


I might as well have called this article “How to Validate an Access Token,” right? I mean, how hard could it be to use an SDK such as MSAL and call a method to validate an access token? You can find code examples on Stack Overflow, or GitHub Copilot could literally write this for you.
When I look at all the tech keynotes, or sales pitches, everyone talks about features. It's natural to get excited about what we see. But as you appreciate the 14-inch screen in your fancy new car, don't under estimate the importance of that little cotter pin holding your brake pads in place. That cotter pin is identity and security that, arguably, makes for the world's most boring demos, and is probably the most important bit holding your life together.
As it turns out, acquiring an access token and validating it can be quite nuanced, and a lot of history and thought and experience have gone into it. Having worked in some of the world's largest most reputable firms, I've also seen the wheel being reinvented, mostly very poorly, when perfectly good standards exist that are time tested, peer reviewed, and hacked beyond recognition, so their vulnerabilities are well known and easy to understand.
Some days, I feel like Cassandra, uttering prophecies and not being believed. Anyway, I digress. Let's talk about Web API authentication.
What's Involved in Web API Authentication?
In my previous article in CODE Magazine, I talked about web app authentication. I discussed a lot of background and reasons why authentication in modern web applications works the way it does. But I left the discussion at logging in. In other words, I left off where the application knows who you are and a session is established between your browser and the web server.
Identity and authentication are so much more than that. For one thing, the process of establishing identity and maintaining a logged in session is quite specific to the platform of choice. Beyond logging in, most applications rely on additional functionality exposed as services. These services are frequently exposed as REST APIs and frequently require authentication. This may be because they wish to give you information specific to the user or perhaps secure certain information.
A number of questions arise here.
Does it have to be a REST API? Let me answer this right away. Although most of the APIs we see these days are REST APIs, they don't have to be. In fact, in certain instances, REST API isn't the right choice, but the non-REST API can still work with OIDC.
There are more questions.
- How does the application acquire an access token?
- When does the application acquire an access token and how long does it keep it for?
- How and when does an application renew an access token or does it ask for a new one?
- Does anything change if you're working on a web farm like architecture? What if you have containers, Kubernetes, microservices?
- How can the application authenticate itself to the Web API?
- How can the application authenticate itself and the logged in user to the Web API?
- Can the Web API forward the identity to another API?
- Why is it architected the way it is and how does it scale to extremely high transactions throughput, both at the API level and the identity provider level.
Okay so clearly, this is a bit more involved than calling a method to validate an access token and ship to prod. In fact, I can almost guarantee that if you copied and pasted canonical code that was designed to teach you concepts on a frictionless surface, that code will simply melt in production.
This and much more in this article.
Validating an Access Token
I raised a number of concerns when architecting Web API authentication. OIDC has considered that many of these are well known patterns. Let's have a step-by-step discussion and see how OIDC and Microsoft Entra ID have handled many of these concerns.
Who Does What?
The first thing to understand are the parties involved here. At the heart of it, Web API authentication (and authorization) involves validating an access token and reading its contents. There are three parties involved here.
- The Identity Provider, such as Azure AD, Amazon Cognito, or any other standards-compliant identity provider that issues an access token.
- The party that requests the access token, which is your application. I'm going to refer to this as the RP or relying party.
- The party that validates the access token, which is the Web API.
This path is shown in Figure 1.
