you can effectively lock down an app instance from certain kind of changes, such as credentials.
Fourth, check for logs for any secrets being added. Have alerts on those cross-referencing the actor that added the secret. If it's an automated job, the job should nullify the alert. If it's a user making the change, the alert should surface up to the user or an admin.
Finally, avoid using secrets at all, which is where managed identities come in.
Use Managed Identities
A very wise donkey in a famous movie once said, “What's the use of a secret that you can't tell anyone?” I have a slightly different take on that. The best secret is one that you don't know, so you never have to worry about leaking it. This is exactly what managed identity gives you. Managed identities are service principles whose credentials (in this case, certificates) are managed entirely by Azure. They're never shared with an app, and they're never shared with the user. They remain out of reach of any surface that could leak them. Additionally, they're automatically rotated for you. How often are they rotated? I don't care. Because I don't have to do that rotation and update a number of apps and inform users when such rotation is occurring.
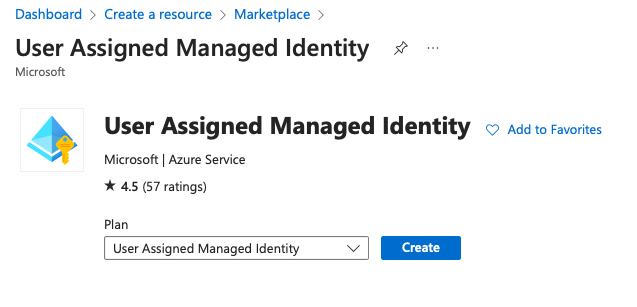
A managed identity can work on its own, where the service principal backing the managed identity can be given certain permissions. Beyond that, you can acquire access tokens and call APIs such as Microsoft graph. Because it's a service principal, you're limited to app-only permissions. Usually, you'd do this by creating a new user-assigned managed identity from the Azure portal or via the MS Graph API. This can be seen in Figure 4.
Alternatively, you can also assign an Azure resource a managed identity. For example, you can have a virtual machine assume a managed identity. Here, when a process running on the virtual machine wishes to reach out to an API under that managed identity's identity, it can ask for an access token for that managed identity, while the process is running on the computer. Here, you have a choice of using a system-assigned managed identity or a user-assigned managed identity. A system-assigned managed identity is cleaned up for you automatically when the resource is deleted, and it's tied to exactly one resource. A resource example might be a virtual machine, an app service, or many other such resources in Azure.
A clear disadvantage of a system-assigned managed identity is that you can't create and pre-configure consent permissions on the managed identity ahead of time and then assign the identity to a resource. Imagine what a problem this becomes in DevOps scenarios where the resource is being upgraded when the upgrade effectively means delete and reprovision?
Because managed identities are more “trustable” than identities whose secrets can leak, the access tokens are valid for longer too, typically 24 hours.
Additionally, you can use workload identity federation to configure a user-assigned managed identity or app registration in Azure AD to trust tokens for an external identity provider, such as Github, Google Cloud, AWS, or others. This is really amazing because this effectively allows you to use the power of managed identities across tenants and even across clouds.
Protect Your Secrets
I almost missed mentioning this. Secrets are like plutonium, and, well, as much as I suggest that you use managed identities and workload identity federation, you'll find situations where you need to manage secrets yourself. In circumstances like this, you should use a product such as Azure Key Vault or HashiCorp Vault to store secrets. You can then use something like managed identity to acquire the secret at runtime, and either not save it locally, or save it in a trusted encryption, such as hardware-backed encryption. Note that products such as Key Vault should not be used for high IO scenarios. If you have to reach out to Key Vault every time you need the secret, your app won't scale. But it serves the need of storing your credentials safely very well.
Understand Token Validation
SAML has SAML assertions, and OIDC has access tokens, refresh tokens, and ID tokens. You also have PRTs (primary refresh tokens), which I like to call a powerful refresh token, but let's leave that out of the discussion for now.
The important part here is that in this copy/paste-driven development world we live in, it's important for you to understand how tokens are validated. I'll leave SAML for another day because it's so different; let's focus on OIDC for now.
In OIDC, you have three kinds of tokens.
The ID token is what establishes the user's identity. The intended audience for this token is your app. Your app receives this token, validates it, and issues its own mechanism of maintaining the user identity, such as a cookie for a web session.
The access token is what establishes your ability to call an API, and it may or may not contain the user's identity. The access token is valid for a shorter duration of time, typically an hour, although it could be more or less, depending upon various factors. The intended audience for this kind of token is your API.