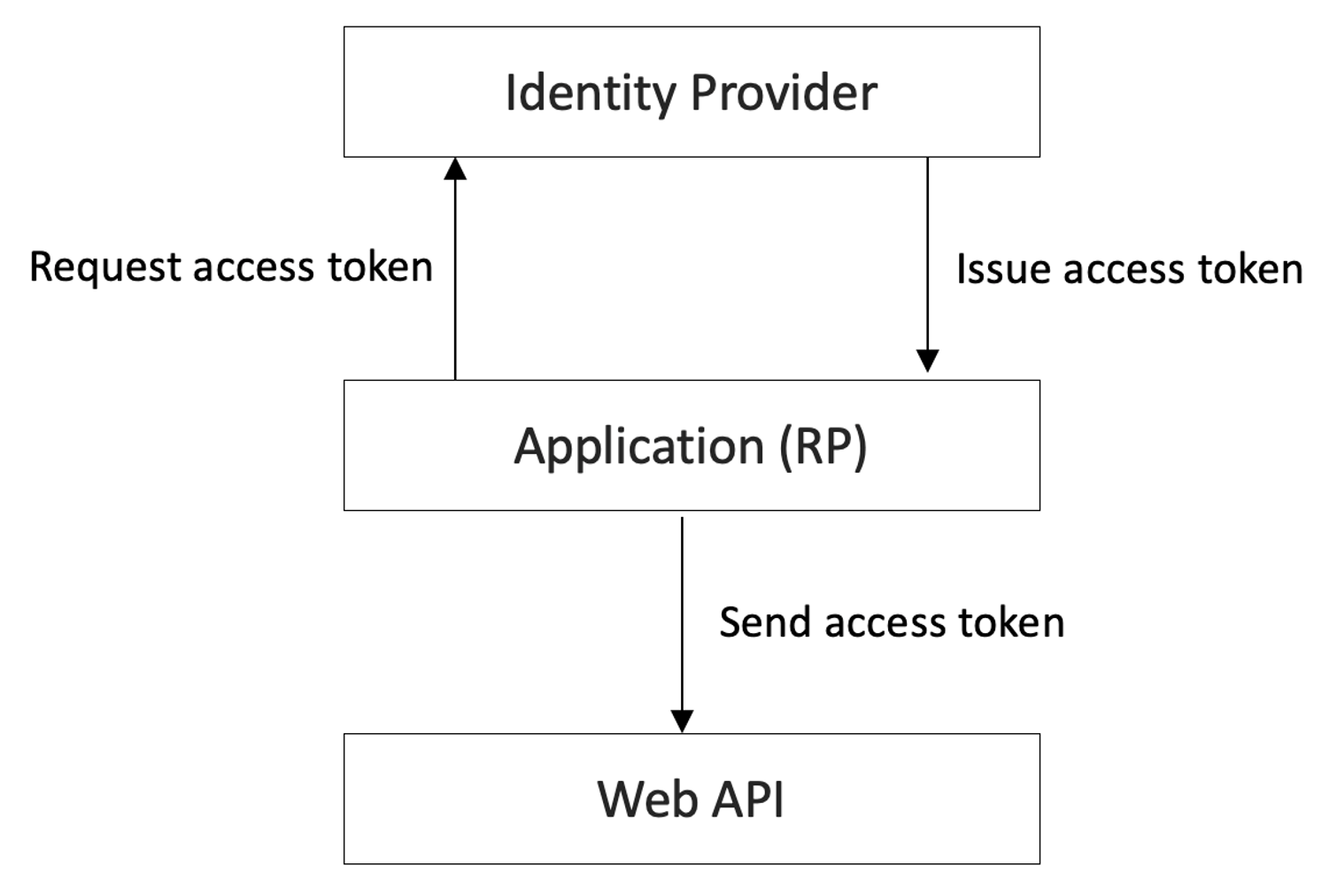
The relying party can be a public client or a confidential client. Public clients reside on surfaces that you don't trust, and therefore cannot store a secret. Examples include mobile apps, SPA applications, and desktop apps. Confidential clients can store secrets securely, and examples include daemons or web applications. You'll note that there are some concerns that are unique to public clients, and some that are unique to confidential clients.
The access token is typically formatted as a JWT, although OIDC doesn't mandate it to be any particular format. In fact, certain identity providers issue opaque access tokens, which, to you, looks like a bunch of gibberish. However, because JWT is one of the most common formats, let's use that for this discussion. A typical access token has three parts, as shown in Figure 2.

There's the header, there's the body, and there's the signature. Before I dive into the details of these, at a high level, the final recipient of this access token, which is the Web API, has the responsibility to unpack this access token and validate it. Validation involves two steps.
First, it ensures that the access token hasn't been tampered with, which is done via validating the signature, the last block of the access token. The signature is validated with the help of the header, which is the first block.
The second step is to validate the claims inside the access token. That's the body of the access token.
The important take-away here is that only the Web API must unpack and validate the access token. Because tokens are mostly JWT (JSON web token), it's a very common mistake for the relying party to unpack the access token. The relying party is the acquirer of the token and it must never unpack the access token. In fact, the identity provider reserves the right to encrypt the tokens and effectively make them opaque to the relying party, such that only the final recipient, the Web API, can work with the tokens.
How Are Access Tokens Acquired?
At this point, you know that access tokens are requested by and acquired by the application or the relying party (RP). And the RP sends them to the API. The RP, when requesting an access token, does so by sending a POST request to the token endpoint of the identity provider. For the identity provider to issue an access token, it must know two bits of information.
First, it needs to know what the token is intended for, which is the audience of the requested token and sometimes the scope. The identity provider looks at the audience and understands, thanks to an app registration ahead of time, what specific claims the audience (the Web API in this case) requires and it then mints such a token.
Second, the identity provider must trust that the incoming request is valid and secure. Afterall, an access token issued to the wrong party is like handing out a time-limited password. There are components of the incoming request that enable the identity provider to trust an incoming request. The specific components depend upon the exact OIDC grant being used.
With this information, the identity provider issues an access token to the relying party. The relying party should treat that as an opaque string and play it to the API as needed.
This access token is valid for a specific duration of time, so the relying party should cache this token. The duration of the access token validity is typically available as claims inside the body portion of the access token.
But this leads me to another interesting question.
When Does the RP Request an Access Token?
One message that I've been repeating over and over again is that the relying party doesn't unpack the access token. The other bit of information that I've conveyed is that the access token is valid for a limited duration, typically an hour.
It's worth noting that you can't blindly rely on this duration of an hour because the identity provider has the right to change the duration of an access token as necessary. In certain situations that are more trusted, the issued access token might be valid for a much longer duration. For example, in the case of a managed identity, the issued access token is valid for 24 hours.
But this leads to an interesting problem, if the RP is unable to unpack the access token, and the validity of the access token is embedded in claims inside the access token, how is the RP supposed to know when to request a new access token?
There are three alternatives here.
The first alternative is to simply go to the identity provider whenever you need a new access token. This is a very poor alternative, because it requires an additional network hop every time you need to call a Web API. Not only does it put an additional load on the identity provider, chances are that you're going to get throttled and have an unreliable application.
The second alternative is for the identity provider to issue an access token to the RP. The RP caches that token and keeps using it until that access token results in an unauthorized response. At that point, you can choose to go back to the identity provider and ask for a new access token. This is also a poor alternative because you may get an unauthorized response for many situations. Also, this approach relies on an error before your application works. I like to compare this with planning your city around ambulances. It would be better if you planned the city around traffic lights. In other words, you should avoid accidents rather than plan for them.
The third alternative, which Azure active directory uses, is that Azure Active Directory - I'm sorry, Entra ID - issues you an envelope, in addition to the access token. This envelope includes information on when the access token is going to expire. That looks similar to this snippet.
{
"token_type": "Bearer",
"expires_in": 3599,
"ext_expires_in": 3599,
"access_token": "..."
}
The RP should read this header and, a couple of minutes before the access token expires, issue a request to acquire a new access token. It's worth noting that more than one access token can be valid at a given time. The correct verbiage over here isn't renewing an access token, it's acquiring a new valid access token. And if you use any of the standard MSAL SDKs, they acquire new tokens silently for you, about five minutes before token acquisition. Why not exactly five minutes? This is to introduce jitter, so the whole world doesn't ask for access tokens together after any downtime.
How Is an Access Token Validated?
The RP sends the access token to the Web API. The Web API now needs to validate this access token. There are two main parts here.
The first is that the Web API needs to be able to trust this access token. In other words, was this access token tampered with by a man-in-the-middle attack? Was this access token issued by an identity provider I trust, etc.?
The second part is that the Web API needs to be able to unpack the access token and be able to examine the claims inside the access token. At the bare minimum, it needs to know that this access token contains the necessary identity that the Web API trusts. Also, because most access tokens are valid for a short duration, the API needs to know if this access token is still valid. And then there are additional claims that the Web API can use to establish authorization rules. Depending upon certain standards, like proof of possession, there may be additional information in the access token that allow the Web API to prove the identity of the caller. This keeps things safe from an exfiltration attack.
Both of these steps involve unique challenges and approaches. A naive approach would be to simply take the access token and have the Web API play that access token against the identity provider, and get back information about the validity and the authenticity of this access token. As you can imagine, this approach sounds very tempting and very logical.
It's no surprise, therefore, that OIDC already has tried this at one point. In fact, that's exactly what the introspection endpoint does. Additionally, I can tell you that I've seen plenty of homegrown identity systems make this mistake. With every method call, they call a central authorization server, play the token to it, and get back validity and authorization information. This is extremely short-sighted for many reasons.
The obvious problem here is scale. Can you imagine if every Web API around the world, on every request, had to rely on a central service like Entra ID before the Web API call succeeds? It wouldn't perform at all, and it would create a huge bottleneck on Entra ID, or, for that matter, on any identity provider.