The refresh token has a much longer duration, intended to be used to gain new access tokens so the user isn't shown an authentication challenge every time the access token expires. The validity duration of the refresh token depends on the kind of application you're writing, and not every kind of OIDC flow allows for a refresh token.
There are other kinds of tokens, such as auth_codes that play intermediary roles depending on the kind of flow you're using.
There are a few important things you need to understand about token validation.
In Azure AD, refresh tokens are opaque. You cannot decode them; they're not intended for you to decode. You don't validate them, you don't decode them, you simply use them when you need a new access token. It's up to Azure AD to validate them and issue you an access token using them. Also, Azure AD has the prerogative to revoke your refresh tokens without informing your app first. So don't rely on application architectures that rely on refresh tokens never getting invalidated. For instance, long-running processes under the user's identity using a refresh token is a perfectly valid architecture pattern. That's what the “offline_access” scope is intended for anyway. But build an escape hatch to alert the user if the refresh token gets invalidated, so the user can reauthorize the offline process, which is basically getting a new refresh token with an interactive auth flow.
ID Tokens and Access tokens are JWT tokens in Azure AD. OIDC does not mandate these to be JWT tokens, and at some point, they may not be. For instance, it's possible that the identity provider (Azure AD) in this case, could move to encrypted access tokens. Encrypted access tokens would be a good improvement because they're intended for the API, not the app. The API would have the ability to decrypt and decode them. The app, on the other hand, can't decrypt them and therefore decode them. This is because the app has no business reading and unpacking an access token. This is a common mistake I see, where the app decodes an access token and makes logic assumptions based on it. You're setting yourself up for failure by doing this.
Finally, ID tokens are intended for your app. These are also JWT tokens as of now.
Both access tokens and ID tokens are intended to be validated, albeit by different parties, but the validation logic has a few things in common.
First, the tokens are comprised of three parts: the header, the body, and the signature.
The header gives you “packet” information. Think of it as the label on your package. It tells you what kind of signature algorithm is used, and where to find the keys to validate the signature. Azure AD has the private key to sign the access token or ID token. It never shares the private key and it rotates the public private keypair every now and then. The public key is available to you at an anonymous URL. You can use the public key to validate the signature. In Figure 5, you can see the header for an access token I just acquired from my tenant.

Of special note is the “alg,” which stands for algorithm, and the “kid” or key ID claim. The idea is that Azure AD is telling you that it used RS256 to sign the token, and you can find the keyID from the JWKS URI, which resides at the following URL:
https://login.microsoftonline.com/<tenant_id>/discovery/keys
You can see the key ID for my app in Figure 6. I got this as a simple GET request to the JWKS URI.

To validate the signature of the token, graph the signature key from the JWKS URI. This is where I should mention one of the biggest issues I see so many applications make a mistake in.
Azure AD will rotate the key every now and then. You're supposed to follow the following pattern:
- First, check if you have the signing key. If you don't, ask Azure AD for it and cache the key.
- Now, use the cached key to check the signature of the token.
- If the signature fails, re-query Azure AD for a new key, just in case the key has changed.
- If the key has changed, recheck the signature with the new key. And yes, cache the new key.
- If the key hasn't changed, fail the validation of signature.
The problem is that OIDC doesn‘t dictate this key caching and key rotation. There are so many OIDC compliant SDKs, and even more hand-written validations that fail to follow this pattern. I'm serious, if I had a quarter for every time I saw this problem, I'd be writing this article from a private jet in a jacuzzi surrounded by, well, maybe the pilot. Anyway, I don't have a quarter for every time I see this problem, so, back to reality.
Microsoft SDKs, also known as MSALs, will perform this caching logic. But many third-party libraries don't. Let's be honest: Many MSALs don't have token validation logic, leaving developers to figure this out on their own.
And this is where we're done talking about signature validation issues. But token validation has other common problems.
When you validate a token in Azure AD, you must validate, at the bare minimum, the audience and the tenant, and then beyond that, per your authorization logic, the subject and other claims such as roles and scopes.
What would happen if you didn't validate the tenant? Well, then you could just set up another Azure AD tenant and set up the same audience and pass your validation. Hopefully you're validating the subclaim (subject), but if you weren't, I'm in. Yay!
How confident are you that the copy/paste code from the internet that you used is indeed performing all this validation, and caching the signature validation cert? Are you sure? Better double check.
Abusing Claims
OIDC defines a bare minimum standard. It allows you to add claims that the standard doesn't define but doesn't prevent you from adding. There are a few problems here.
First, this gives you the leeway to stray away from the standard. I suggest that you don't stray away from the standard. Do the bare minimum validation that OIDC requires, and then add more on top as necessary and very judiciously.