The other problem is that it creates a central point of failure. A compromise of that central identity system compromises all of your applications instantly. By extension, downtime of that identity provider means downtime for all your applications, instantly.
A counter argument I've heard is that if I don't do such real-time checks, how can I trust that the information being validated is up to date? That's a fair argument. This may be applicable in the cases of, say, bank transfers. You want to know exactly at that point whether the user's account is active before the user is allowed to perform an action. But this is a false argument, because it's very easy to create a delta between a slow and a fast network. Just use the ping times to your advantage and fool two ends of the system on opposite sides of the globe with different versions of the truth. In practice, instant real-time checks don't exist; given the speed of light, they're a theoretical impossibility. The work-around to that is limiting the damage, maintaining enough journaling information, and the ability to roll back and track down the responsible perpetrator via good logs.
Playing the access token to the identity provider in order to validate an access token is a showstopper. You need an alternative approach, and luckily one exists. Here is how an access token is validated.
As I mentioned, there are three parts to an access token: the header, the signature, and the body. Let's first understand how the signature is validated.
To validate the signature, you first look at the header. I got myself an access token, and the header looks like Figure 3.

The header tells me that this is a JWT access token, and it uses RS256 algorithm to sign the token. RS256 is a fairly secure asymmetric algorithm. Certain identity providers also support symmetric signing algorithms, which are great for air-gapped environments. But back to RS256, the “kid” is the thumbprint for the public key used for validating the signature of the token. The x5t is the same as kid, but only used in v1.0 access tokens.
The idea here is that Azure AD has signed the token using its private key. Given the kid, I can find the public key and validate the signature. So how do I go about finding the public key?
Any OIDC IdP should implement the OpenID Connect metadata endpoint. In the case of Entra ID, you can find this at the following URL (line broken to facilitate the print version of the magazine):
https://login.microsoftonline.com/tenant_id/v2.0/
.well-known/openid-configuration
When you visit that URL, it downloads a JSON object. This URL is anonymous. This JSON object contains a wealth of information about the identity provider. It tells you what the token endpoint is. It tells you what response types, subject types, algorithms for signing, scopes, etc. are supported. It tells you what auth methods are supported and a bunch of other useful information. You can see this in Figure 4.

A curious property there is the jwks_uri. Go ahead and visit that. From the URI, you should download a JSON object, with the keys. Specifically, the one I'm interested in can be matched by my kid claim in the header. This can be seen in Figure 5.

Note that the kid claim value from Figure 3 matches the kid property in Figure 5. Why are there multiple keys? It's because Entra ID automatically rotates keys. And there's some parallel time between multiple keys being active. The idea is that your Web API should download this key and use it for token signature verification. If the verification fails, only then does it redownload a new key. If the verification still fails, you know you have an invalid token. But here's the big benefit here: You can validate token signatures without having to send the token to Entra ID all the time. In fact, keys rotate approximately every two weeks, so the reach out to Azure AD to validate a token is quite infrequent. Again, it goes without saying, don't hardcode these two weeks into your code. MSAL SDKs manage this for you, but the right pattern is to validate, and if validation fails, ask for a new key and try validating again. If it still fails, send back a 401 unauthorized.
That brings me to another common mistake. When developers don't use SDKs, and prefer to roll their own token validation logic, this downloading and caching the key is the most commonly missed step. This means poor performance, but also potentially throttling your application down. Additionally, many SDKs don't enable key refresh by default. For example, the golang jwk package, by default, doesn't refresh keys. You have to write the logic for it. And the keys are lost on application restarts.
That's another reason why I'm not a fan of copy-and-pasted or wizard-generated code. There are too many poor shortcuts.
How Are Access Tokens Cached?
There's one concern that I seem to be brushing aside, which is how, exactly, these access tokens are cached on the relying party side.
In fact, the problem goes a little bit deeper than that. When you request a new access token, you don't want to prompt the user for their credentials again. Imagine if you're using Microsoft Teams, which is built up of many sub applications. Each one of these applications needs an access token. All of them expire at different times. Imagine if each one of these component applications starts prompting the user for their credentials every single time an access token is about to expire. That would be completely unusable.
In the real world, you use things called refresh tokens and primary refresh tokens. For the purposes of this article, I'll treat them similarly and just say that they are super long-lived tokens that allow you to request new access tokens. In reality, there are some nuances and differences between those two kinds of long-lived tokens, but let's leave that for another day.
Typically, this refresh token is what you use to ask for a new access token. This means that the refresh token needs to be stored securely, along with the access token.
The best practice is to not store access tokens in any kind of durable storage. This means: Don't write it on the disk. It should reside in the ephemeral memory on the server, so a reboot of the server simply means that you request a new access token. This is generally a decent compromise, because access tokens are valid for a short duration anyway, and it's reasonable to expect that a typical server has an uptime of greater than an hour, which is the typical duration of an access token.
I know that there are exceptions to this rule, and that certain IoT scenarios or even microservices architecture require services to come up and down all the time. Containers are spun up on demand and destroyed on demand. Those situations need special treatment, and, in many circumstances, access tokens aren't the right approach there. However, for most applications that exist today, this is a reasonable compromise.
As another extension to this logic of keeping access tokens in memory is that web servers running on different web front-ends, or containers running in Kubernetes, don't share access tokens among each other. Again, this is a reasonable compromise, because the moment you start sharing access tokens, you open a whole new can of worms around sharing them securely. If you can get away without sharing access tokens, there's a whole universe of problems that you don't have to worry about. So don't share access tokens.
This leaves the problem of refresh tokens. Refresh tokens, unlike access tokens, are valid for a long duration. This could be 24 hours for single page applications, three months for public client applications, or three minutes with a sliding duration for confidential clients. None of these durations are something you should bake architectural dependence in your logic on.
This is because the identity provider can choose to change the validity of the refresh token at any point. Additionally, the identity provider from the server side can choose to revoke an access token at any point based on any condition.
One thing is clear. Refresh tokens are a more complicated problem than access tokens when it comes to caching them.
If you have a simple application that runs on one web server, you just need to maintain a cache of refresh tokens on the server side. There are some considerations you need to keep in the back of your mind. You need to ensure that this refresh token cache is safe, and therefore encrypted. There are concepts on every operating system to keep such content encrypted in such a way that no human being can access it, but your application can access it.
It gets more interesting than that. Even for a single web server application, access tokens may or may not contain the user's identity. This, by extension, means that refresh tokens may or may not be specific to users. Think of a typical web application that users access through a browser. The refresh token used to acquire an access token on the user's behalf doesn't ever reach the user's desktop. This is a basic safety issue. The user's desktop is not a trusted surface. Therefore, you need to maintain refresh tokens on the server side for each user and ensure that they don't step over each other. This is illustrated in Figure 6.
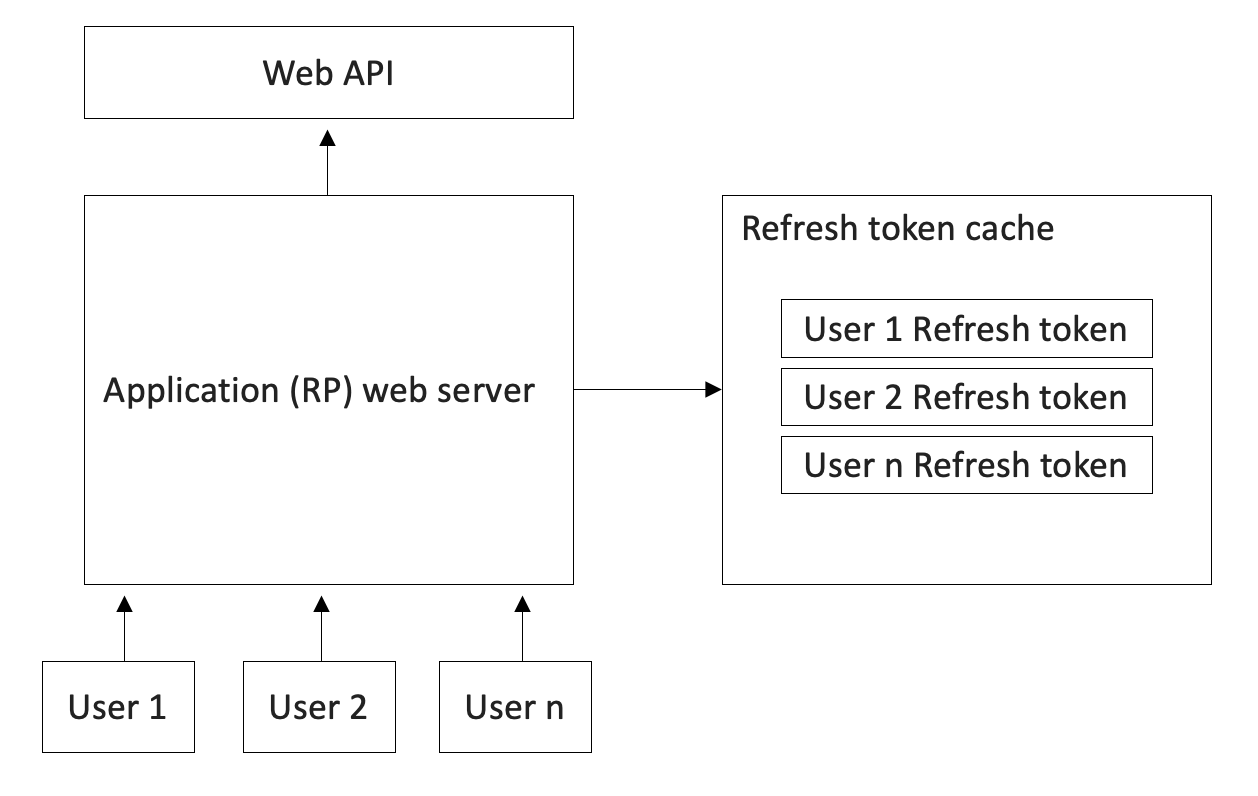
This is a pretty important responsibility. Experienced developers have numerous concerns boiling in their minds already. This cache is easy to create, but how and when does it get cleaned? How do you scale it?