Second, don't use tokens as a database. Tokens are supposed to be validated at every authorization step. The larger the token, the worse your performance will be. In fact, in many situations, it will break your application logic. Many platforms or even SDKs will cap the token size. Browsers are especially notorious for this. I've seen well known applications (that shall remain unnamed) with ridiculously low limits like 256 characters. My South Indian friends have very long last names, and I have seen even the bare minimum token go beyond the 256-character limit.
Additionally, Azure AD has some common-sense protections built in. For instance, if you're a member of groups, and you're a member of many groups, you can configure your application to issue the groups claim. But you can't really rely on this claim. Beyond a certain number of groups, you get a group overage claim that basically says, “hey the token got too large, but you can query MS Graph to get the groups.” Well, if the reliable way to get groups is to call MS Graph anyway, why didn't I just call MS Graph in the first place? That's what you should have done. Additionally, when you start using dynamic groups or nested groups, you start running into reliability and performance issues. TLDR: Don't use the groups claim; it works nicely for simple demos.
Finally, I must talk about claims transformation, but let me talk about that in the light of immutable claims.
Immutable Claims
Certain IdPs, including Azure AD, allow you to tweak the values of claims. Luckily, Azure AD won't let you do so with any claim. Claims that you cannot and should not change are called immutable claims. Those are the claims that you should base the user identity on. This is the NameID claim in SAML (which is inside the subject claim) or just the subclaim in OIDC.
Azure AD tries its best to keep you from shooting yourself in the foot. But it's up to you, the application author, to understand these nuances and not make mistakes. For instance, a common mistake is to base the user's identity on an “email” claim. Why? Because UPN and email look so similar, often the same. Why is basing the user's identity on email a bad idea? Because the email address can change, just like the user's name can change. Essentially, I could change my email to satya.nadella@microsoft.com and I'm now the CEO of Microsoft. I hope you were validating the tenant ID claim. But what if this was an insider attack? Changing one's email is not something that requires a high privilege.
Specifically for this attack vector, Microsoft now has protections. Apps created after June 2023 that issue this claim will get a blank value that the admin can change the behavior of. However, this doesn't affect existing apps that are already making this mistake. And yes, if you wish to shoot yourself in the foot going forward, it won't stop you from that either.
Long story short, always rely on immutable claims in Azure AD to establish user identity.
Understanding Trust
Azure AD has a concept of an external identity provider where Azure AD can delegate identity establishment to an external identity provider. There's also a similar concept called federation. And another loosely similar concept of “guest accounts” where your Azure AD tenant allows an external visitor's account, whose identity is established by another Azure AD tenant.
In all these situations, you're trusting an identity provider that isn't under your administrator's influence.
You may have done everything right, rotating secrets, validating tokens properly, even checking for immutable claims, and none of those will keep you safe if the external identity provider you trust isn't trustable.
Allow me to explain. Let's say I allow guest accounts from someshadyorg.com, and their CEO happens to be someniceguy. Because their identity provider is untrustable, they can effectively send me an immutable claim value for someshadyguy that effectively asserts that someshadyguy is someniceguy. There's nothing my Azure AD tenant or app can do to prove it otherwise, and I just have to “trust” this other org.
How do you guard against such problems? Well, the obvious answer is to establish trust with audits and reviews, and put safeguards in place. In Azure AD, this is as simple as working with verified tenants, validating tenant ID claims, and communicating with your customers what their Azure AD might be federated/delegated to trust.
Additionally, you can establish a limited blast radius in case of a breach. Guard like a hawk what guest accounts can and can't do. Establish alerts and audits, and use access packages and access reviews to trim the access down to the bare minimum. In Azure AD, use conditional access policies to establish location lockdown, device health, and authentication strength.
Summary
I started this article with an alarmist approach. I don't regret that. In the furious and aggressive pace of innovation, I worry that we, as an industry, are collectively underestimating the importance of security. Every other day, I see some news article of a breach of some major organization and leaking data.
I wish I could say that these organizations have learned their lesson, but I see the same org get targeted again, and no, they didn't learn a darn thing. I'm so tempted to name names here, but I'd rather not get in trouble.
Let me just say, though, that these are some very reputable companies, with millions of customers, and that you're probably a customer of some. When this information is leaked, guess what? The cat is out of the bag.
Large organizations are woefully slow. They fight over budgets while their secrets leak, they clamor to add features under ever-tightening deadlines, and guess what gets the cut? Security, because it doesn't affect the next quarter.
Can we please stop doing this nonsense as an industry and give security the importance it deserves?
All right, time for me to get off my soapbox. Stay safe and double check your apps.