One obvious clean-up job is that if a refresh token is deemed invalid, the refresh token should be deleted out of your cache. That's easy. But what about refresh tokens about which you never get notification from the identity provider that this refresh token is invalid. In fact, the identity provider will never send you such a notification. It's only when you try to use such a refresh token that you realize it no longer works. Again, a reasonable compromise is that you have a clean-up job that cleans up these refresh tokens after a certain period of time. This may be dependent on the platform and application needs. A reasonable duration is two or three months. Most caching solutions have expiration policies, which leads me to an important note: A database is a poor choice for storing refresh tokens. A poor choice, but nonetheless widely in use.
This may raise some eyebrows. Why do I say that a database is a poor choice for storing refresh tokens? The reality is that a database doesn't offer the concepts of most industry-standard caching solutions, such as expiration policies, etc. You have to write code around all of that yourself. Additionally, it's extremely tempting for an inexperienced developer, after you leave, to simply connect to that database and start sharing the cache in a way that you never intended. Just use a solution like Redis or Memcached, etc. Again, I'd like to temper this with the expectation that architectural decisions are never absolute. There may be certain situations where you want to use a database-based cache, for example, maybe you don't want to pay for a caching product.
Now let's take the discussion closer to Entra ID. Entra ID is supported by SDKs in various languages, typically referred to as MSALs, or Microsoft Authentication Libraries. Various MSALs support different feature sets, and they all aspire to remain similar to each other and aspire to offer equal functionalities across platforms. At the time of writing this article, MSAL.NET and MSAL Node both have a pretty decent support for caching and they follow a very similar pattern.
Both of them offer both in-memory and persistent caching. In-memory is great to get you started, and enough for simple applications. The downside, of course, of in-memory cache, is that any application restart means you lose the memory. This means the user has to log in again, which might just be a matter of SSO via Entra ID. But when that SSO doesn't work, the user sees a random Azure AD log in dialog, which means a poorer user experience. Still, considering the simplicity of this solution, it's a great alternative for simple scenarios. As a rough guesstimate, if each token is 2KB and look ups have an additional cost, think in terms of a few hundred tokens being cached as an okay upper limit to this approach. Less, if you have a low memory footprint container.
For many real-world applications, you're going to need a persistent cache. MSAL Node gives you an interface to help you write such logic. This interface can be seen here:
interface ICachePlugin {
beforeCacheAccess:
(tokenCacheContext: TokenCacheContext) => Promise<void>;
afterCacheAccess:
(tokenCacheContext: TokenCacheContext) => Promise<void>;
}
For public client applications, such as electron apps, Microsoft provides MSAL Node extensions to facilitate this for you. For web applications, MSAL Node includes a DistributedCachePlugin class that implements the above ICachePlugin interface and a partition manager that helps you separate out cache for users by their session IDs.
For MSAL.NET, there are three extension methods available.
The first is AddInMemoryTokenCaches, which gives you in-memory cache that's super-fast, limited to one server's memory, and you lose it when the server restarts. This is great for sample apps or simple apps. Here is how you use it.
services.AddAuthentication(OpenIdConnectDefaults.AuthenticationScheme)
.AddMicrosoftIdentityWebApp(Configuration)
.EnableTokenAcquisitionToCallDownstreamApi(
new string[] { scopesToRequest })
.AddInMemoryTokenCaches();
The second is the AddSessionTokenCaches method, which is token cache that's bound to a user's session. Use this when you want to maintain a user-level cache. You can imagine that this won't scale because its size is a multiplication of the number of users and the size of the token. To use it, you can use this code snippet.
services.AddAuthentication(OpenIdConnectDefaults.AuthenticationScheme)
.AddMicrosoftIdentityWebApp(Configuration)
.EnableTokenAcquisitionToCallDownstreamApi(
new string[] { scopesToRequest })
.AddSessionTokenCaches();
And finally, for most real-world applications, you use the AddDistributedTokenCaches method. You can use it as shown below:
services.AddAuthentication(OpenIdConnectDefaults.AuthenticationScheme)
.AddMicrosoftIdentityWebApp(Configuration)
.EnableTokenAcquisitionToCallDownstreamApi(
new string[] { scopesToRequest })
.AddDistributedTokenCaches();
Distributed token cache requires you to further configure the cache to your liking. For instance, you can choose to use one of four cache implementations.
You can use in-memory by using the next code snippet. This is great for development but not suitable for production. It lets you test distributed memory cache on your developer workstation while flipping over to a better mechanism in production easily.
services.AddDistributedMemoryCache();
You can choose to use Redis, as shown below.
services.AddStackExchangeRedisCache(options =>
{
options.Configuration = "localhost";
options.InstanceName = "SampleInstance";
});
Alternatively, you can use similar implementations for cache backed by SQL server and Cosmos DB also. The Cosmos DB cache is especially interesting because Cosmos DB opens up a number of possibilities when it comes to tweaking global availability in a store of your choice with a consistency of your choice.
Note that when using distributed cache, you get an L1 cache that's in-memory and an L2 cache that is distributed/on disk. Each of these caching mechanisms let you configure how an L1 cache behaves with respect to L1 cache size, encryption, and eviction policies. Here's a code snippet that shows you how to configure these.
services.Configure<
MsalDistributedTokenCacheAdapterOptions>(
options =>
{
options.DisableL1Cache = false;
options.L1CacheOptions.SizeLimit = 1024 * 1024 * 1024;
options.Encrypt = false;
options.SlidingExpiration = TimeSpan.FromHours(1);
});
You can choose to completely disable L1 cache. This isn't a great idea in production because you'll pay a penalty for a server hop. It can be a real godsend when it comes to debugging problems. Caches, as nice as they are, can create massive debugging hassles in production systems. I like to keep this specific property easily configurable in production. Paired with Kubernetes and good devops practices, you can separate out a section of production traffic and turn cache off to diagnose problems.
You can set a maximum size of your L1 cache. You need to do this because you don't want the web server's memory to get overrun by this cache. As soon as you do this, the next problem arises, which is how eviction is handled, that is, who gets to stay within the 1GB cache you set up above. That is where the SlidingExpiration property comes into use.
You can choose to encrypt the cache and should always do so in production.
Although those of us who are caching experts will readily identify that there are well-baked caching strategies in software engineering, and you're more than welcome to use those. Just write your own extension method and implement what works best for you. In most applications, I'm thankful that the above caching options suffices for most needs I've come across.
Summary
The hardest thing about writing articles around identity is the permutations and combinations the modern identity world throws at you. As I write through the concerns of something as simple as writing a Web API that accepts authenticated requests, there are still numerous concerns that I didn't manage to discuss. Those concerns aren't outlier scenarios, they are something you deal with very commonly in your applications.
And then there's the issue of platforms, OIDC flows, languages, SDK support, etc.
I think we can all agree to not reinvent the wheel. If you see your application architecture using a home-grown mechanism, undoubtedly, you'll spot some of the common concerns and problems for which the world has already built a bridge and gotten past. Use that to your benefit. Sticking with a standard not only is more secure, it's also less work for your organization.
What do you think? Should I rename the title of this article to “How to Validate an Access Token”? I'm still on the fence.
Happy coding, until next time!
